前言
前言
上大学的时候,为了能在宿舍电脑之间架个局域网打“红色警戒”,硬着头皮自己去买网卡、同轴电缆、集线器、双绞线。那个时候上网还很困难,网络知识的资料非常少。那个时候的网卡附带的说明书,上面记载了双绞线的排布方法,当时的我一直收藏着这只有一页的说明书,如获至宝。时隔多年,现在网上的资料非常多了,但是网络知识的入门教程,特别是可以立刻动手尝试一下的教程,还是不很多。所以我想从我自己的学习过程作为依据,整理一下整个知识体系,帮助后来者减少中间走的弯路。
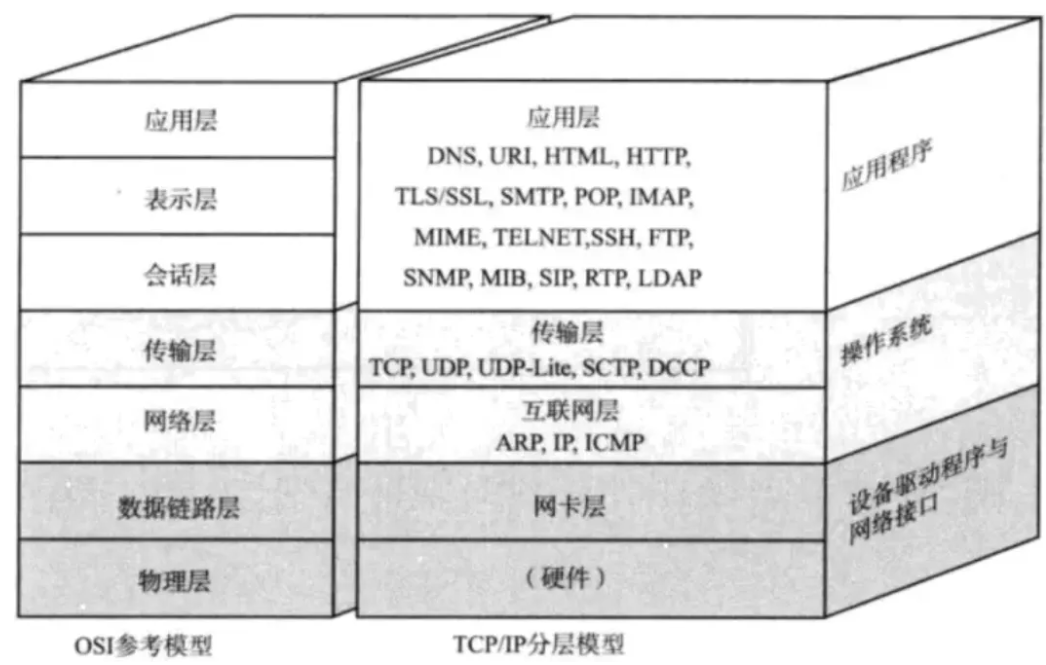 网络的 7 层模型
网络的 7 层模型
很多介绍网络知识的书籍,一上来就会给出上面这个图,初学者一看就懵逼了,这里面的字眼,没一个是知道啥意思的。所以我希望通过大家日常使用的软件,来一一介绍,希望看完本文,最后再回过头看这个图,能理解这个图是啥意思。我会根据这个图,从上往下来介绍。
浏览器和网站
浏览器和网站
我们日常使用网络最常见的过程,就是打开一个浏览器,然后输入一个网址。我们可以通过稍微深入一点点的去观察这个过程,来学习一部分网络知识。这次我们可以学到以下技术的关系:
HTTP\MIME\HTML
让我们用 Chrome 浏览器在电脑上打开一个网站,但在此之前,稍微做一点点准备。我们需要先打开浏览器的“开发者工具”:右上角三个点 → 更多工具 → 开发者工具。
