前言:深度学习并不难
在2024年的当下,人工智能成为最热门的方向,一提到AI,总会有各种各样的热词,机器学习、深度学习、大模型、生成式AI、通用AGI等等,AI同样是肉眼可见地影响着我们的生活,像AlphaGo这样的应用直接颠覆了围棋职业选手的生态,而Stable Diffusion、SoVits、GPT这些技术也在改变各行各业,几乎各个专业都开始做AI的交叉方向,笔者差不多四年前系统写过机器学习入门,本篇文章就聊聊深度学习入门。

前言
计算机领域的诺贝尔奖是大名鼎鼎的“图灵奖”,今年图灵奖刚刚颁布,普林斯顿高等研究院教授艾维·维格森成为历史首位拿下数学领域阿贝尔奖和计算机科学领域图灵奖的学者。最近十年,图灵奖破圈是在2018年,当时号称是人工智能深度学习三巨头的Yoshua Bengio、Geoffrey Hinton 和 Yann LeCun,三人共同获得了18年的图灵奖,成为深度学习领域的标志性事件。

Hinton辛顿教授是当之无愧的C位,三巨头之一的Yann Lecun还是Hinton的学生。而就在三人获奖的前一年,柯洁在乌镇不敌AlphaGo,宣告人类棋手不敌人工智能,之前写围棋系列柯洁那张老图,就是出自乌镇这次历史标志性事件。多个关于AI的头条轮番轰炸下,就像近两年的大模型一样,深度学习成为18年的热词。

同年,Bengio和学生Ian Goodfellow推出了新书《Deep Learning》,中文版《深度学习》,也就是大家熟知的花书,被誉为深度学习领域圣经,爆火的还有李沐的《动手学深度学习》、邱锡鹏的《神经网络与深度学习》以及《Python深度学习》几本包含代码实战的深度学习书。

往前还有笔者四年前推荐的周志华西瓜书和李航的《统计学习方法》,再往前还会啃PRML、ESL等经典的统计学习书籍,对于初学者来说,晚入门优势是学习资料成熟,通往大模型的学习路径更加清晰,比如2014年入门的时候还是VGGNet,到2024年入门的时候整个世界都变了。

这也是我又开始写深度学习入门的原因,技术发展速度太快,每一年重新回顾深度学习的时候,会发现主轴一直在变化,站在19年回望14-19年这五年,大家以为GAN会一统江湖,但是站在19-24年这五年,原来GPT才是主轴,创新是很难被预测或者计划的,我想到了29年再回顾24-29年,到时候可能又会调整对深度学习的看法。

深度学习入门
本文主要面向有一定数学基础的研究生和博士生。如果说什么方法能够最快最好的入门深度学习,那么一定是耐心读基础的论文,了解原理然后进行复现,深度学习领域可以说是距离我们时间最近的新兴方向之一,从全面爆发到现在也不过十多年时间,虽然时间不长,但是论文数量一点也不少。

1. ImageNet比赛(AlexNet)
深度学习元年,一般被视作是2012年,斯坦福大学李飞飞教授创立ImageNet项目,一个大规模的图像数据库,李飞飞举办了ILSVRC计算机视觉比赛,旨在推动图像识别技术的进步。图灵奖三巨头之一Hinton辛顿教授,他的两位学生Alex Krizhevskyh和Ilya Sutskever在ILSVRC12上夺冠,并取得了压倒性的胜利,他们发布的AlexNet是一个深度卷积神经网络,在图像分类任务上的表现,远远超过了以往的最佳方法。

Imagenet classification with deep convolutional neural networks.
相比于传统的机器学习算法,AlexNet使用了卷积神经网络CNN,并在神经网络中使用ReLU作为卷积神经网络的激活函数,解决了传统激活函数Sigmoid在网络更深时遇到的梯度消失问题,为了防止过拟合,训练时采用Dropout随机忽略神经网络中的一部分神经元,从平均池化改成了Max Pooling提升特征丰富性等等,AlexNet让深度学习开始逐渐成为人工智能研究的主流技术。

