没有数据训练大模型?OpenAI 总裁带队转录YouTube视频,谷歌、Meta 也想尽数据收割套路
 作者 | Cade Metz, Cecilia Kang, Sheera Frenkel,Stuart A. Thompson and Nico Grant译者 | 核子可乐策划 | 褚杏娟
作者 | Cade Metz, Cecilia Kang, Sheera Frenkel,Stuart A. Thompson and Nico Grant译者 | 核子可乐策划 | 褚杏娟2021 年底,OpenAI 开始面临数据供应荒。
这家人工智能研究机构在开发最新 AI 系统时,已然耗尽了互联网上所有质量稳定的英语文本库。现在他们需要更多数据来训练自家技术的下一个版本——更多更多。
为此,OpenAI 研究人员开发出一款名为 Whisper 的语音识别工具,能够转录 YouTube 视频中的音频以生成新的对话文本,再将其作为训练素材以提升 AI 系统的智能水平。
三名知情人士表示,部分 OpenAI 员工讨论了此举可能违反 YouTube 规则。谷歌旗下的 YouTube 明确禁止将其视频用于“独立”于该平台以外的应用场景。
知情人士指出,最终 OpenAI 团队还是转录了超过 100 万小时的 YouTube 视频。两位知情人士表示,这支团队包括 OpenAI 总裁 Greg Brockman,他还亲自协助收集了这些视频。整理出的文本随后被输入名为 GPT-4 的系统,这也是目前得到广泛认可的最强 AI 模型之一,也是最新版本 ChatGPT 聊天机器人的底层引擎。
这场貌似追求技术的 AI 军备竞赛,早已转变成疯狂搜集数字数据的对抗与掠夺。根据《纽约时报》的调查,为了获取这些数据,包括 OpenAI、谷歌和 Meta 在内的科技大厂可谓“各显神通”——他们无视公司原则、修改规定条款,甚至公开讨论如何规避版权保护。
根据《纽约时报》获得的内部会议记录,在坐拥 Facebook 和 Instagram 的 Meta 公司,经理、律师和工程师们去年曾讨论收购由 Simon & Schuster 出版社出版的长篇作品。他们还商定从互联网上收集受版权保护的数据,甚至愿意为此直面诉讼风险。与会者认为,逐个与出版商、艺术家、音乐家和新闻机构谈判授权许可恐将耗费过多时间。
与 OpenAI 一样,谷歌也在转录 YouTube 视频以为自家 AI 训练获取文本素材。五位了解谷歌具体操作的人士透露,这可能侵犯了视频版权,毕竟视频应归其创作者所有。
去年,谷歌还扩大了其服务条款。根据该公司隐私团队成员及《纽约时报》看到的一份内部消息,此番调整的动机之一就是为谷歌从公开的 Google Docs 文档、谷歌地图上的餐厅评论以及其他在线材料中提取更多信息敞开了大门,最终目的当然还是训练 AI 产品。
这些科技大厂的行动说明,在线信息——包括新闻故事、虚构作品、留言板帖子、维基百科文章、计算机程序、照片、播客及电影切片等——正在成为蓬勃发展的 AI 行业的根基与命脉。能否构建起强大的创新系统,往往取决于各方能否获得充足的数据来训练模型,进而生成与人类水平相当甚至更出色的文本、图像、声音与视频内容。
