题主,如果你只看重数量的话,我可以用4行核心代码教你在20分钟里面就可以挖出8000个因子,后面你想挖多少就挖多少,一晚上挖12万都不在话下。
这里就要提到一个非常牛掰的时序数据特征自动化提取神器——tsfresh!

tsfresh实际上是一个python库,在电脑终端使用“pip install tsfresh”就可以自动安装,它最主要的功能就是能对证券价格这类型的时间序列数据自动挖掘其中的特征,并且还可以对有效特征进行筛选,详细说明请见官网:https://tsfresh.com/。
特征(feature)一般是在人工智能/机器学习/深度学习领域的叫法,在量化交易/量化投资领域一般叫因子(factor),例如相对强弱指标RSI在机器学习领域就叫RSI特征,在量化选股领域就叫RSI因子,其实都是一样的东西,大伙儿注意分辨语境就好了。
使用tsfresh,“20分钟挖掘8000个因子”并不是吹牛,咱可以先来快速体验一下,详细原理下文再细说,在成功安装tsfresh库后,只需要以下4行核心代码(第5~8行),便可以将原有的11个基础因子,扩展到8613个因子,超额完成任务,耗时953秒,约16分钟。如果你再塞进77个因子,6万个因子就唾手可得了。
import datetime
start_time = datetime.datetime.now() #开始时间
# 核心代码部分
from tsfresh import extract_features
from tsfresh.utilities.dataframe_functions import roll_time_series
data_roll = roll_time_series(data, column_id='code', column_sort='date', max_timeshift=20, min_timeshift=5).drop(columns=['code'])
data_feat = extract_features(data_roll, column_id='id', column_sort='date')
end_time = datetime.datetime.now() #结束时间
print('开始时间:', start_time.strftime('%Y-%m-%d %H:%M:%S'))
print('结束时间:', end_time.strftime('%Y-%m-%d %H:%M:%S'))
print('耗时:%d 秒' %(end_time-start_time).seconds)
print('原始数据维度:', data.shape)