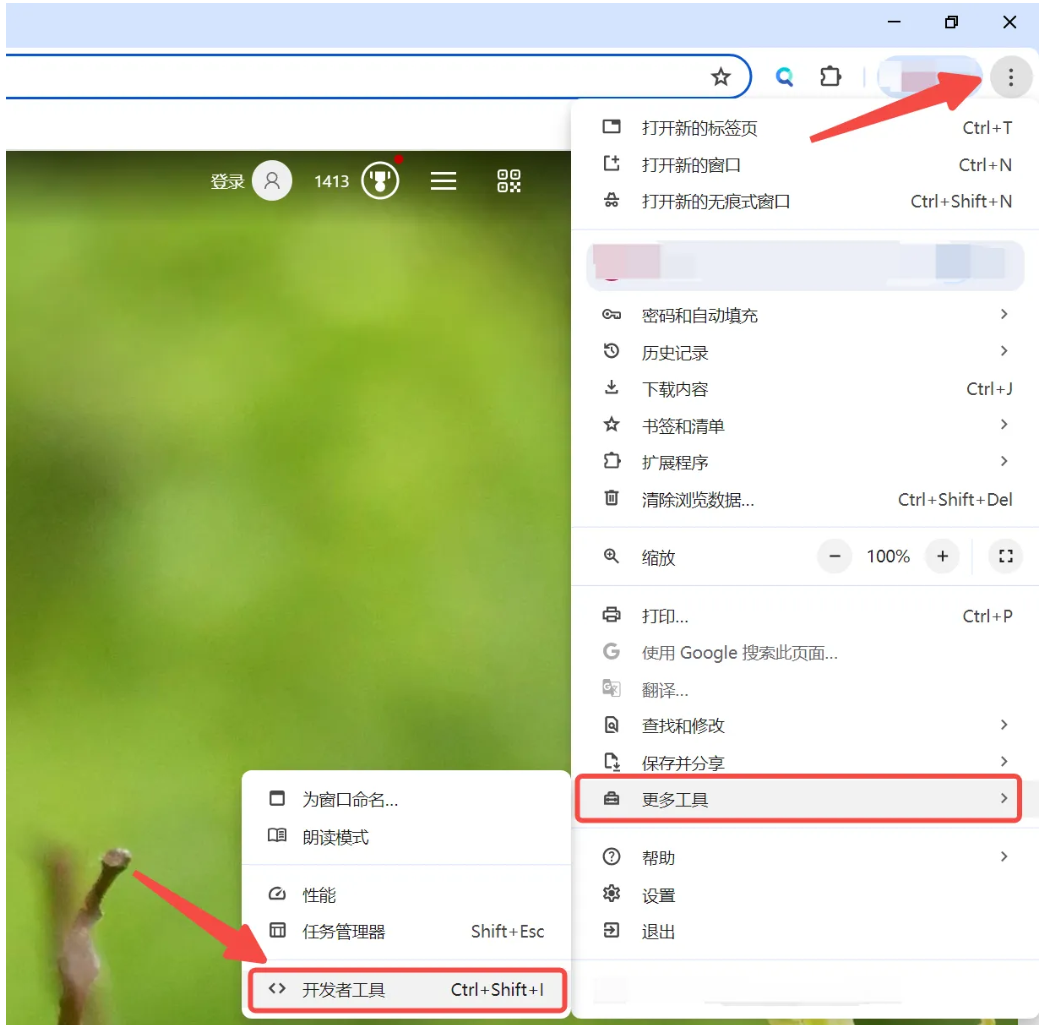 打开“开发者工具”
打开“开发者工具”
在打开的窗口中,找到Network标签,需要注意看一下,左边是否有一个红色的圈圈里面有一个红色的正方形。这个状态表示“开发者工具”会记录从网络上首发的数据原文,也是我们得以探索网络知识的来源。
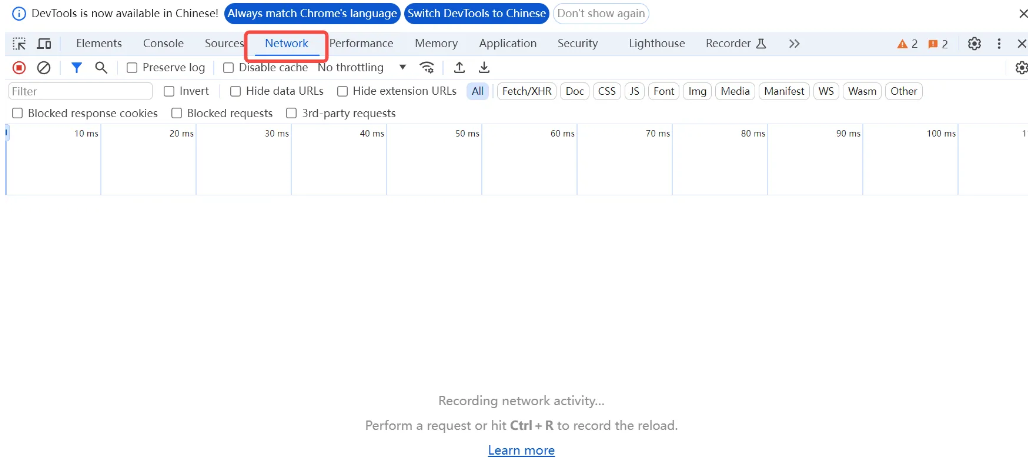 Network 标签页
Network 标签页
现在在浏览器的地址栏输入这个地址:https://www.lua.org/,这是我在网上找的一个相对简单的页面,以便观察学习用。
 浏览器页面显示内容
浏览器页面显示内容
 开发者工具显示内容
开发者工具显示内容
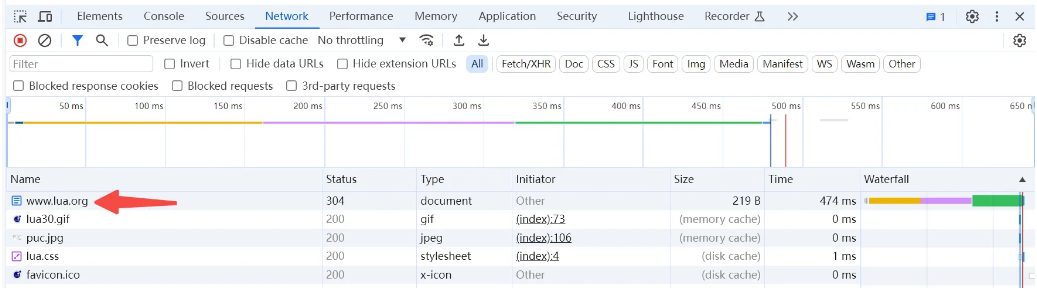
你应该能看到以上两个图的内容。一个是日常浏览器我们常见的显示内容;另外一个开发者工具中,会显示打开本次网站,网络上到底发生了什么事情的信息——浏览器从网站上下载了好几个文件:
- www.lua.org:这是一个 HTML 的文档,包含了这个页面的文字内容和整体图文排版
- lua30.gif:这是页面中左边蓝色写着“Lua”的那个图片
- puc.jpg:页面右边灰色的写着“PUC”的图片
- lua.css:一个控制页面字体等格式的文件
- favicon.ico:出现在浏览器标签页左边的图标