数据量甚至可以说将决定一切。领先的聊天机器人系统正在从涵盖多达 3 万亿字的数字文本池中学习,其体量约等于牛津大学博德利图书馆馆藏书籍总字数的两倍——该图书馆自 1602 年起就一直在收集各类信息。研究人员表示,“信息”是指由专业人士精心撰写及编辑的高质量内容,例如已出版的书籍和文章。
多年以来,互联网(包括维基百科和 Reddit 等网站)似乎成为取之不尽、用之不竭的数据来源。但想在 AI 领域傲视同侪的科技企业们仍在寻求更大的资源池。谷歌和 Mtea 坐拥数十亿用户,每天都会产生大量搜索查询与社交媒体帖子;但受到隐私法及其自身政策的限制,理论上并不能将大部分内容用于 AI 训练。
于是乎,数据供应短缺开始愈发凸显。研究机构 Epoch 表示,科技企业最快可能在 2026 年就用尽互联网上的高质量数据,其使用数据的速度已经明显超过了数据产出的速度。
硅谷风险投资公司 Andreessen Horowitz 的代表律师 Sy Damle 在去年关于版权法的公开讨论中谈到 AI 时表示,“这些工具获取实用功能的唯一途径,就是既接受大量数据的训练、又无视这些数据的使用许可。其需要的数据量如此庞大,即使是集体许可也仍无法满足。”
科技企业迫切需要新的数据,以至于部分公司开始使用“合成”信息。这些资讯并非由人类创建的有机数据,而是 AI 模型自身生成的文本、图像和代码。换句话说,AI 系统开始从自己的产物中学习知识。
OpenAI 表示,其每套 AI 模型“都拥有我们精心设计的独特数据集,以帮助其了解世界并保持研究层面的领先竞争力。”谷歌也提到,其 AI 模型“接受了一部分 YouTube 内容的训练”,这种行为符合其与 YouTube 创作者达成的协议,且该公司不会在实验计划之外使用来自办公应用的数据。Meta 则指出,他们已经通过“积极投资”将 AI 技术整合至各项服务当中,并使用来自 Instagram 及 Facebook 的数十亿公开分享图像及视频进行模型训练。
对于创作者来说,他们的作品正日益成为 AI 训练中的主要素材,由此引发的版权与许可诉讼也可谓此起彼伏。去年,《纽约时报》起诉 OpenAI 与微软侵权,称其在未经许可的情况下使用受版权保护的新闻文章来训练 AI 聊天机器人。OpenAI 及微软则表示这些文章属于“合理使用”,或者说并不违反版权法,这在本质上属于正常的二创行为。
去年,超过一万个贸易团体、作者、企业及其他机构向版权局提交了关于 AI 创意作品的使用报告,该局属于联邦机构,目前正着手对版权法内容做 AI 时代下的适用性调整。
电影制片人、前演员、两本出版书籍作者 Justine Bateman 提醒版权局,AI 模型会在未经许可或付费的情况下获取内容——包括她自己的书籍和影片。
她在采访中表示,“这是美国有史以来规模最大的盗窃案。”
“规模就是一切”2020 年 1 月,约翰·霍普金斯大学的理论物理学家、Anthropic 的首席科学官 Jared Kaplan 发表了一篇关于 AI 的开创性论文,激发了人们对于在线数据的高度关注。
他的结论非常明确:训练大语言模型(驱动在线聊天机器人的底层技术)需要的数据越多,春性能就越好。正如学生们通过阅读更多书籍以汲取更多知识一样,大语言模型也能更好地提取文本中的模式,并通过更多信息将这种模式整理得更加准确。
