近日,华为AI4SCI Lab联合北京大学北京国际数学研究中心教授、北京大学国际机器学习研究中心副主任董彬教授团队,在昇腾AI处理器的强大算力支持下,基于全场景AI框架昇思MindSpore推出了一维含时偏微分方程通用模型PDEformer-1。该成果在昇思人工智能框架峰会2024上首次发布亮相。
在包含三百万条不同形式的一维偏微分方程(PDE)数据的广泛预训练后,PDEformer-1模型在训练数据分布内的Zero-shot预测精度,已超越那些仅针对特定方程进行精细训练的专家模型,如FNO和DeepONet。值得一提的是,在面对训练集之外的数据分布时,PDEformer-1更展现出卓越的小样本学习能力,能够凭借少量样本迅速适应并泛化至新的方程,并能够很好地支撑下游任务(如各类反问题)。为了促进学术交流和工业应用,代码及模型参数已经在昇思MindSpore社区开源(链接附在文末),同时相关论文已经被ICLR workshop on AI4DifferentialEquations in Science录用。
偏微分方程基础模型PDEformer-1,旨在实现不同PDE的通用求解
偏微分方程(PDE)与众多物理现象及工程应用紧密相连,涵盖机翼设计、电磁场模拟、应力分析等广泛领域。在这些实际应用中,PDE的求解往往需要反复进行。PDE数值求解领域当前可分为传统的数值求解方法与AI求解方法两大类别。无论何种方法,面对复杂多变的实际场景,都没有较强的通用性,需要耗费大量的人力和算力来适应新的场景。
华为AI4SCI Lab与北京大学董彬教授团队携手,基于全场景AI框架昇思MindSpore共同提出了PDEformer-1模型,这是一种创新的数据驱动方法。PDEformer-1的核心在于将不同PDE的符号信息转换为多样化的计算图表示形式,然后模型采用Graph Transformer来整合图中的符号和数值信息,最后模型使用隐式神经表示(INR)方案来表达方程各分量的解。值得一提的是,PDEformer-1的构架可以更加灵活的拓展到2D和3D,可实现1D、2D、3D的联合训练。