print('特征提取后维度:', data_feat.shape)
输出结果:
开始时间: 2023-03-25 20:19:29
结束时间: 2023-03-25 20:35:23
耗时:953 秒
原始数据维度: (4334, 13)
特征提取后维度: (4329, 8613)
补充说明一下,其中输入数据data是预先生成的数据(下文会说明获取方式),第1列是日期(date),第2列是证券代码(code),之后的11列都是因子列;特征提取之后行数少了5行,是因为设置了前面至少要有5行数据才开始提取当日特征;耗时大小跟电脑配置有关,本次试验所用的电脑处理器是第12代i7(主频2.10 GHz),电脑内存大小是16G。
咱不能是为了提取因子而提取因子,必定是用来做些什么的吧,那咱就可以沿着之前机器学习指数量化择时的策略思路,构建一个因子增强版的策略,整体策略思路详见之前的文章《手把手教你,利用机器学习模型,构建量化择时策略》。
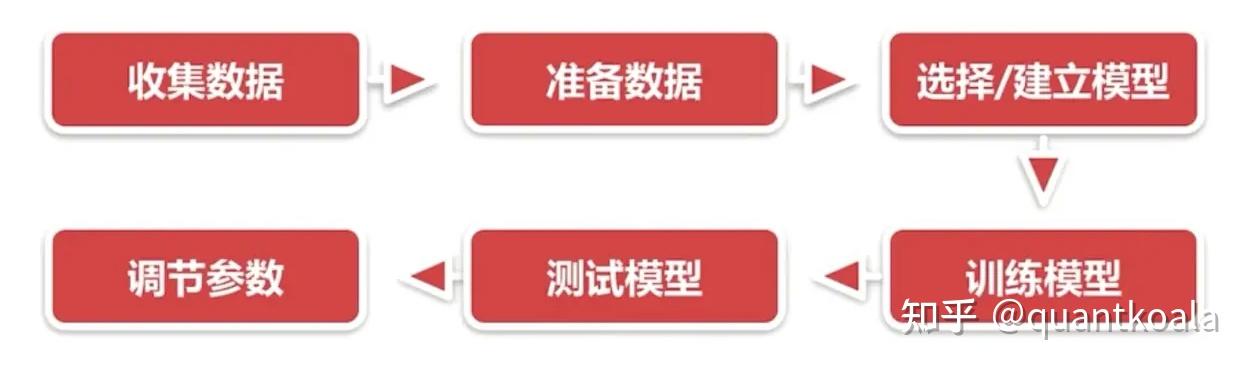
整个建模流程分为收集数据、准备数据、选择/建立模型、训练模型、测试模型和调节参数这6大步骤,这次咱主要是利用tsfresh库生成更多的有效因子进行建模,因此只需改变收集数据和准备数据这2个步骤,后面4个步骤与之前的文章基本一致,无须大变。
Step1:收集数据
现在开始第1个步骤,咱就来获取沪深300指数从2005年4月8日上市以来至今的全部行情数据,这里使用的是股票量化开源库qstock,“pip install qstock”安装后,基本的功能无需注册便可以使用,对萌新来说非常方便,详情请见:https://github.com/tkfy920/qstock
import qstock as qs
# 获取沪深300指数高开低收、成交量、成交金额、换手率数据,index是日期
data = qs.get_data(code_list=['HS300'], start='20050408', end='20230324', freq='d')
# 删除名称列、排序并去除空值
data = data.drop(columns=['name']).sort_index().fillna(method='ffill').dropna()
# 插入日期列
data.insert(0, 'date', data.index)
# 将日期从datetime格式转换为str格式
data['date'] = data['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
data = data.reset_index(drop=True)