Kaplan 博士与其他九位 OpenAI 研究人员共同发表了这篇论文(他目前在 AI 初创公司 Anthropic 供职),并在文中指出“每个人都对这种趋势感到惊讶——我们将其称为扩展法则,而且基本跟天文学或者物理学定律一样可靠。”
于是,“规模就是一切”很快成为 AI 竞赛中的战斗口号。
长期以来,研究人员一直使用大型公共数字信息数据库来开发 AI,包括维基百科和 Common Crawl(一套自 2007 年以来涵盖超 2500 亿个网页的数据库)。在实际训练之前,研究人员通常会删除其中的仇恨言论及其他非必要文本以“清洗”数据,再将其“投喂”给 AI 模型。
按今天的标准来看,2020 年的数据集体量还很小。来自照片网站 Flickr 的一套 3 万张照片数据库,在当时已经被视为重要的训练资源。
而随着 Kaplan 博士论文的发表,这些数据量已经远远不够。来自纽约的 AI 公司 Nomic 的 CEO Brandon Duderstadt 表示,目前的关键就是“把规模扩大”。
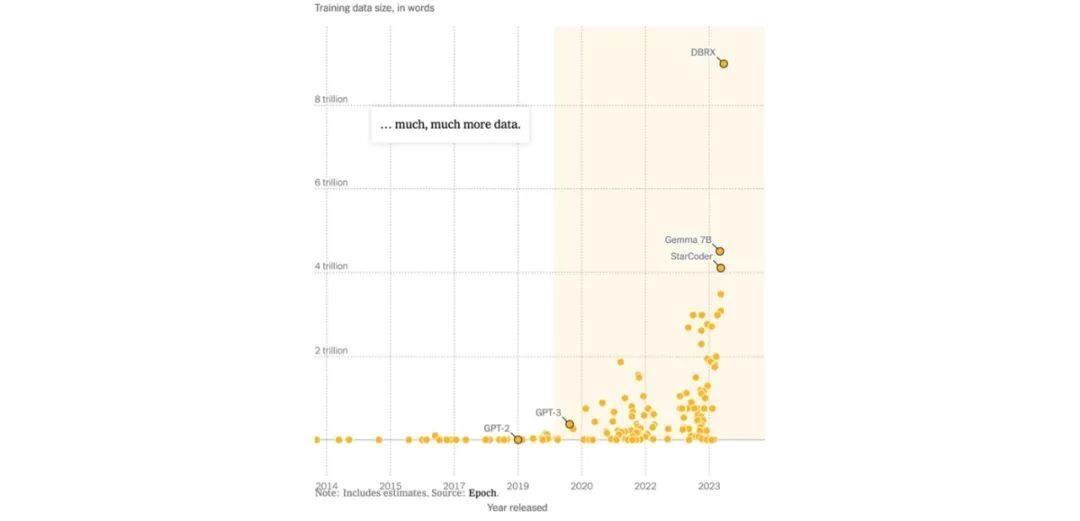
随着 OpenAI 公司于 2020 年 11 月发布 GPT-3,该模型接受了截至当时规模最大的数据训练——约 3000 亿个 tokens。所谓 tokens,本质上就是一个个单词或者短语片段。从数据中完成学习之后,系统开始以惊人的准确性生成文本,编写博文和诗歌甚至能够输出计算机程序。
2022 年,谷歌旗下的 AI 实验室 DeepMind 又迈出了关键一步。他们测试了 400 种 AI 模型并调整其训练数据量及其他因素,发现表现最好的模型所使用的数量规模甚至比 Kaplan 博士论文中的预测还要更大。其中一套模型 Chinchilla 接受了 1.4 万亿个 tokens 的训练。
这项纪录很快就被打破:去年,来自中国的研究人员发布了 AI 模型 Skywork,使用来自英文及中文文本的 3.2 万亿个 tokens 进行训练。谷歌随后发布 AI 系统 PaLM 2,tokens 数量突破 3.6 万亿。
转录 YouTube 内容去年 5 月,OpenAI 公司 CEO Sam Altman 承认,AI 企业将很快耗尽互联网上的所有可用数据。
他在一场技术会议的演讲上公开表示,“就快耗尽了。”
Altman 自己也切身感受到了这种紧迫感。在 OpenAI,研究人员多年来一直在收集数据、清洗数据并将其转录为大量文本以训练自家语言模型。他们挖掘了计算机代码库 GitHub,清洗了国际象棋走法数据库,并使用 Quizlet 网站上关于高中考试和家庭作业的数据。
根据八位了解 OpenAI 公司情况的人士(因未获授权公开发言而要求匿名)表示,到 2021 年底这些数据供应已经用尽。
OpenAI 公司迫切需要更多数据来开发其下一代 AI 模型,也就是我们熟悉的 GPT-4。知情人士称,员工们因此讨论了转录播客、有声读物及 YouTube 视频的可行性。他们还考虑利用 AI 系统从头开始创建数据,甚至想到收集那些掌握着大量数字数据的初创公司。
六位知情人士指出,OpenAI 最终开发出了语音识别工具 Whisper,专门用于转录 YouTube 视频及播客。但 YouTUbe 不仅禁止他方将其视频用于“独立”应用场景,还禁止他方通过“任何自动化方式(包括机器人、僵尸网络或爬虫工具)”访问其视频内容。
