1. 引言
OpenAI的ChatGPT于2022年11月末发布,以其强大的智能能力惊艳四方,掀起了大模型浪潮,开启大模型纪元的时代。大模型在语言理解、生成创作、逻辑推理等方面表现出非常高的性能水平;而搜索作为检索整合信息的经典场景,成为大模型落地的重要突破口,搜索行业迎来了变革的机会。微软作为OpenAI的最大股东,首先将chatGPT集成到New bing(现为Copilot)中,合并搜索与聊天能力,将搜索带到了一个新的创新水平。紧接着Google以及Baidu都紧随其后,结合自家大模型技术分别打造了SGE与AI伙伴的AI搜索引擎,以期建立大模型时代搜索的防御壁垒。专注于生成式搜索的创业公司Perplexity AI,不到两年时间估值达到5.2亿美元。国内的天猫璇玑、淘宝问问、抖音AI搜,B站AI助手等等,都将大模型嵌入搜索,为用户提供特色化的搜索体验。
2. 选车引擎如何革新体验
汽车之家是中国领先的汽车互联网平台,为汽车消费者提供贯穿选车、买车、用车、置换等所有环节的全面、准确、快捷的一站式服务,而汽车之家的搜索则是满足用户选车需求的重要入口。汽车之家传统的选车引擎,用户输入汽车相关的Query关键词, 发起搜索返回多个相关的候选结果;然后点击多个链接并进行浏览、信息提取;如果是更加复杂的选车问题,例如想了解“宝马x3的续航怎么样,内部空间大不大”,还需要反复更换不同的query进行搜索,整合多次的查找信息才能进行有效的选车决策。可以发现,当前的搜索选车模式下,用户需要甄别处理大量繁杂、碎片的信息,同时面对多样化的信息容易出现选择困难;对于复杂些的选车需求,用户的选车行为连贯性与完整性都难以保证。受限于传统的搜索形态与技术范式,如何优雅地解决此问题一直都是相对棘手的事。大模型的出现,让问题有了突破的可能。
大规模参数量模型的智能涌现,带来了多项任务上的极速性能提升,其ICL(In Context Learning,上下文学习)以及CoT(Chain of Thought,思维链)特性体现出LLM强大的泛化与智能水平。大模型擅长进行文本创作、语言理解、逻辑推理等AIGC任务,但应用于汽车垂直领域,仍然存在一些不足,例如:领域知识不足,通用大模型的训练数据无法涉及行业的私域数据,专业性知识存在盲区;幻觉问题,询问“剁椒鱼头车是什么”,GPT4给出下图中一本正经却并不正确的答案;时效性问题,大模型受限于参数化知识无法动态更新,对于数据时效外的问题只能拒绝回答或者幻觉生成。

可以发现,想要获得准确严谨的答案,单纯依靠大模型是不现实的,容易出现幻觉、时效性、领域知识、长尾等问题,无法有效满足用户的需求。因此,在大模型还是搜索引擎的选择问题中,我们选择了全都要!

3. 大模型驱动的生成式选车引擎
我们将大模型与搜索有机融合,打造了一种生成式的选车引擎GSE(Generative Search Engine)。其产品界面如图所示:
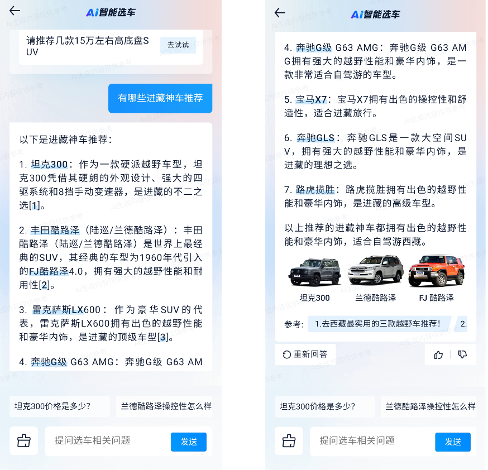
在输入侧,用户可以不再需要搜索的关键词技巧,无论短句还是长句,都可以通过更加自然的语言表达与GSE进行交互;输出侧的结果也不再需要从搜索结果中筛选点击阅读,直接给出Query对应的信息提炼总结,选车结果的交付更加简洁明了;输出结果中给出了引用来源,方便用户进行信息溯源,同时给出扩展的推荐问题,激发用户进一步对话交互。新选车引擎兼具了搜索的时效性准确性以及大模型的智能性,为用户提供高效精准、专业有趣的创新性选车体验。GSE整体架构如下图所示。