print(data.shape)
data.tail(10)
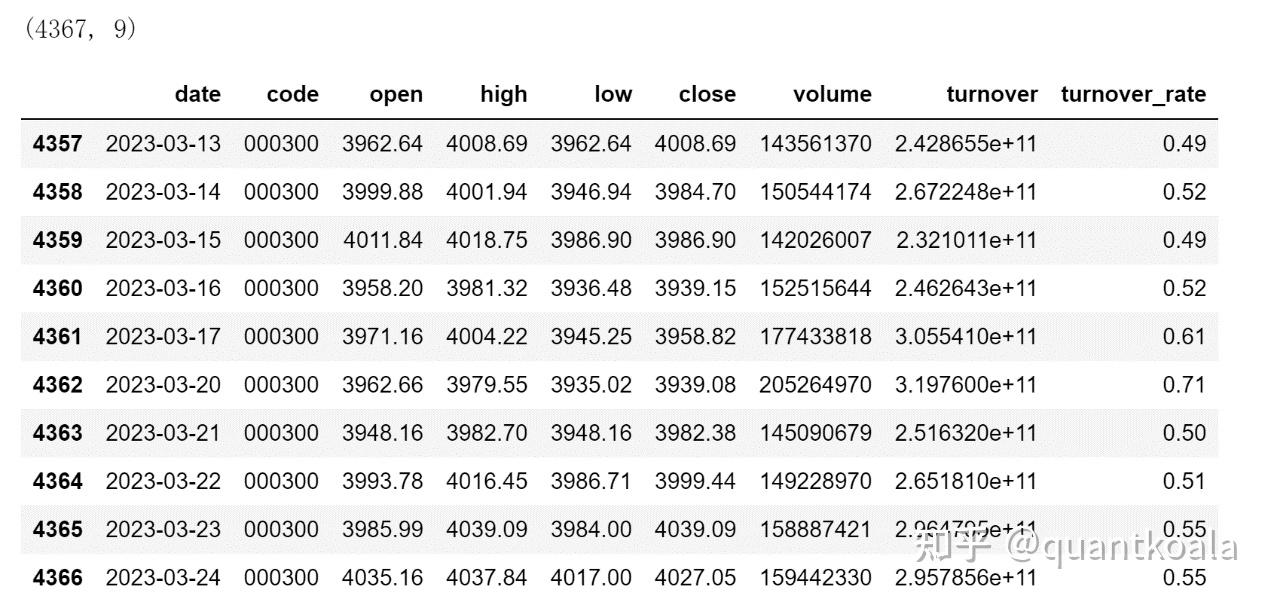
这里使用qstock获取数据只是举例,大家使用相同功能的库或API都可以,要注意的是不要带名称列,而且日期列是str格式,不是datetime格式。
Step2:准备数据(本期重点)
第2个步骤就是准备数据,生成/选取哪些特征/因子作为将来SVM模型的输入,在这里咱额外计算的因子是价格斜率(slope)、相对强弱指标(rsi)、威廉指标值(wr)、MACD快线(dif)、MACD慢线(dea)、MACD柱(macd)和抛物线指标(sar)这7个因子,再加上之前的收盘价、成交量、成交金额和换手率,一共是11个因子。
import talib
# 收盘价的斜率
data['slope'] = talib.LINEARREG_SLOPE(data['close'].values, timeperiod=5)
# 相对强弱指标
data['rsi'] = talib.RSI(data['close'].values, timeperiod = 14)
# 威廉指标值
data['wr'] = talib.WILLR(data['high'].values, data['low'].values, data['close'].values, timeperiod=7)
# MACD中的DIF、DEA和MACD柱
data['dif'], data['dea'], data['macd'] = talib.MACD(data['close'].values, fastperiod=12, slowperiod=26, signalperiod=9)
# 抛物线指标
data['sar'] = talib.SAR(data['high'].values, data['low'].values)
# 删除开盘价、最高价和最低价
data = data.drop(columns=['open','high','low']).fillna(method='ffill').dropna().reset_index(drop=True)
print(data.shape)
data.tail(10)
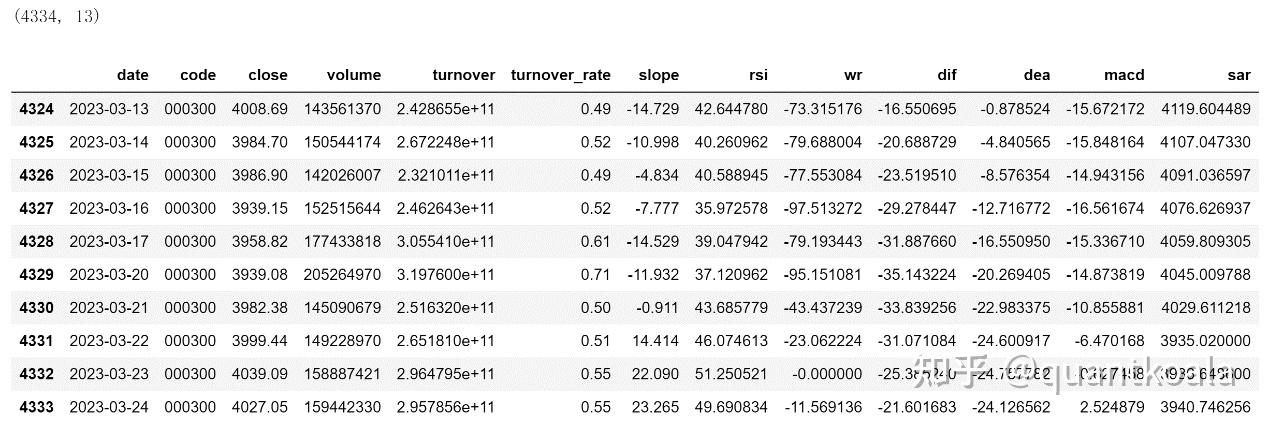
注意这里的行数比之前的少了33(4367->4334),那是因为在计算MACD指标时,底层需要计算EMA26并且在这基础上还要计算EMA9,期初的数据由于长度不足,指标是空值被剔除了,(26-1)+(9-1)=33,下面出现行数减少的原因也是同样的原理,不再赘述。