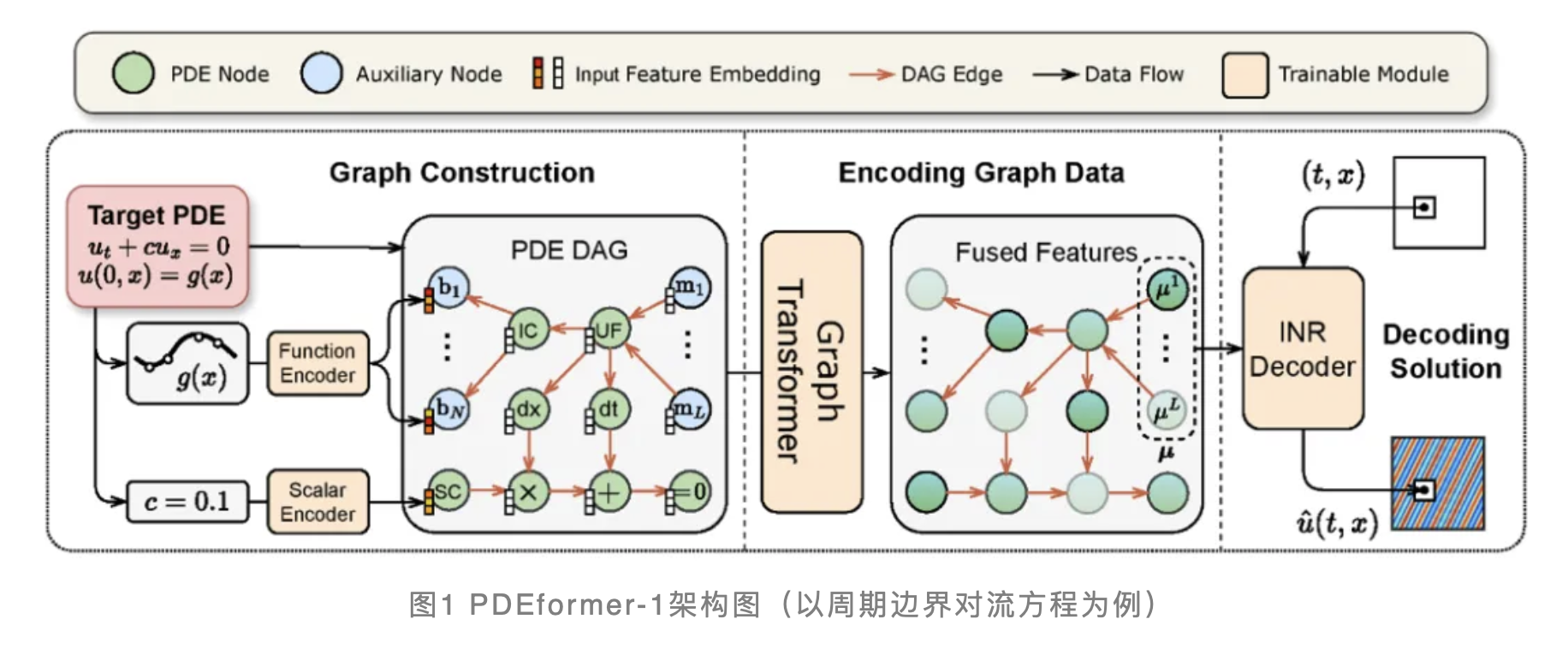
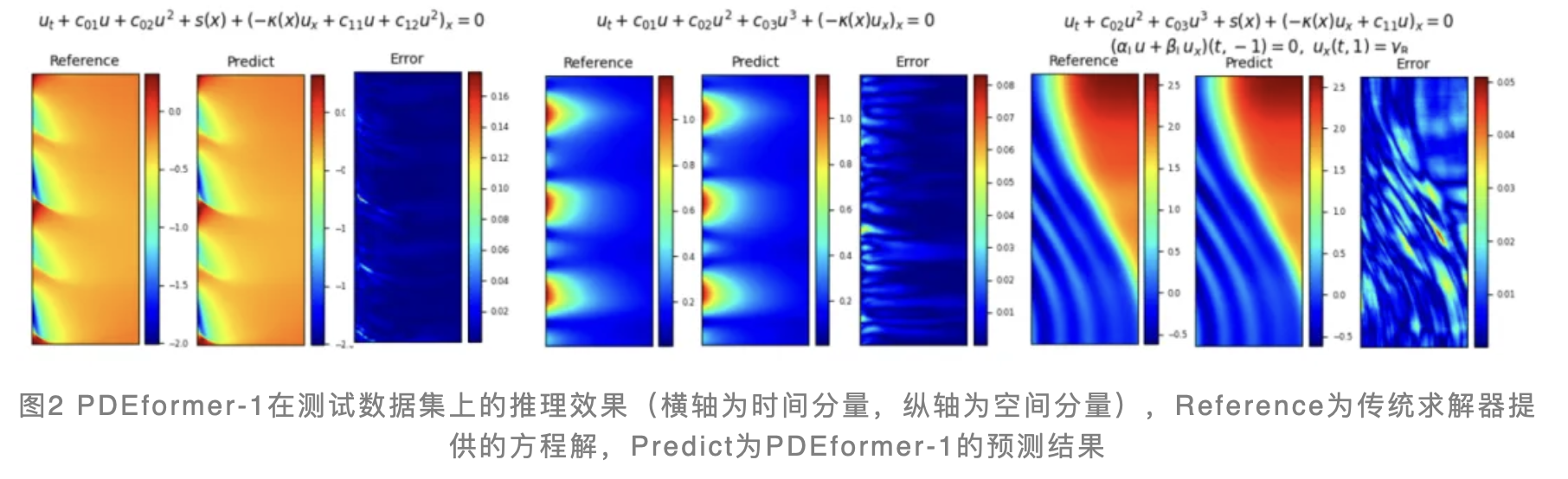
在预训练阶段,PDEformer-1模型在由300万个样本构成的训练集上取得了0.0084的相对误差表现,而在测试数据集的相对误差为0.0133。下图展示了预训练后的PDEformer-1在测试数据集上的预测结果,该模型在不同PDE问题的求解上均展现出了高度的准确性。
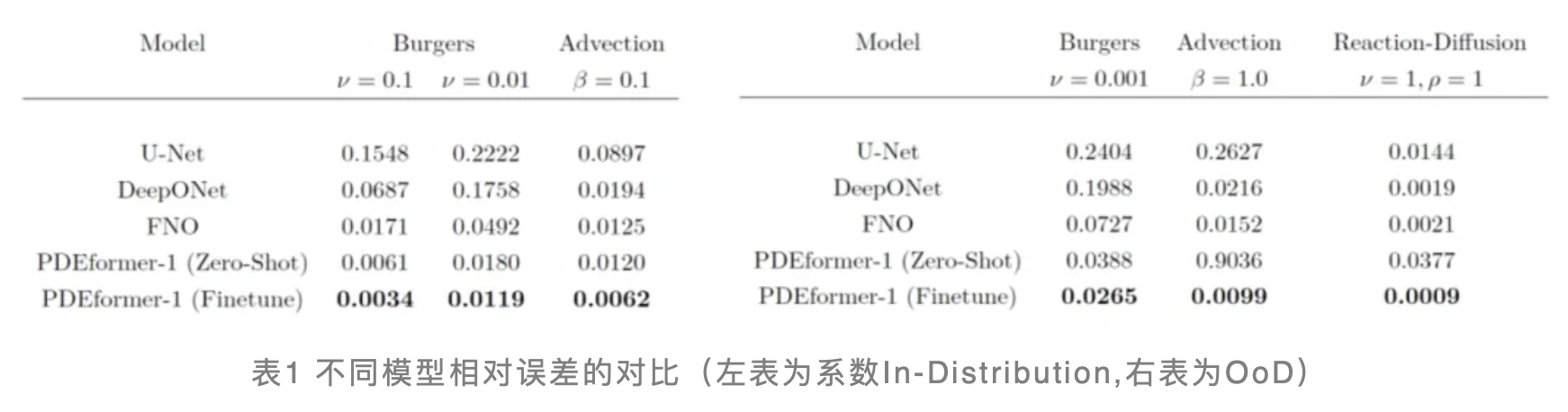
为了评估预训练后的PDEformer-1在正问题求解方面的性能,研究团队选用了业界标准的PDEBench数据集进行测试,并将所得结果与针对特定PDE设计的专家模型(如FNO和DeepONet)进行了详尽比较。如表1(左)所示,在方程系数处于预训练数据集系数分布范围内(即In-Distribution)的情况下,PDEformer-1展现出了卓越的Zero-shot推理性能,其精度超越了专家模型。