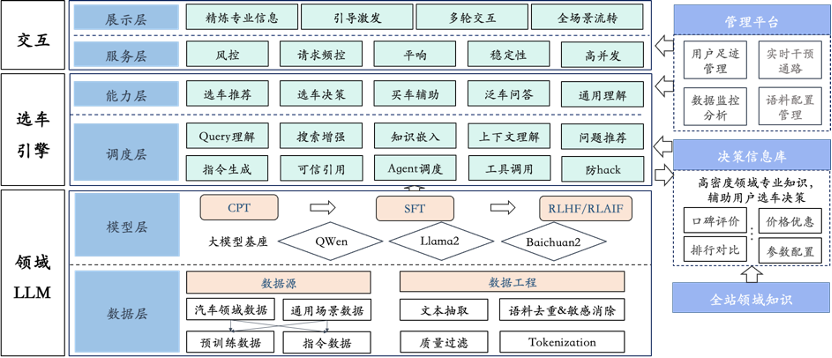
新选车引擎的核心主要包括两块,分别是领域大模型构建与引擎架构设计。接下来会针对这两块内容进行简要的介绍。
3.1. 汽车领域大模型
在RAG(Retrieval-Augmented Generation)检索增强或者是搜索增强方向,对于基础模型构建这块,通常有两种不同的思路。一种是不碰基础模型,模型本身不会引入额外数据进行调整,引入搜索能力即可,比较轻巧化的方案;另一种是训练领域大模型,丰富领域知识减少幻觉,但同时具有风险,因为除了训练成本较大,使用特定数据对大模型调整容易发生不稳定现象,造成模型崩溃与性能缺陷。汽车之家作为中国领先的汽车垂直平台,沉淀积累了海量、专业且全面的汽车行业知识数据,天然具有汽车领域的信息优势。基于团队的技术储备与硬件条件,我们选择训练垂直行业大模型,以达到在选车场景的最优效果,同时能够确保业务场景接入大模型的安全性与隐私性。业界实践中,大模型做SFT(Supervised Fine-Tuning,有监督微调)经常会遇到比较棘手的情况,领域上能力增强,但是通用上的能力变得一塌糊涂,各种任务上的评测效果都显著下降,对垂直域上的数据产生过拟合,失去了原有的泛化能力。如何有效解决这种灾难性遗忘问题,让大模型既保持很强的通用智能,又具有独特的领域专家思维,是垂域训练的主要目标。简单介绍下构建领域LLM过程中的实践经验。数据工程。大模型数据质量的重要性毋庸置疑,基本上大模型开发的大部分时间投入,都是在数据工程这块,并且数据的质量重要性要高于数据的数量。构建指令数据以及预训练数据都需要做足够的过滤、去重等清洗工作,保证数据的高质量、多样性以及准确性,让大模型能够感知并理解汽车行业的方方面面;重复性的数据会导致模型训练的恶化,不正确的信息相当于在源头提供了幻觉。同时不同类型的数据之间还需要保持合适的配比,合适的分布能够让模型有更好的效果。在SFT阶段,指令数据构建为(instruction,response)的形式,通过IT(Instruction Tuning,指令微调)约束模型遵循选车领域的特定类型指令,以期望的形式进行输出,满足选车场景的多样化用户需求。

训练策略。此处主要介绍SL(Supervised Learning)方式的对齐训练。垂域的大模型除了常用的SFT,在此之前还需进行CPT(Continual Pre-Training,持续预训练),才能让基座大模型更新扩充汽车领域的知识,以适应汽车领域的应用。GPU资源足够的话,可以偏向采用全参数微调,能起到较优的效果;否则可以采用LoRA(Low-Rank Adaptation,低秩适配)或者QLoRA的方式,进行轻量级微调。在灌入汽车行业数据提升领域能力的同时,为保证通用能力不受损,可以在SFT阶段搭配合适比例的通用数据与领域数据。另外,将CPT与SFT拆分成两阶段进行训练也许不是最好的选择,实践中发现,采用多任务训练的方式,将CPT与SFT放在一阶段进行联合训练,能起到更优的泛化效果。在模型层面,如下图所示,可以采用NEFTune的方式,在Embedding层添加少量的噪声进行正则化扰动,减少过拟合风险,提升指令精调的效果。