知情人士称,OpenAI 的员工清楚知道自己涉足的是法律的灰色地带,但他们相信使用视频内容训练 AI 属于合理使用。OpenAI 公司总裁 Brockman 在一份研究论文中被列为 Whisper 的缔造者。据两位知情人士介绍,他曾亲自帮助收集 YouTube 视频并将转录结果输入 GPT 模型。
Brockman 将置评请求转交给 OpenAI,该公司只模糊承认其使用了“来自众多来源”的数据。
去年,OpenAI 发布了 GPT-4,模型训练使用到 Whisper 转录的超 100 万小时的 YouTube 视频内容。这套最新、最强的大模型由 Brockman 领导的团队开发完成。
两位了解内情的人士表示,部分谷歌员工已经知晓 OpenAI 在收集 YouTube 视频作为训练数据,但他们并没有出声阻止,是因为谷歌自己也在使用 YouTube 视频的文字记录训练其 AI 模型。谷歌的这种作法同样可能侵犯 YouTube 创作者的版权。知情人士还提到,一旦谷歌揪住 OpenAI 的作法不放,那公众很可能针对其同类作法提出强烈抗议。
谷歌公司发言人 Matt Bryant 则表示,该公司对于 OpenAI 的行为一无所知,且禁止“未经授权抓取或下载 YouTube 内容”。他强调,谷歌将在获得明确法律或技术依据时采取行动。
谷歌的规则允许其利用 YouTube 用户数据为该视频平台开发新功能。但目前还不清楚谷歌是否可以利用 YouTube 数据构建除视频平台之外的商业服务,例如聊天机器人。
Berger Singerman 律师事务所的知识产权律师 Geoffrey Lottenberg 表示,谷歌对于 YouTube 视频记录可用于什么、不能用于什么的说法太过含糊其辞。
“这些数据是否可用于新的商业服务仍有待明确解释,甚至可能引发诉讼。”
2022 年底,就在 OpenAI 发布 ChatGPT 并引发全行业竞赛之后,谷歌研究人员和工程师们讨论了利用其他用户数据的可能性。用户们的 Google Docs 文档及其他免费谷歌应用中蕴藏着数十亿单词量的文本。但三名了解谷歌内情的人士指出,该公司的隐私条款限制了他们使用这些数据的方式。

据了解内情的人士介绍,在 OpenAI 发布 ChatGPT 之后,谷歌研究人员和工程师们开始讨论利用其他用户数据开发 AI 模型的可能性。
据隐私团队两名成员及《纽约时报》看到的一份内部消息称,谷歌法律部门于去年 6 月要求隐私团队起草措辞,以扩大该公司对消费者数据的许可使用范围。
员工被告知,谷歌希望利用用户们的 Google Docs 文档、Google Sheets 表格及相关应用程序中公开的内容来开发一系列 AI 产品。员工们称,他们不清楚公司之前是否曾利用这些数据训练过 AI 模型。
当时的谷歌隐私政策强调,该公司只会使用公开信息来“帮助训练谷歌的语言模型并构建谷歌翻译等功能。”
隐私团队编写了新条款,以便谷歌能够利用这些数据为其“AI 模型提供支持,并构建包括谷歌翻译、Bard 及 Cloud AI 在内的更多产品及功能”,也就是更广泛的 AI 技术集合。
隐私团队的一名成员在内部消息中质疑,“我们的最终目标是什么?我们还要做到什么程度?”