重点来了,在这里咱要基于这11个基础因子,生成8000+个因子,这里就要先说明一下tsfresh的提取特征原理了。
tsfresh是对序列数据提取特征,输入一个时间序列数据就会转换为一个数值,例如输入一段时间的股价序列,那么可以转化成最大值、最小值、平均值、中位数、波峰数这样的标量数值。
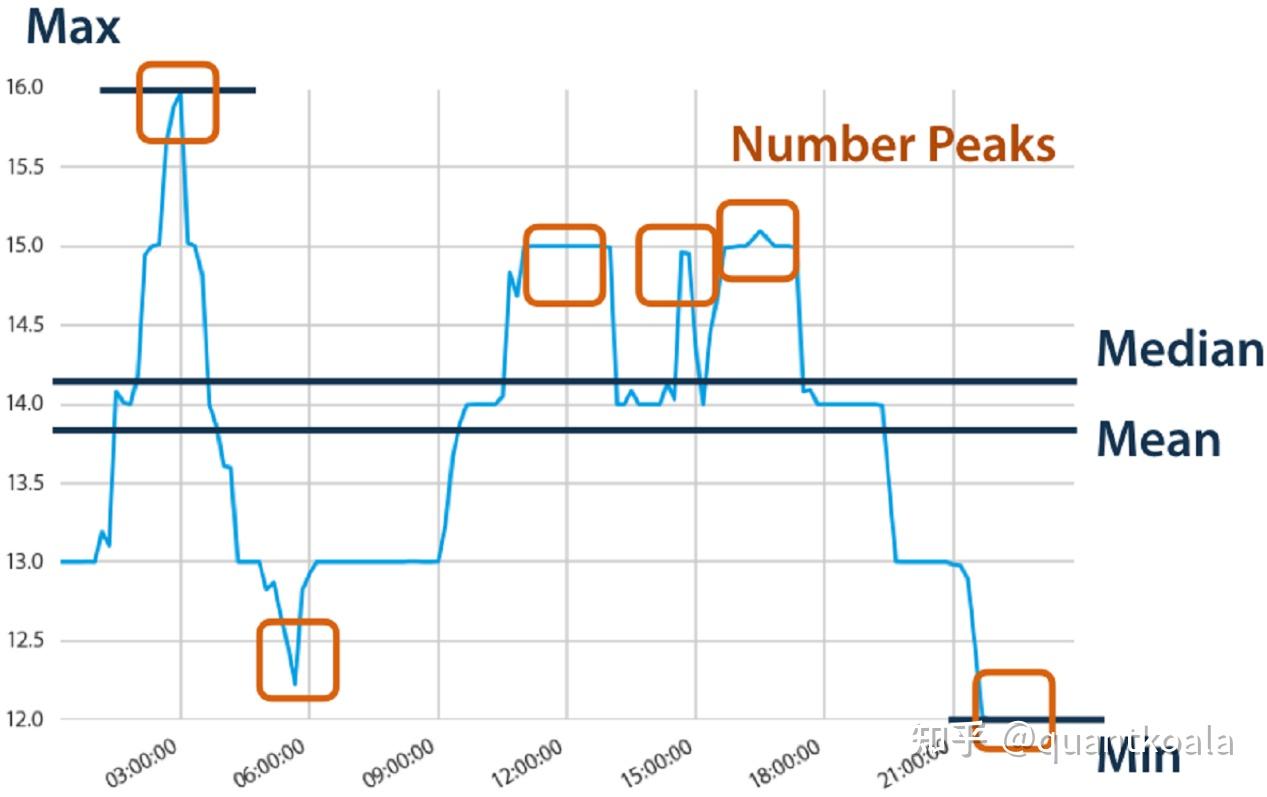
如果不做特殊处理,直接把沪深300因子数据输入进去,那么它只会把每个因子序列数据转化为单个值,这样一个4334x13的因子矩阵,最终就会变为1x13的因子向量,相当于只是一个样本,这样是无法建模的。
咱需要的是每个交易日都要有一个样本,这就需要用到tsfresh的滚动(roll)技术了,请看下面的变换。
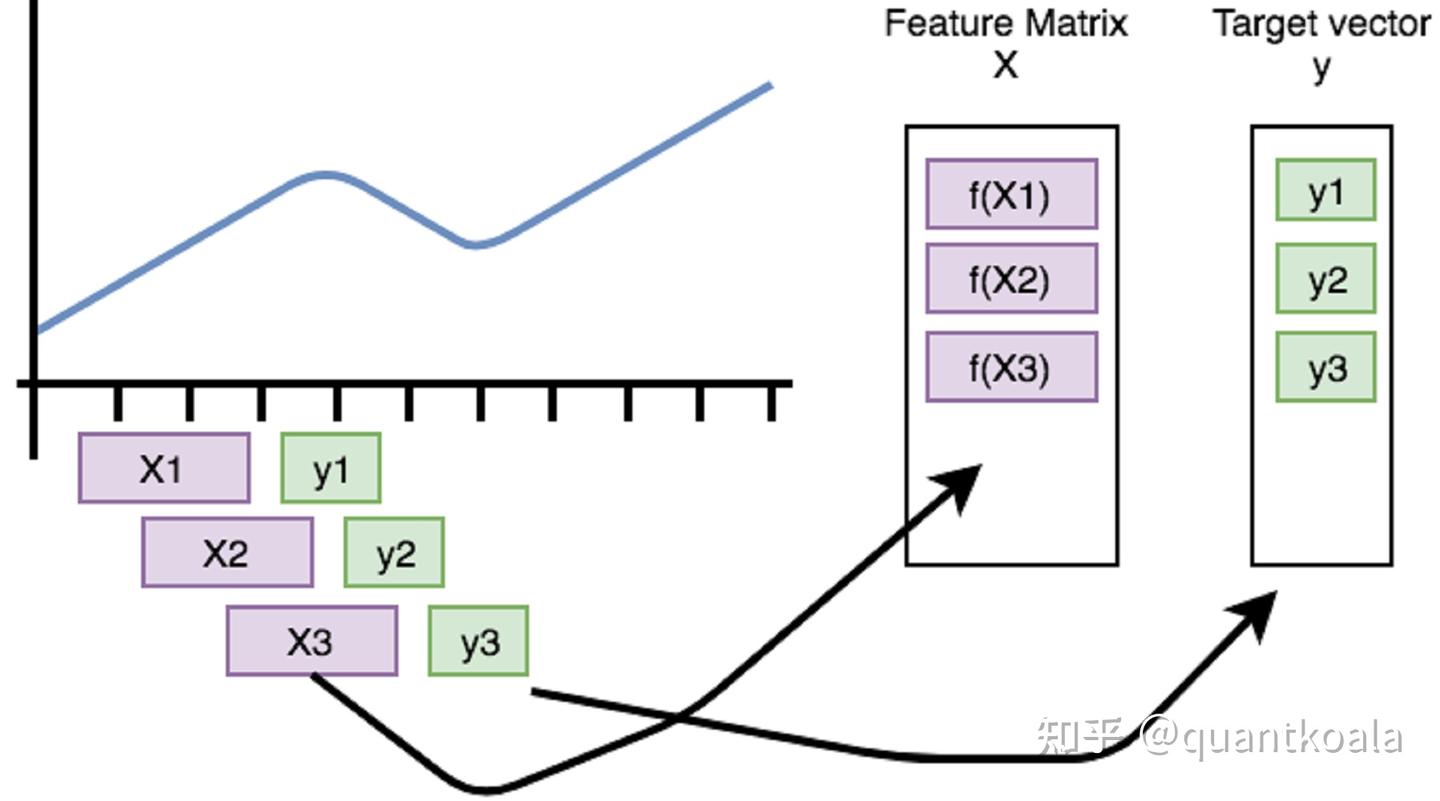
from tsfresh.utilities.dataframe_functions import roll_time_series
data_roll = roll_time_series(data, column_id='code', column_sort='date', max_timeshift=20, min_timeshift=5).drop(columns=['code'])
print(data_roll.shape)
data_roll.head(15)
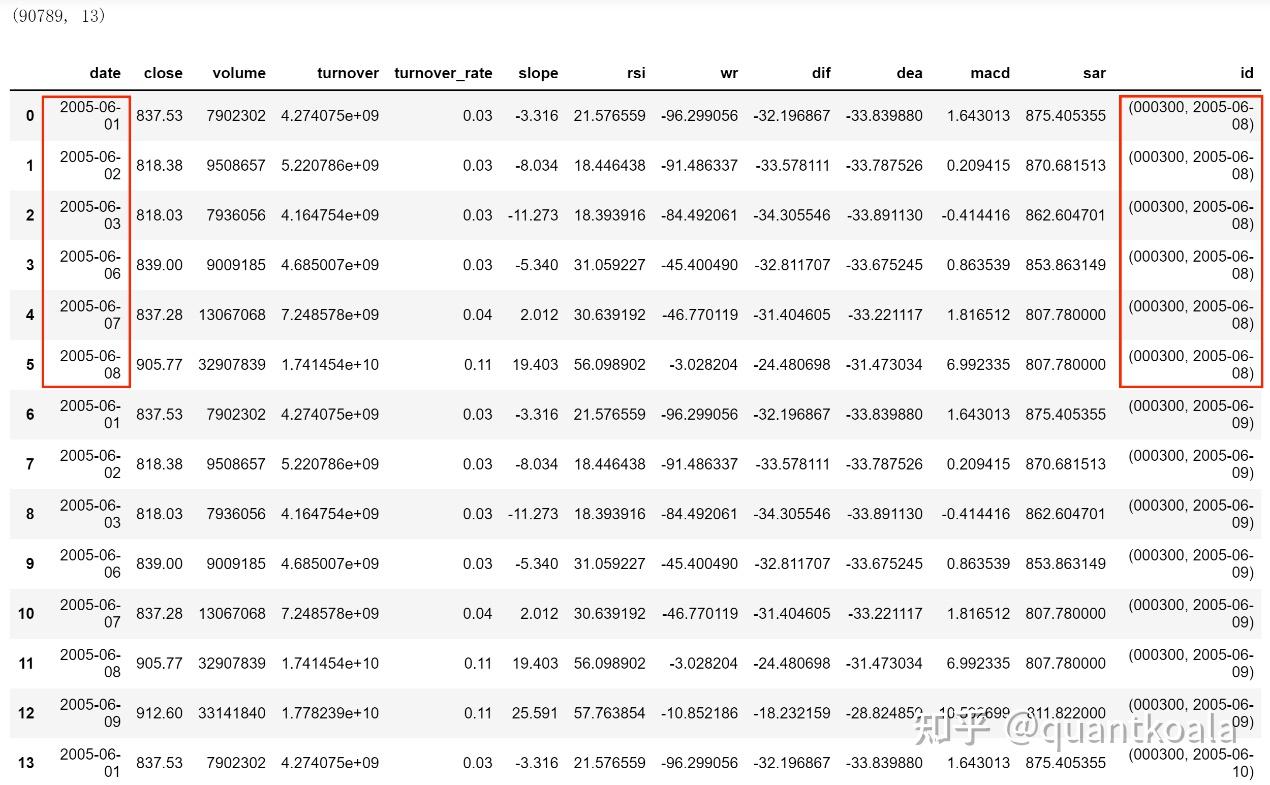
在这个变换中,新生成了一个id列,数值是一个元组,元素1是证券代码,元素2是日期,红框中id日期表明,2005-06-08的因子计算需要用到2005-06-01、2005-06-02、2005-06-03、2005-06-06、2005-06-07和2005-06-08这6个数值组成的时间序列数据,用多长的序列数据,由参数max_timeshift和min_timeshift决定。
max_timeshift=n表示每个交易日最多使用包含当日在内的n+1个数据点序列,min_timeshift=m表示每个交易日至少使用包含当日在内的m+1个数据点序列,这也就说明了数据id为什么从2005-06-08开始,因为之前至少需要5个数据点,再给大伙儿换一种方式展示就清楚更多了,如下。
gg = data_roll.groupby('id').agg({'date':['count', min, max]})
print(gg.shape)
gg.head(20)
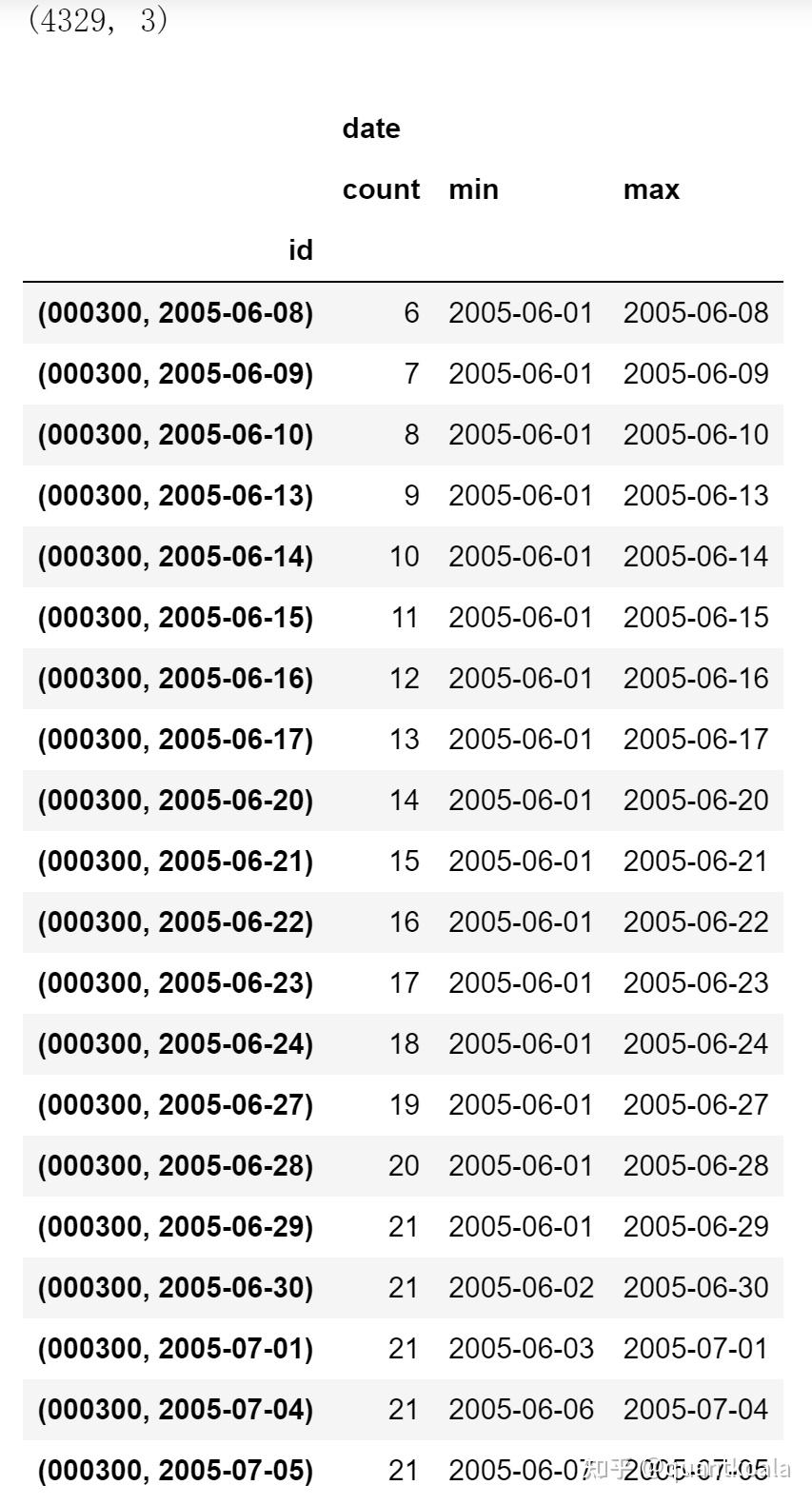