大模型的微调训练涉及面广,实践技巧繁多,例如数据配比、自动化样本筛选、超参数优化等;同时从数据->模型->评估->量化推理等整体链路需要进行全面的打磨优化,魔鬼在于细节,在此就不一一展开。在经过各种趟坑和策略优化后,我们获得了一个相比基座模型通用能力无损(MMLU、CMMLU、CEVAL等各评估集合上验证),汽车领域知识准确率相比GPT4 +9.3pp,领域能力显著提升的行业大模型。
3.2. GSE系统架构
以构造的领域大模型为基础,基于搜索增强的理念进行系统构建,提升选车引擎的系统信噪比。经典的RAG系统集成参数化模型和非参化记忆用于语言生成,系统接收输入的Query x,通过Retriever 和Generator 两个模块,检索到文档z并作为附加上下文,通过边际化处理的方式生成序列y,其形式化定义如下:

如果只是简单地将搜索结果输入给LLM进行生成,那这是Naive RAG的模式,容易存在检索生成质量不佳、噪声大的问题,对于专业精准性要求高的选车场景,Naive RAG基本无法满足业务需求。我们设计了基于大模型驱动的生成式AI选车引擎,其系统架构如下所示。其主链路核心包括QG(Query Generation,查询生成)模块、RG(Retrieve & Generate,检索与生成)模块、Re-Ranking重排模块以及CR(Compression & Refine,压缩精炼)模块。同时GSE构建了汽车领域的知识基座,能够为GSE的Agents提供专业化的知识决策参考;支持用户的多轮选车交互,保持选车行为的连续性与一致性;同时为权衡算力与在线性能,设计了包含离线、近线、在线计算的多级架构,能够节约算力的同时提升系统响应性能。
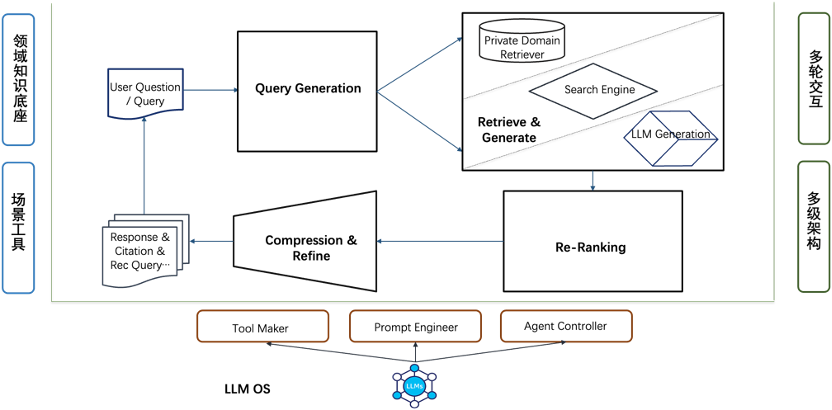
通过LLM的Prompt工程,使得系统每个模块都是拥有自主功能的AI Agent,同时能够与系统内其他Agent进行交互,形成LLM OS。
QG Agent能够提供Query-Expand、Sub-Query、Query Rewrite以及Query Routing等功能,并与其他Agent进行信息交互,对输入的不同复杂度、类型的Query进行扩展、改写、子问题分解、上下文理解、路由等变换生成操作,解决Query语义过简、复杂、表意模糊混淆以及上下文依赖等问题,提升输入信噪比。
RG Agent则是GSE非参化知识与参数化知识的重要处理部分,通过Query与上下文理解,智能动态化调度私域知识数据、垂类搜索引擎以及LLM生成信息,结合Sparse & Dense 双路检索方式,更好地应对复杂多样的选车查询需求。Re-Ranking则是对返回的信息根据整体相关性、时效性、多样性、个性化等维度,对候选进行重排与截断,为下游CR模块提供高质量信息。
CR Agent对信息进行准确高效的压缩提炼,由于CR位于链路输出端,直接影响生成质量,因此存在许多优化技巧,例如Chunk的自适应调整、迭代式自主精炼Self-Refine、基于CoV(Chain of Verification)验证链的事实性自主判断等,在此不一一展开。