表1(右)则展示了Out-of-Distribution (OoD)的结果,PDEformer-1在特定PDEBench数据集上进行微调后(后缀为Finetune)可以达到最低的相对误差。
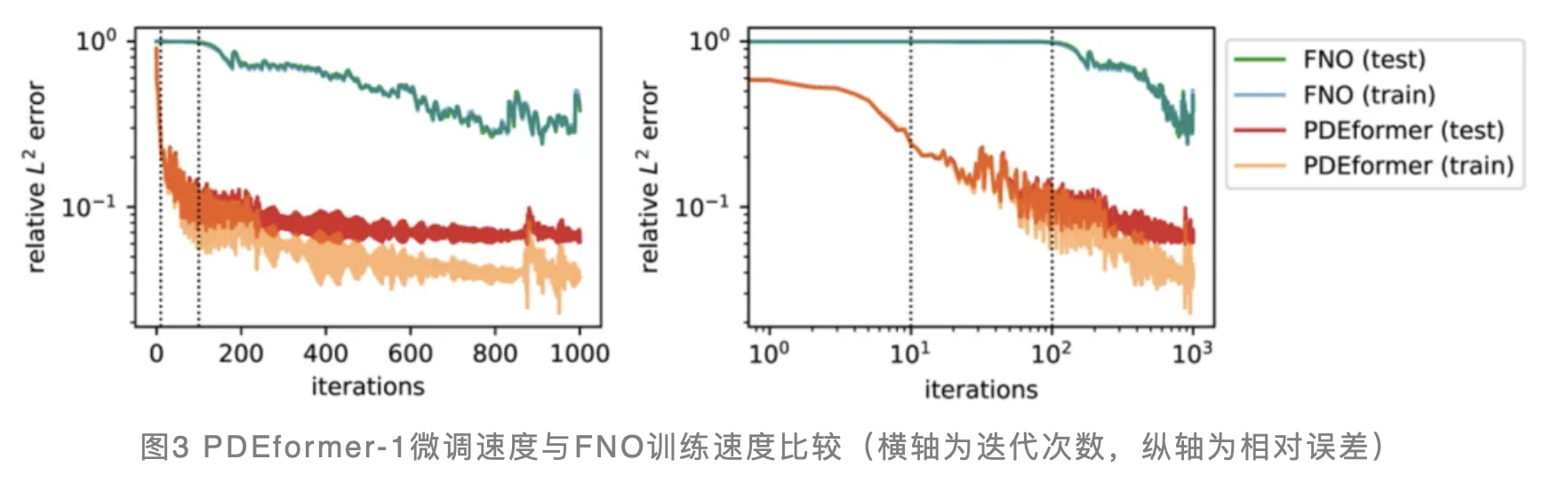
为了对比微调PDEformer-1与训练专家模型在效率上的差异,研究团队针对PDEformer-1在PDEBench数据集上的OoD情况(即Advection方程,β=1并且仅使用100个训练样本)进行了深入分析。如图3所示,PDEformer-1在微调过程中仅需100次迭代即可达到较高精度。相较之下,从零开始训练的FNO模型则需要数千次迭代才能收敛,且其测试误差也更高。这一对比结果充分展现了PDEformer-1在OoD情况下的快速适应能力和高效性。
PDEformer-1不仅在正问题求解中表现出色,而且也能有效应用于反问题的求解。作为正问题算子的代理模型,它可用于常数系数反演、源项反演以及波方程速度场反演等多种任务,展现出其强大的通用性和实用性。