看到这里应该就明白了,数据长度在min_timeshift+1 ~ max_timeshift+1之间时,有多少数据用多少数据,当超出这个范围后,就每个交易日滚动(roll)使用max_timeshift+1个数据点的序列数据,因此原始因子数量不变,但行数被扩展为9万多行,因为部分数据被重复滚动使用。
在data_roll之上,就可以使用tsfresh的extract_features函数在基础因子之上衍生出众多因子,这一步较为耗时,不同电脑配置执行时间不一样,须耐心等待。
from tsfresh import extract_features
data_feat = extract_features(data_roll, column_id='id', column_sort='date')
# 对单独标的而言,将日期作为index
data_feat.index = [v[1] for v in data_feat.index]
print(data_feat.shape)
输出结果:
Feature Extraction: 100%|██████████████████████████████████████████████████████████████| 50/50 [13:11<00:00, 15.83s/it]
(4329, 8613)
从结果中看出,最终得到了4329x8613的因子矩阵,4329对应着交易日数,8613对应着在11个基础因子之上衍生出来的因子数。
因子生成的原理是,tsfresh预置了783个算子(calculator),会逐个用在每一个交易日的基础因子数值序列上,这就相当于孙悟空拔一根猴毛下来,能变出783个形态各异的化身,相同计算公式不同单参数也算1个,11乘以783就是8613,具体的算子计算公式请见官方文档:
https://tsfresh.readthedocs.io/en/latest/text/list_of_features.html
这8613维里面都是衍生出来的因子,是不包含原始的基础因子的,记得也把基础因子添加回去。跟以前的做法一样,也要给每个交易日的数据打上标签,每个样本标签对应的是第二个交易日的涨跌情况,计算出每个样本第二天的涨幅(pct),如果第二天上涨,则设置标签(rise)为1,反之为0。
import pandas as pd
# 将原始因子加入因子矩阵当中
data_feat = pd.merge(data_feat, data.set_index('date', drop=True).drop(columns=['code']),