GSE支持多轮交互,设计了Memory Agent,对会话历史进行压缩和调度管理。除此之外,GSE的Citation模块能够为输出结果提供自动化的引文生成。GSE还具有规划工具使用的能力,例如,如果你询问它今天限号情况,它会根据你所处的省市政策,给出最近一周的限号情况。目前各种实用能力还在进一步扩展中。
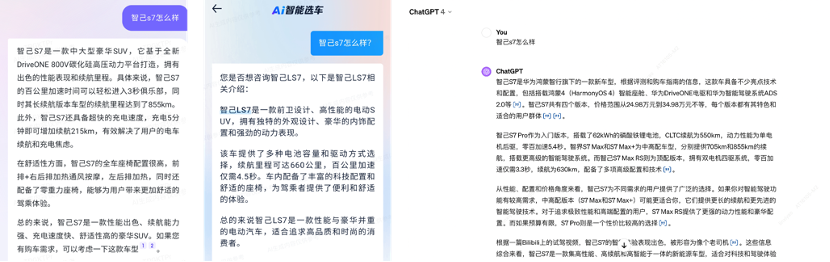
通过Agent化的方式构建了大模型驱动的生成式搜索引擎GSE,并对其进行了整体评估,在选车场景中传统引擎难以有效应对的长尾问题以及复杂选车问题上,效果独立评估与相对评估(相比传统搜索)上GSE都达到了非常不错的水平,选车体验焕然一新,更加出色。同时GSE在领域幻觉问题上的准确率也得到较大的提升,相比GPT4准确率高+8.0pp。当然,这只是其中一个维度的效果考量,GPT4作为当前最顶尖的大模型,其超高的综合智能水平一直是GSE基础大模型学习追逐的目标,模型全面维度的提升还有非常多的工作要做。关于幻觉的Case示例Query=“智己s7怎么样”,智己s7并不存在,近似的有智己LS7/智界s7,用户搜索经常发生混淆。下图从左至右分别是业界某款AI助手、GSE以及GPT4的回复结果。可以发现,即便是搜索插件接入模式的GPT4也发生了幻觉,而GSE较好的指出该车系不存在的事实,同时介绍了可能满足Query意图最相近的车。
3.3. 存在的不足与限制
在GSE系统设计中,虽然引入了多种鲁棒性与可靠性的设计,但实践中也发现,系统仍然会存在一些问题与限制。例如推荐偏差问题,类似“哪些车比较好看”较为宽泛的选车问题,在没有更多条件约束的情况下,好看是因人而异的,这可能导致GSE的结果对部分用户来讲是有偏差的;还有与搜索结果存在差异的问题,单篇的文档可能对某种类型的车具有强烈的情感偏好,而GSE强调则综合性的观点,这可能导致矛盾信息的出现;还有幻觉问题,大模型的自回归(AR, AutoRegressive)生成模式导致幻觉问题能被缓解,但幻觉生成的概率性总会存在,接下来需要对齐训练中做进一步的优化;另外当前的交互功能还比较简单,存在大量的改进升级空间。
4. 生成式选车的未来与展望
基于构建的先进领域大模型,为其插上搜索的翅膀,打造了革新性的生成式搜索引擎GSE,超越传统搜索与大模型,为用户提供更加高效流畅、专业有趣的搜索选车体验,开辟了新的服务路径,大模型驱动的新范式选车引擎具有很大的发展空间和潜力。产品功能方面,GSE可以提供全新的选车体验,其强大的智能化特性可以实现信息的一站式全场景流转,用户无需再在APP之间频繁地跳转,实现聚集化的流量入口;商业模式方面,基于GSE交互式的搜索形态可以进行更加原生化的广告营销,实现更短的转化路径,创造新颖高效的商业营销模式。基于大模型的生成式搜索,将会是未来业界发展的新兴方向,成为连接人类与信息世界的新桥梁。
关于我们我们是汽车之家商业智能团队,主要涉及AI选车、搜索、广告程序化投放、生成式AI等方向业务。真诚欢迎有DL背景、技术扎实的感兴趣小伙伴加入我们(Base 北京),一起打造汽车领域的先进技术引擎。投递简历邮箱: [email protected]"