一系列的改进,AlexNet成为全球关注的焦点,大家发现深度学习在处理复杂的视觉分类任务上,居然比传统方法要好得多。当然,AlexNet还有一大成功法宝就是使用了英伟达老黄的GPU进行加速,当时Alex负责搭建网络,而IIya负责写CUDA代码,多年以后,IIya成为了OpenAI的创始人兼首席科学家,而黄仁勋的英伟达成为全球市值增长最快的科技巨头。

2. 更深的网络(VGGNet、GoogLeNet)
既然AlexNet深层卷积神经网络这么好用,大家开始研究到底为啥它好用,以及如何调整改进AlexNet,2014年,ImageNet大规模视觉识别挑战赛(ILSVRC)上,GoogLeNet和VGGNet成为前两名。

Very deep convolutional networks for large-scale image recognition.
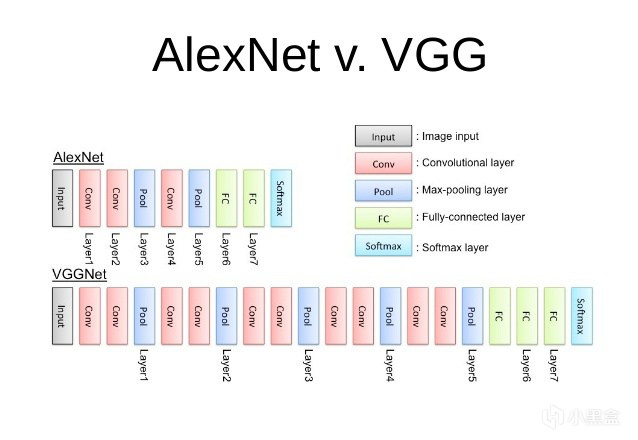
首先来看VGGNet,对比AlexNet,VGGNet更深了,如果包含全连接层,一共达到了22层,这样的设计在当时是前所未有的,VGGNet使用了3x3的小卷积核,能够捕捉到图像中的局部特征,每个卷积层后面紧跟着一个2x2的最大化池化层(Max pooling),用来减少参数数量避免过拟合,当时VGGNet还允许研究者通过增加层数来进一步提升性能,例如VGG-16和VGG-19。