how='left', left_index=True, right_index=True)
# 给数据打标签
data_feat['pct'] = data_feat['close'].shift(-1) / data_feat['close'] - 1.0
data_feat['rise'] = data_feat['pct'].apply(lambda x: 1 if x>0 else 0)
data_feat = data_feat.dropna(subset=['pct'])
print(data_feat.shape)
Step3:选择/建立模型
还是跟之前一样,使用SVM模型,原因和原理不再赘述,详见之前的文章《手把手教你,利用机器学习模型,构建量化择时策略》,为了方(tou)便(lan)实现和建立模型,咱还是直接从Scikit-learn(简称sklearn)中导入,它是非常流行的Python免费机器学习库,具有各种分类、回归和聚类算法,一般配合numpy数据格式使用。
Step4:训练模型
在这里,咱需要把整个数据集分拆为训练集和测试集,因为除了训练模型之外,咱还要留出一部分数据来验证训练出来模型的优劣。
一般来说,将完整数据集80%的样本作为训练集,剩余20%的样本作为测试集,要注意的是,在这里使用tsfresh的select_features函数对之前的8000+因子进行有效因子筛选,最终有效入选因子有200多个,这个只能在训练集上操作,不能在全部数据集上操作,否则就会变相引入“未来函数”。
from tsfresh import select_features
# 划分训练集和测试集
num_train = round(len(data_feat)*0.8)
data_train = data_feat.iloc[:num_train, :]
y_train = data_feat.iloc[:num_train, :]['rise']
data_test = data_feat.iloc[num_train:, :]
y_test = data_feat.iloc[num_train:, :]['rise']
# 特征选择
data_train0 = select_features(data_train.drop(columns=['pct','rise']).dropna(axis=1, how='any'), y_train)
select_columns = list(data_train0.columns) + ['pct','rise']
data_train = data_train[select_columns]
