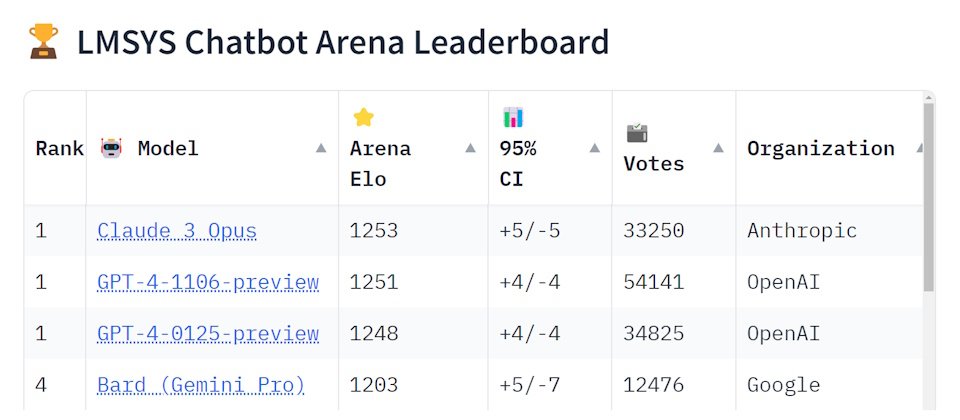
就在这几天,专门盲测大型语言模型(LLM)能力的LMSYS Chatbot Arena排行榜出现了变化,由Anthropic所打造的Claude 3 Opus模型挤下了OpenAI的GPT-4,成为该排行榜上等级最高的LLM。
LMSYS Chatbot Arena是由研究组织Large Model Systems Organization在去年5月所发表,为一采用Elo评分系统的平台,Elo评分系统可用来计算参与者的相对技能,最初是为了改善西洋棋的评分系统而设计,之后则被应用在足球、棒球、篮球、桌球、各种棋盘游戏,以及最近的大型语言模型;而LMSYS Chatbot Arena则是个开放且众包的盲测排行榜,支援75种大型语言模型,使用者可于网页上输入各种提示,以查看两个随机选择的模型所提供的答案,系统并未揭露生成答案的模型,并由使用者评断答案的优劣,亦可选择平手或两个答案都不好。
自LMSYS Chatbot Arena排行榜于去年5月上线以来,评分最高的大型语言模型一直是GPT,但Claude 3 Opus在本周挤下了GPT--4-1106-preview(去年11月释出的GPT-4 Turbo)与GPT-4-0125-preview(今年1月释出的GPT-4 Turbo)。
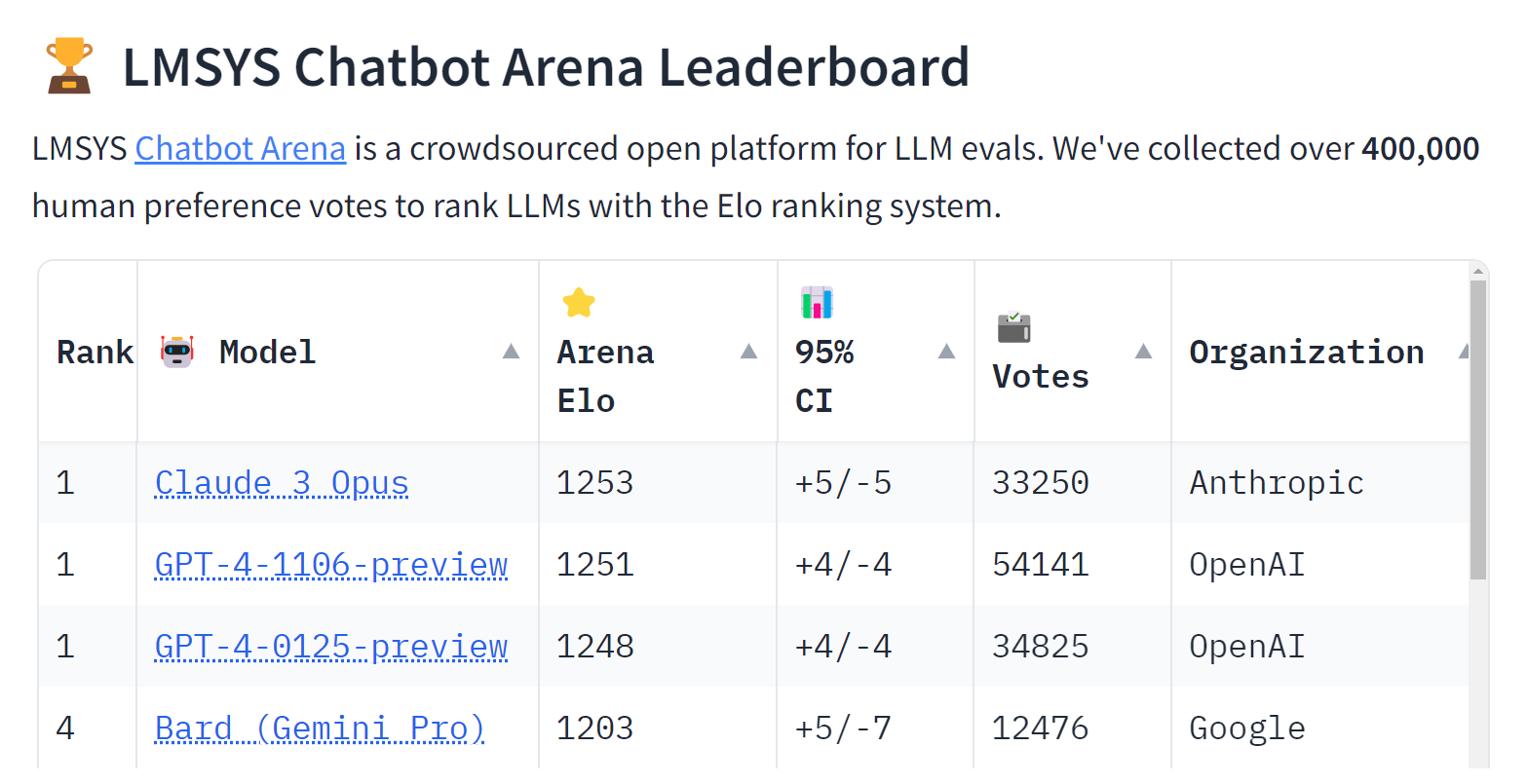
Anthropic是在今年3月发表Claude 3系列的模型家族,涵盖最低阶的Claude 3 Haiku、中阶的Claude 3 Sonnet,以及最强大的Claude 3 Opus,除了Claude 3 Opus位居LMSYS Chatbot Arena排行榜冠军之外,中阶的Sonnet与低阶的Haiku也都在前十名的榜单上。
由曾担任OpenAI研究副总裁的Dario Amodei,以及其妹妹、同样身为OpenAI资深员工的Daniela Amodei在2021年共同创立的Anthropic,被视为是OpenAI目前最强劲的对手,锁定资料科学、机器学习与AI的内容网站KDnuggets认为,Anthropic所发表的Claude 3在所有LLM基准测试中都优于GPT-4和Gemini Ultra,已是AI领域新的领导者。
在Reddit平台有关GPT-4 Turbo与Claude 3 Opus的讨论中,多数人赞成Claude 3 Opus的写作与处理文章的能力胜过GPT-4 Turbo,有人说GPT-4 Turbo对复杂问题的处理能力优于Claude 3 Opus,亦有人觉得Claude 3 Opus所生成的程式码品质与GPT-4 Turbo相当,但更人性化。