在上面的表格里面,还记录了下载的耗时、下载的文件的大小。譬如www.lua.org这个页面,下载的大小就是 219 个字节,耗时 474 毫秒。现在我们知道了浏览器打开页面,是会下载几个文件的,但是具体是怎么下载的呢?我们可以进一步深入探索一下。
 点击具体一个下载的文件
点击具体一个下载的文件
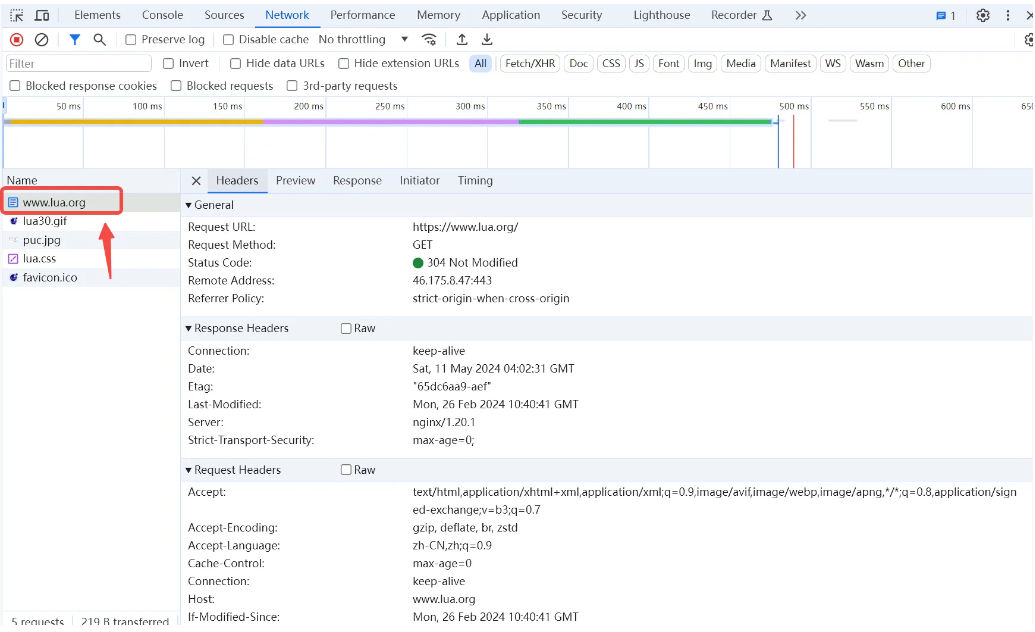
我们点击一下www.lua.org,可以看到右面出现了一个窗口,上面分为 Headers/Preview/Response 等分页。其中 Headers 分页,就包含了“如何下载文件”的信息,而这套下载文件的方法,有一个特别的名字,称为 HTTP (Hypertext Transfer Protocol),分页这里的 Headers 指的正是 HTTP 协议中的“头部信息”,这些信息详细描述了下载一个文件的方法。为了更清晰的看到这个过程,我们需要把Response Headers和Request Headers旁边两个Raw的框框勾选上,查看最原始的网络报文。
当我们在浏览器的地址栏输入一个网址后,浏览器就会向网站服务器发出一个请求,请求的内容就是这里Request Headers所显示的内容。这些内容完全就是以文本形式(和你用记事本里面写的文字的格式一样),一行行的组织起来,发给服务器。
 HTTP 请求 Header
HTTP 请求 Header