Going deeper with convolutions.
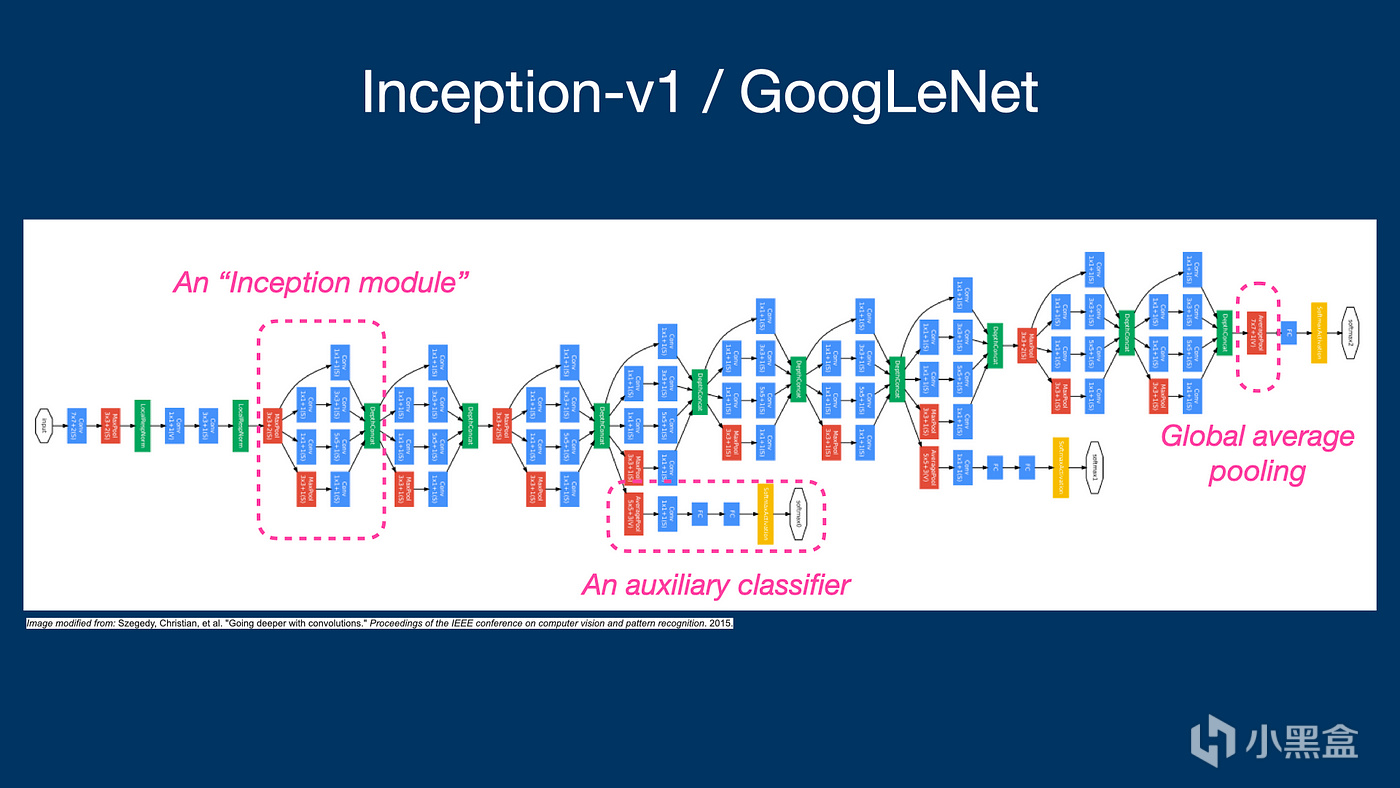
GoogLeNet在ILSVRC14取得了第一名,核心是Inception模块,对比VGGNet使用的3x3小卷积核,GoogLeNet使用1x1, 3x3, 5x5不同尺寸的卷积层,给人印象最深的当然是1x1卷积核,能够在不显著增加计算负担的情况下,增加网络的深度和宽度,GoogLeNet在分类和检测任务中均取得第一名的成绩,对后续的设计理念对深度学习研究的启发也同样很大,Inception模块的概念被广泛应用于后续的网络架构中,如Inception-v3、Inception-v4和EfficientNet等等等。
3. 初代神经网络(LeNet)
提到GoogLeNet,就不得不聊聊初代的神经网络LeNet,1988年,图灵奖三巨头之一的Lecun,利用反向传播BP算法,成功训练多层神经网络,进行MNIST手写数字识别,1998年,Lecun推出的LeNet-5模型,成为深度学习和卷积神经网络发展史上的重要里程碑。