data_test = data_test[select_columns]
print(data_train.shape)
输出结果:
(3462, 247)
接下来,按照老方法将因子数据标准化后,用于模型训练,从sklearn的svm模块当中导入SVM分类器SVC,创建实例对象后,将训练集因子数据和对应标签塞进fit函数就行了,SVM模型的惩罚系数使用默认值1.0,核函数也用默认的RBF核函数。
from sklearn.svm import SVC
from sklearn.preprocessing import StandardScaler
# 转化为numpy的ndarray数组格式
X_train = data_train.drop(columns=['pct','rise']).values
X_test = data_test.drop(columns=['pct','rise']).values
# 对数据进行标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 训练模型
classifier = SVC(C=1.0, kernel='rbf')
classifier.fit(X_train, y_train)
Step5:测试模型
至此,SVM分类器已经训练好了,把因子数据塞进predict函数,就能输出每个样本的预测值,咱分别把训练集和测试集的预测标签插回到原来的数据集当中,用来计算预测的准确率。
y_train_pred = classifier.predict(X_train)
y_test_pred = classifier.predict(X_test)
data_train['pred'] = y_train_pred
data_test['pred'] = y_test_pred
accuracy_train = 100 * data_train[data_train.rise==data_train.pred].shape[0] / data_train.shape[0]
accuracy_test = 100 * data_test[data_test.rise==data_test.pred].shape[0] / data_test.shape[0]
print('训练集预测准确率:%.2f%%' %accuracy_train)
print('测试集预测准确率:%.2f%%' %accuracy_test)
输出结果:
训练集预测准确率:65.51%
测试集预测准确率:54.62%