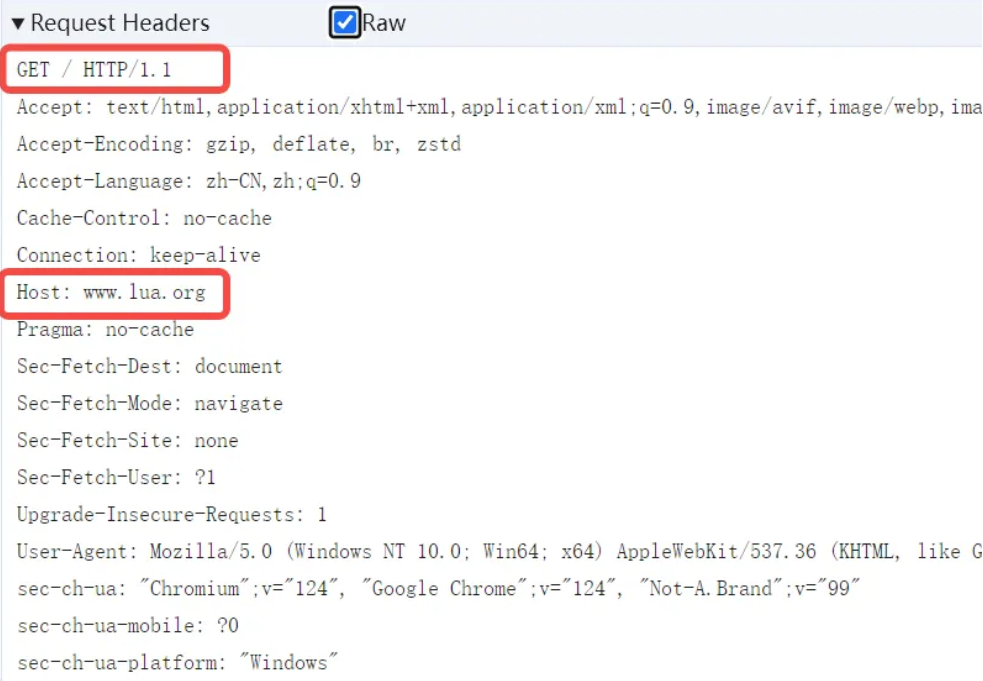
需要注意的有以下两行:
- GET / HTTP/1.1 这一行表示需要下载一个路径为 "/" 的文件。如果我们输入的地址是 www.lug.org/index.html,那么这里发送的请求将会是 GET /index.html HTTP/1.1
- Host: www.lua.org 这一行表示我们请求的网站域名是 www.lua.org,这个是在地址栏输入来确定的。(由于一个网站服务器可以承担多个域名的请求,所以请求的具体哪个域名,是需要明确的在请求报文中写出来的)
对于服务器网站的返回,是比较复杂的。这种返回一般分为“头部”(Header)和“身体”(Body)两个部分,“头部”是纯文本的,一行行的发回来;“身体”则是跟具体下载的文件内容有关。现在我们请求的是一个网站页面,所以也是文本的。
 HTTP 响应 Header
HTTP 响应 Header
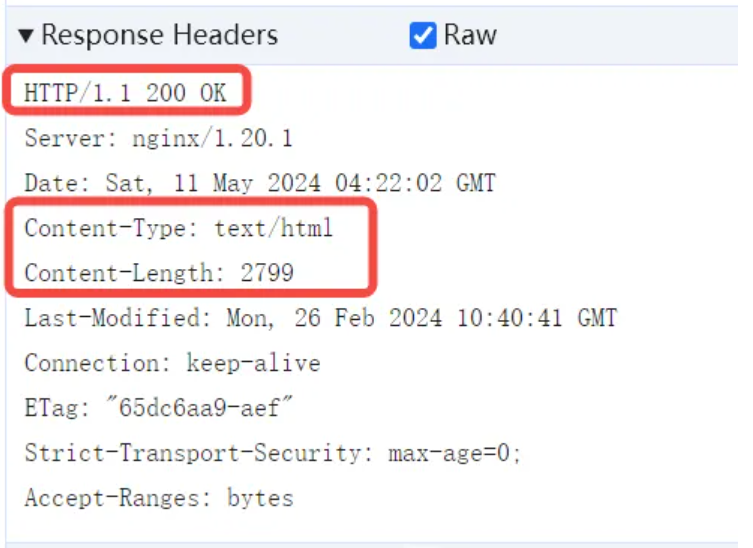
响应的 Header 表示了下载文件的情况、类型、大小:
- HTTP/1.1 200 OK:这里的 200 被成为“响应码”,代表这次下载是否成功,200 这个数字就是成功的意思。另外一个广为人知的响应码是 404,表示你要下载的文件在服务器上找不到。(可能是网页文件被删除了,但是指向这个页面的链接还在)当然还有很多其他的响应码,譬如 500 表示服务器程序出错了,304 表示有缓存等等……