LeNet结构包括卷积层、下采样层和全连接层,这些成为后来深度学习模型的基础,在1980年代到2012年之前的这段时间里,尽管BP算法和神经网络已经存在,但深度学习的发展相对缓慢。这主要是因为当时的计算资源有限,无法支持大规模的神经网络训练,此外,传统的机器学习算法,如支持向量机(SVM)等,在许多问题上也能取得不错的效果,这在一定程度上减少了对深度学习模型的需求。

4. 残差网络(ResNet)
Deep Residual Learning for Image Recognition
接下来15年,何恺明的ResNet横空出世,直接统治了ILSVRC 15和COCO 15,ResNet可以说是在前Transformer年代最知名的一篇论文,拿下CVPR的最佳论文,ResNet核心思想是残差学习,将网络层学习的内容,从直接映射转变为学习输入与输出之间的残差(差异),缓解网络深度增加而出现的梯度消失和梯度爆炸问题,ResNet由多个残差块组成,每个残差块包含两个或更多的卷积层,通过Shortcut连接,对比此前的AlexNet等结构,ResNet能够训练高达152层的网络,这在当时是一个前所未有的深度。

实验结果表明,随着网络深度的增加,ResNet的性能也相应提高,这也成为解决了之前“网络深度增加会导致网络表现下降”的问题,ResNet在训练过程中使用了Batch Norm和ReLU激活函数,但不需要使用Dropout或者Maxout这类正则化,因为残差学习本身就有正则化的效果,ResNet因其出色的性能和可扩展性,在计算机视觉领域的多个任务中得到应用,包括图像分类、目标检测、语义分割等,为后续的深度学习模型设计提供了新的思路。

深度学习从ImageNet开启的计算机视觉CV时代而起,早期的自然语言理解NLP等领域,相对于CV其实并没有那么火,但是同样也值得一聊,毕竟今天的Transformer时代,也是同样建立在前人的肩膀上完成的。2012年,除了AlexNet以外,Hinton辛顿教授还有一篇将神经网络用于语音识别的论文。

5. 转折点
Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups.
深度学习始于2006年Hinton辛顿的深度置信网络(Deep Belief Nets/Deep Belief Network,DBN),到了12年开始,大家开始研究如何把网络变得更深,深度神经网络(DNN)成为当时最热门的方向,在应用领域方面,辛顿将DNN应用在语音识别方向,希望能够代替之前的隐马尔可夫模型(HMMs)。

论文中提到了用循环神经网络(RNNs)和长短期记忆网络(LSTM)架构用于语音识别领域,辛顿这篇论文成为语音识别领域的转折点,为接下来几年快速发展奠定基础,论文的作者来自多个不同的研究小组,代表了当时语音识别领域的顶尖力量,其中包括微软研究院语音研究首席科学家邓力。

后话:放在四年前,还是Bert和GPT等模型争雄的时候,许多人认为AI离自己很远,但是短短四年后,AI方面的应用已经在各方面开花,英伟达、OpenAI、微软,成为当下全球科技聚光灯中心的公司,人人都在聊GPT,海量的资金涌入大模型领域,大量研究生博士生即使不是CS领域,也开始做与AI大模型的交叉方向。本文暂时先更到这里,预计完结至少需要15篇左右的篇幅,如果大家喜欢的话,再继续将这个坑填完,之后有时间再继续写大模型的发展史&入门,Hinton的学生们成为台上的焦点。

机器学习基础:
AI编年史——深度学习的发展史(收藏向)
AI编年史2——GPT是如何诞生的?
AI学术巨佬——何恺明,从游戏中获得论文灵感
AI领军人物——孙剑,重剑无锋的经典之作
AI传奇巨佬——汤晓鸥,中国人工智能领袖人物!
张益唐——黎曼猜想,华人数学家再创重大突破!
B站大学——线代不挂科,MIT传奇教授的最后一课!
微软免费AI课程——18节课,初学者入门大模型!
机器学习——科学家周志华,成为中国首位AI顶会掌门人!
机器学习入门——数学基础(积分篇)
机器学习入门——数学基础(代数篇)
机器学习入门——数学基础(贝叶斯篇)
游戏&AI系列:
AI——是游戏NPC的未来吗?
巫师三——AI如何帮助老游戏画质重获新生
AI女装换脸——FaceAPP应用和原理
AI捏脸技术——你想在游戏中捏谁的脸?
Epic虚幻引擎——“元人类生成器”游戏开发(附教程)
脑机接口——特斯拉、米哈游的“魔幻未来技术”
白话科普——Bit到底是如何诞生的?
永劫无间——肌肉金轮,AI如何帮助玩家捏脸?
Adobe之父——发明PDF格式,助乔布斯封神
论文相关:
毕业季杂谈——如何随时免费使用中国知网?
毕业季杂谈——论文降重的“奇技淫巧”
毕业季杂谈——大学教材如何获取
毕业论文——Latex论文排版语言介绍