员工们表示,谷歌特别要求隐私团队要在 7 月 4 日周末发布新条款,想要用美国的独立日假期冲淡用户的关注。修订后的政策于 7 月 1 日长周末开始时首次发布。
谷歌如何使用客户数据下面来看谷歌去年对其免费消费者应用程序隐私政策做出的修改。
谷歌会使用客户信息以改进我们的服务,并开发有利于用户及公众的新产品、功能及技术。例如,我们会使用公开信息帮助训练谷歌的 语言 AI模型并构建包括谷歌翻译、Bard 及 Cloud AI 功能在内的产品与功能。两名隐私团队成员表示,去年 8 月他们曾向管理层施压,询问谷歌是否已经开始使用免费消费版本 Google Docs、Google Sheets 以及 Google Slides 中的数据,但并未得到明确答案。
Bryant 表示,隐私政策的变更是为了强调并明确谷歌不会在“未经用户明确许可”的情况下,使用 Google Docs 或相关应用程序中的信息来训练语言模型。这只是一项允许用户测试实验性语言模型的自愿计划。
他强调,“我们并没有根据条款内容的变化将其他数据类型用于模型训练。”
Meta 身陷争议Meta 公司首席执行官 Mark Zuckerberg 已经在 AI 领域投资多年,但随着 OpenAI 在 2020 年发布 ChatGPT,他猛然发现自己已经落后于时代。三位现任及前任员工(因未获发言授权而保持匿名)表示,Zuckerberg 决定立即迎头赶上并超越 ChatGPT。他连夜打电话给高管和工程师,敦促他们开发一款与之竞争的聊天机器人。
但到去年初,Meta 遇到了与其竞争对手相同的困境:得不到足够的数据。
从某位员工分享的内部会议记录来看,Meta 公司生成式 AI 副总裁 Ahmad Al-Dahle 曾向高管团队强调,他的团队几乎使用到互联网上所有公开发布的英文书籍、论文、诗歌和新闻文章以训练 AI 模型。
Al-Dahle 告诉同事们,除非获取更多数据,否则 Meta 的模型将无法与 ChatGPT 相抗衡。2023 年 3 月和 4 月,Meta 公司的部分业务开发领导、工程师和律师几乎每天都在开会讨论这些问题。
有人争论要不要以每本书 10 美元的价格买下新书许可权,从会议录音来看,他们还曾讨论收购 Simon & Schuster 出版社(该公司曾出版斯蒂芬·金等作家的作品)。
他们还谈到如何以不经许可的方式从互联网上获取书籍、论文及其他文本,甚至考虑顶着面临诉讼的风险扩大内容获取范围。录音显示,一名律师对于从艺术家手中夺取知识产权提出“道德担忧”,但现场无人给出响应。
Zuckerberg 的态度则非常明确——给我找出解决方案来!
一位工程师表示,“Zuckerberg 想在产品中实现的功能,我们目前根本就做不到。”
两名员工表示,虽然 Meta 运营着庞大的社交网络,但这里并没有丰富的用户帖子可供使用。他们指出,不少 Facebook 用户会删除之前发布的帖子,而且该平台也不以撰写严肃长文为主要卖点。
Meta 当时还身负另一项压力——由于 2018 年与选民分析公司 Cambridge Analytica 共享用户数据的丑闻,其隐私政策刚刚经过调整,实在不宜轻举妄动。
Zuckerberg 在一次投资者电话会议上表示,Facebook 和 Instagram 上公开分享的数十亿视频和照片“比 Common Crawl 数据集还要大”。
在会议讨论中,Meta 高管们谈到如何在非洲聘请承包商来整理当地小说及非小说素材。一位经理也在某次会上指出,这些素材中确实包含受版权保护的内容,“因为我们无法将其彻底剔除。”
Meta 的高管们认为,OpenAI 似乎在未经许可的情况下使用了受版权保护的素材。从录音来看,他们也清楚 Meta 需要很长时间才能跟出版商、艺术家、音乐家和新闻机构达成许可,所以肯定是选择了“先斩后奏”。