- Content-Type: text/html:这个表示本次下载的文件内容的类型,浏览器是一个强大的软件,支持显示各种格式的文件,除了 html 格式网页以外,也支持多种图片、音乐、视频等等,如果服务器返回了一个浏览器不认识的格式,譬如 application/unknown 之类的,浏览器会提示用户是否要“下载这个文件”,让用户自己找其他程序去打开这个文件。当然我们这里的例子,是一个页面,text 是主类型,表示是文本文件,html 是子类型,表示是一个网页。
- Content-Length: 2799:这个表示下载的文件的长度,2799 表示需要 2799 字节。由于网络下载是需要时间的,所以浏览器会一直等待,从网络上下载了 2799 字节的数据之后,才认为这个文件下载完成了,否则浏览器的地址栏会一直有一个“转圈”的图标表示正在下载。
除了上面提到的 Header 以外,其他的 Header 也各自有不同的功能,这些功能很多是不会被显示在网页内容上的,但也是非常重要的。
下面我们来看看响应的“身体”部分:
 响应的 Body
响应的 Body
这部分内容是一个文本文件,以 HTML 这种格式编写的网页。这些文本会确定网页要显示什么内容,里面也会包含其他网页的跳转链接,还有图片的链接等等。浏览器读取到图片的链接的时候,就会再次向服务器发起一次下载请求。因此我们才看到除了 www.lua.org 的下载记录以外,还有 lua30.gif 和 puc.jpg 的下载记录。我们可以看到下载图片的地址写的是 images/lua30.gif 和 images/puc.jpg。我们还可以看一下这两个文件的下载记录,可以看到和上述类似的过程。
 下载图片的 Header
下载图片的 Header
下载的图片也可以在开发者工具查看到:
 下载文件的预览
下载文件的预览
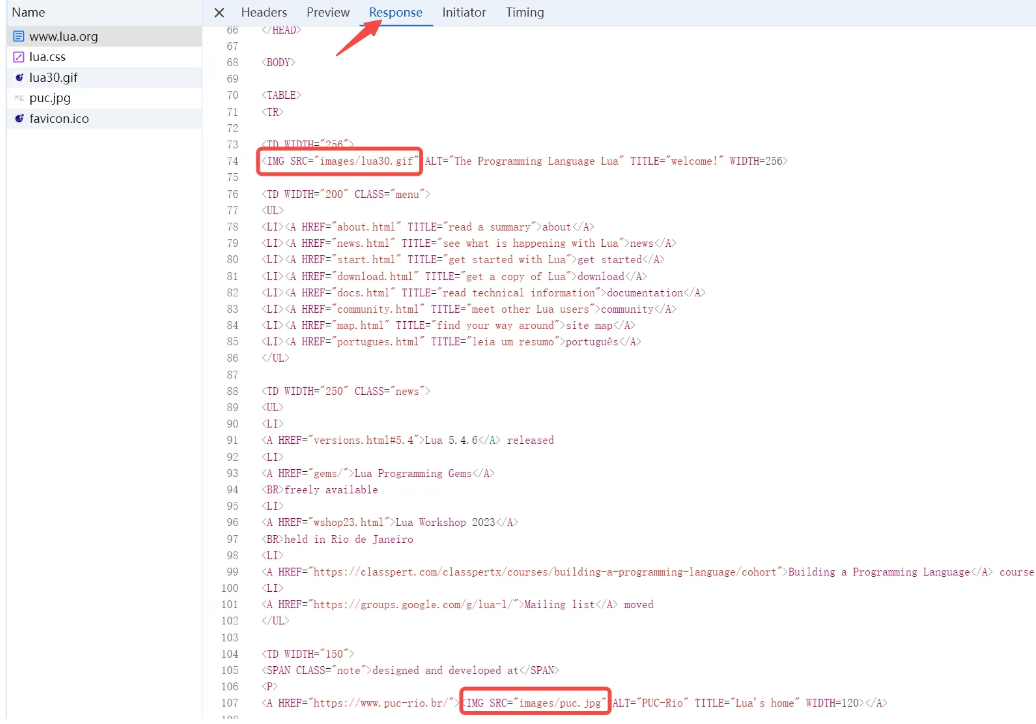
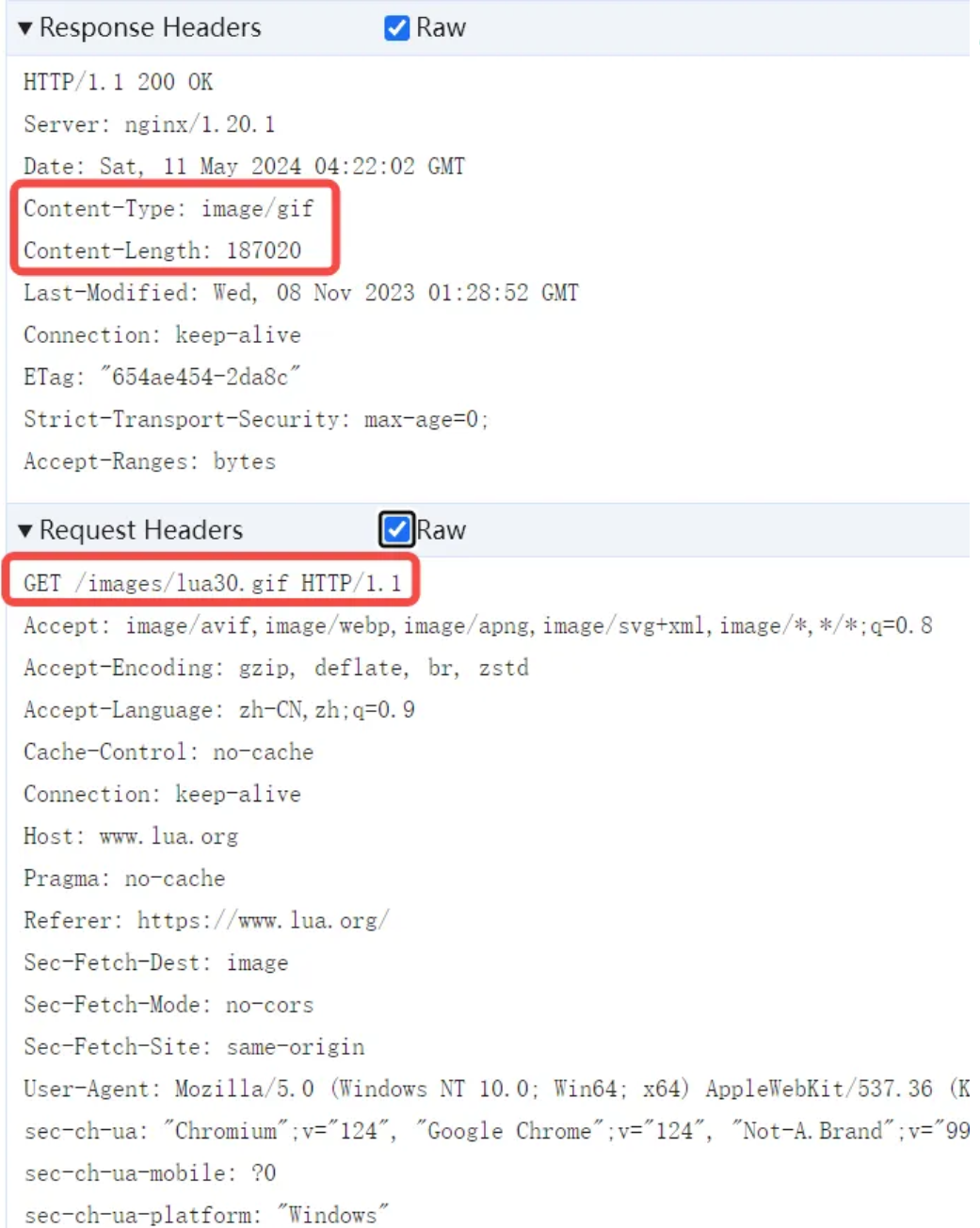
从 Header 里面看到 GET /images/lua30.gif HTTP/1.1 里面的文件路径,和之前 HTML 中写的图片地址 <IMG SRC="images/lua30.gif ...>的文件路径一致。而响应的 Header 中,用image/gif来告诉浏览器,这个文件的主类型是 image,子类型是 gif。浏览器就根据这个类型信息来决定如何处理,在这里就是显示这个图片。决定浏览器如何显示文件的指令,并不是根据文件名的后缀 .gif,而是根据响应的 Content-Type 的 Header 的内容。根据响应 Header 中的 Content-Length: 187020,浏览器会下载后续的 187020 个字节的数据,作为 gif 格式图片的内容,然后显示这个图片。