光看准确率还是不够直观,咱还要看一下如果纯粹按照这个择时模型的预测结果进行投资,能获得多少收益。假设指数可以多空交易,如果模型预测为1(上涨),第二天策略的收益率就是指数的涨幅,如果模型预测为0(下跌),第二天策略的收益率就是指数的涨幅的相反数,有了每天的日收益率之后,通过dataframe自带的累乘函数cumprod,就可以得到择时策略和沪深300指数的净值曲线,为了方(tou)便(lan)起见,不考虑交易费率,以及按照收盘价成交。
import matplotlib.pyplot as plt
#策略日收益率
data_test['strategy_pct'] = data_test.apply(lambda x: x.pct if x.pred>0 else -x.pct, axis=1)
#策略和沪深300的净值
data_test['strategy'] = (1.0 + data_test['strategy_pct']).cumprod()
data_test['hs300'] = (1.0 + data_test['pct']).cumprod()
# 粗略计算年化收益率
annual_return = 100 * (pow(data_test['strategy'].iloc[-1], 250/data_test.shape[0]) - 1.0)
print('SVM 沪深300指数择时策略的年化收益率:%.2f%%' %annual_return)
#将索引从字符串转换为日期格式,方便展示
data_test.index = pd.to_datetime(data_test.index)
ax = data_test[['strategy','hs300']].plot(figsize=(16,9), color=['SteelBlue','Red'],
title='SVM 沪深300指数择时策略净值 by 公众号【量化君也】')
plt.show()

Step6:调节参数
如果你觉得预测准确率和策略收益还达不到预期,可以对每一个步骤的参数进行调整改进。
就好比这次建模,跟上一次比起来,最大的不同点就是使用了不同的基础因子,还在基础因子上提取了众多的衍生因子,并且进行了有效因子筛选,训练集预测准确率从之前的57.52%提升到了65.51%,测试集预测准确率从52.35%提升到了54.62%,策略年化收益也从15.40%提高到了27.70%。
这就是改进了“因子参数”的结果,你还可以调整SVM模型参数、因子标准化方法、因子中性化/正交化方法等等。
最后一句话总结,tsfresh的确可以在短时间内,高效率帮助咱挖掘出成千上万的量化因子,虽然并不是每个因子都能有效,但足以应付因子看量这种需求,先解决数量,再解决质量。