全球合作与内容副总裁 Nick Grudin 在一次会议上表示,“唯一阻止我们向 ChatGPT 水平看齐的因素,就是数据量。”
他还补充称,OpenAI 似乎正在使用受版权保护的素材,而 Meta 可以遵循这一“市场先例”。
录音还提到,Meta 公司的高管们同意参考 2015 年作家协会诉谷歌一案的法院判决。在该案中,谷歌被允许对在线数据库内的书籍进行扫描、数字化和缠上,理由是其仅复制了作品的部分片段,并对原件进行了改造,因此属于合理使用。
Meta 公司的律师们则在会上指出,使用数据训练 AI 系统也理应同属合理使用的范畴。
录音显示,至少有两名员工对于使用知识产权且以不公平甚至根本不付费的方式对待作者及其他艺术家表示了担忧。一名员工还与 Meta 公司首席产品官 Chris Cox 等高管人士就版权数据进行过单独讨论,并表示那次会议上没人关注使用他人创意作品产生的道德问题。
“合成”数据面对迫在眉睫的数据短缺难题,OpenAI 的 Altman 专门定下一条妙计。
他在 5 月的会议上表示,像 Meta 这样的公司终将使用由 AI 生成的文本进行训练——也就是合成数据。
这是因为 Altman 及其他高管都相信,AI 模型既然能够生成与人类相似的文本,那就一定可以输出额外的数据来开发更好的模型版本。这将帮助开发人员建立起日益强大的 AI 技术,并减少对受版权保护数据的依赖。
Altman 表示,“只要能够扩大合成数据的涵盖范围,也就是说只要模型足够智能,它就能生成高质量的合成数据,素材短缺问题将迎刃而解。”
多年以来,AI 研究人员一直在探索合成数据的可行性。但构建一套能够自我训练的 AI 系统,明显是说起来容易做起来难。利用自身输出学习的模型往往会陷入死循环——即不断强化自己的倾向、错误和局限性。
前 OpenAI 公司研究员、现任不列颠哥伦比亚大学计算机科学教授的 Jeff Clune 表示,“训练 AI 系统所需要的数据,就如同一条穿越丛林的道路。如果只使用合成数据进行模型训练,那 AI 就很可能在丛林中彻底迷失方向。”
为了解决这个问题,OpenAI 及其他厂商正在研究如何让两套相互独立的 AI 模型彼此引导。这些模型能够协同工作以生成更有用、更可靠的合成数据。其中一套系统负责生成数据,另一套系统则判断信息内容以保障输出质量。但研究人员对于这种方法能否奏效仍然存在分歧。
尽管如此,AI 大厂的高管们一刻也没有停止前进的脚步。
Altman 在会议上拍板,“我觉得应该没问题。” 声明:本文为 InfoQ 翻译整理,未经许可禁止转载。原文链接:
https://www.nytimes.com/2024/04/06/technology/tech-giants-harvest-data-artificial-intelligence.html?smid=nytcore-ios-share&sgrp=c-cb
内容推荐大模型应用挑战赛已拉开帷幕。现阶段,多数语言模型已完成 3 轮更新,大模型赛道入场券所剩无几。同时,2023 年超 200 款大模型产品问世,典型场景又有哪些产品动向?对于现阶段的文生图产品而言,四大维度能力究竟如何?以上问题的回答尽在《2023 年第 4 季度中国大模型季度监测报告》,欢迎大家扫码关注「AI 前线」公众号,回复「季度报告」领取。
 活动推荐
活动推荐AICon 全球人工智能与大模型开发与应用大会暨通用人工智能开发与应用生态展将于 5 月 17 日正式开幕,本次大会主题为「智能未来,探索 AI 无限可能」。如您感兴趣,可点击「阅读原文」查看更多详情。

今天是会议 9 折购票阶段,购票或咨询其他问题请联系票务同学:13269078023,或扫描上方二维码添加大会福利官,可领取福利资料包。
今日荐文
你也「在看」吗?👇