对于 Content-Type 的内容,有一个专门的术语来代表:MIME(Multipurpose Internet Mail Extensions),意思是多用途互联网邮件扩展。这套描述数据内容格式的标准,同时也在电子邮件系统中使用,我们可以在电子邮件中插入各种格式的文件附件。
至此,我们大体的了解了 HTTP 协议的内容。总结一下,就是:
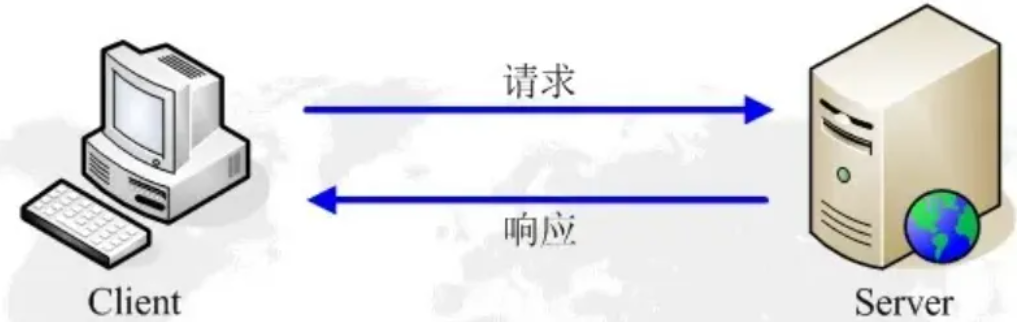
- 浏览器和网站服务器是通过一个请求,对应一个响应进行通信的。不同于 QQ、微信、网络游戏这类软件,它们可以同时进行数据的收、发,而无需请求后等待一个响应。
- 请求和响应都由一系列的文本文字,一行行的组成 Header 部分,用于指定要下载的文件,以及返回文件的类型、大小。Header 还被用于其他很多功能,譬如缓存控制、Cookies 跟踪等等。
- 响应的 Body 部分直接是下载文件的数据内容,很多时候并没有进行其他编码。最常见的是文本的 HTML 内容。
 请求-响应 模式
请求-响应 模式
但是,我们还有一个问题没有提及,就是我们去请求的网站服务器,到底是一个什么东西?为什么输入一个域名,就可以联系到一个具体的网站服务器了呢?
这个问题下篇介绍,由此我们可以进入 TCP/IP 的世界。