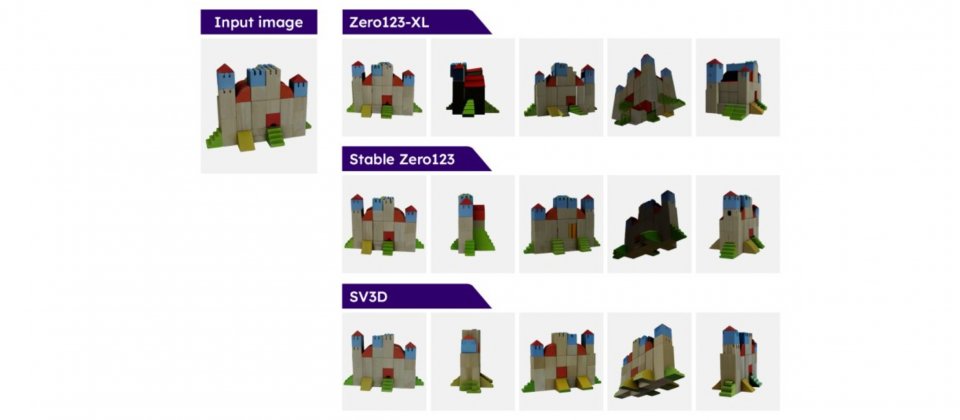
Stability AI以Stable Video Diffusion模型为基础,创建了Stable Video 3D(SV3D)模型,SV3D可生成高品质的3D多视角影片,官方提到,相较之前所发布的Stable Zero123模型,SV3D生成的影片品质以及多视角表现都更好,效能也优于Zero123-XL。
Stable Video 3D模型有两个变体,分别是SV3D_u和SV3D_p。SV3D_u能够利用单一图像,不需要使用者设定摄影机参数,即可生成环绕物体的连续视角(Orbital Views)影片,而SV3D_p则是在SV3D_u基础上,不仅支援从单一图像生成影片,还能根据环绕物体的影片,生成指定摄影机路径的3D影片。
Stability AI调整原有的Stable Video Diffusion图像转影片模型,增加摄影机路径设定功能,使Stable Video 3D模型能够生成从不同角度观看物体的影片。与Stable Zero123所使用的扩散模型相比,Stable Video 3D在生成影片方面拥有更好的泛化能力以及视角一致性,因此所生成的影片,从不同视角看起来更加自然且连贯。
Stable Video 3D还采用了解耦光照最佳化(Disentangled Illumination Optimization)技术,使得模型可单独调整照明效果,不影响场景其他元素表现,以及透过遮罩分数蒸馏采样损失函式(Masked Score Distillation Sampling Loss),来维持生成物体的品质和一致性。
官方指出,Stable Video 3D在3D影片生成有重大进步,因为先前的方法在视角通常受限制,且输出有物体不一致的问题。而Stable Video 3D却可从任意指定视角,输出连贯的视图,不仅强化姿势可控性,也确保可在多个视图中保持物体外观一致。
Stable Video 3D现在推出,Stability AI会员可将其用于商业目的,针对非商业用途,开发者可以在Hugging Face下载模型权重,并参照Stability AI的研究论文。