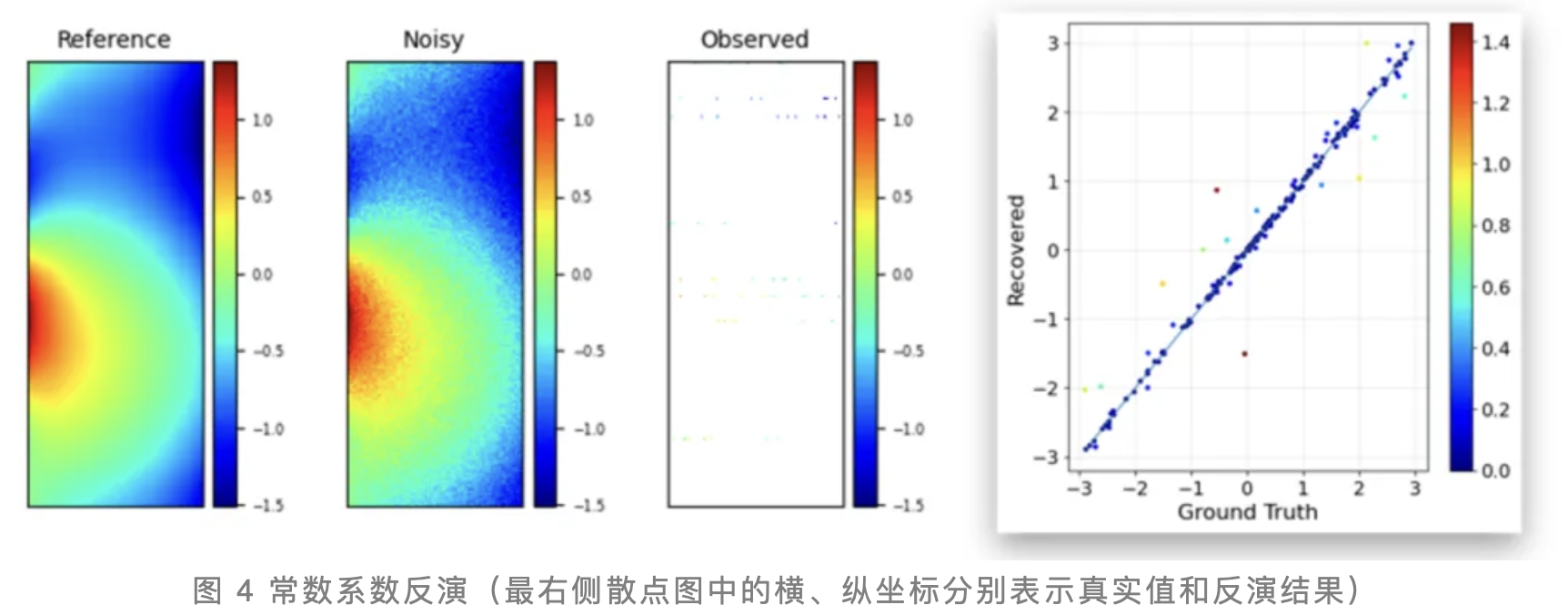
图4展示了研究团队将粒子群优化算法与PDEformer-1模型相结合,成功应用于常数系数反演任务。图中左侧,Reference代表真实方程解,Noisy为含噪声的方程解,而PDEformer-1实际可获得的观测只有含噪声解的一小部分(如Observed所示)。散点图直观展示了反演得到的方程系数与真实系数之间的高度吻合,几乎所有散点都紧密分布在y=x线上,充分证明了该方法的准确性和有效性。
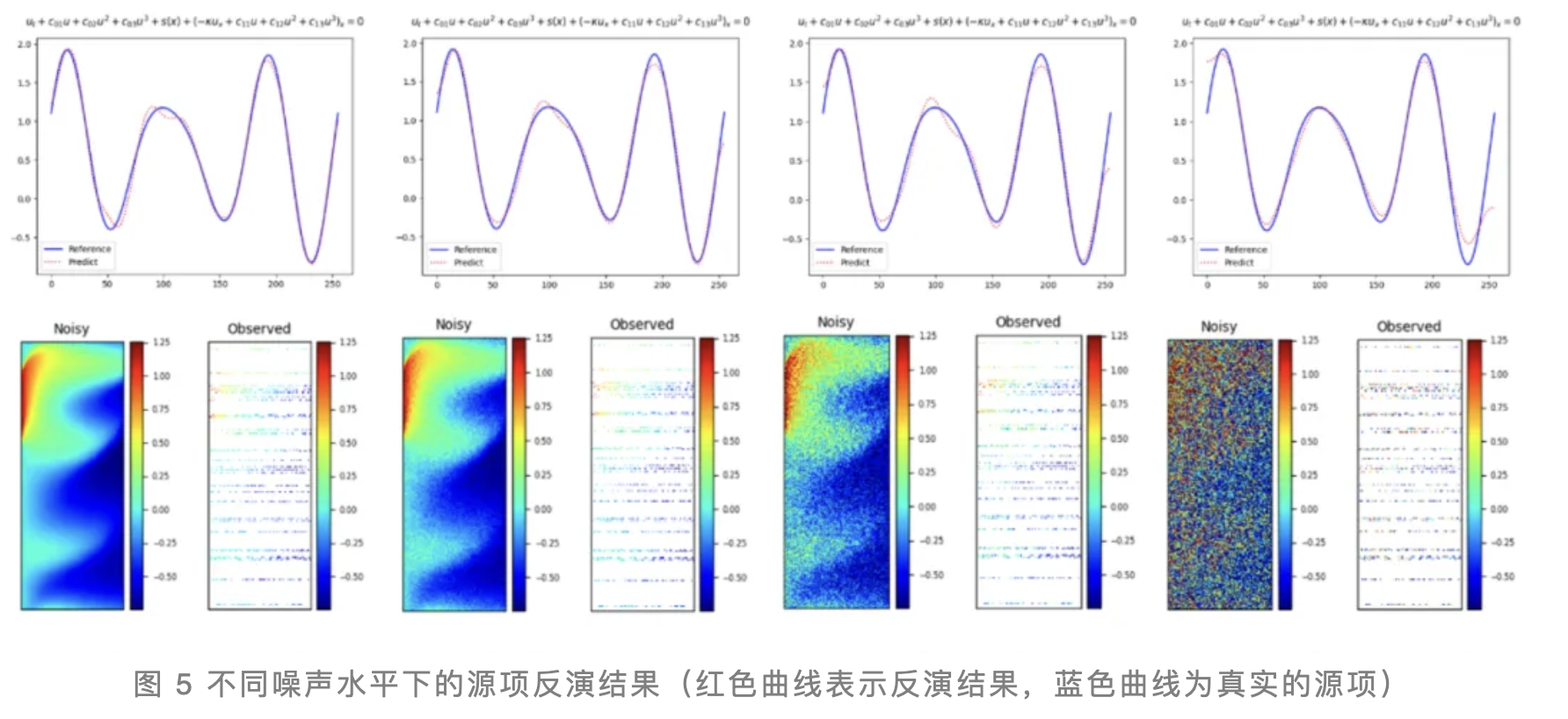
预训练后的PDEformer-1还可应对更具挑战性的反问题,如源项反演任务。研究团队将源项(即空间依赖的函数)作为待优化向量输入PDEformer-1,并运用梯度下降法进行优化,使模型输出与不完整观测数据吻合。图5展示了PDEformer-1在不同噪声水平下的反演结果,即便在高噪声干扰下,其反演结果与实际源项的偏差依然极小。这一结果充分证明了PDEformer-1在解决复杂反问题时的卓越表现和鲁棒性。
PDEformer-1在求解PDE正问题与反问题上展现了卓越的灵活性和效率。在PDEBench数据集与专家模型的对比中,PDEformer-1不仅在Zero-shot预测任务中超越了专家模型,更在小样本学习及新任务适应方面凸显出显著优势。同时,在处理如常数系数反演、源项反演等复杂挑战性反问题时,该模型亦展现出高精度和实用性,充分印证了其强大的求解能力。
昇腾AI基础软硬件平台、昇思MindSpore AI框架,支持PDE基础模型探索
依托昇思MindSpore框架的分布式并行能力,以及64块昇腾NPU的强大算力支撑,参数量达到58M的PDEformer-1模型在包含三百万样本的庞大数据集上进行预训练,仅需短短3天即可完成。这一高效表现得益于昇思MindSpore在昇腾AI基础软硬件平台与昇腾CANN的深度集成,通过深度协同优化的高性能算子库,实现了硬件算力的最大化释放。
为了将该PDE基础模型应用于真实场景,研究团队将致力于提升其训练效率,使其能够解决二维、三维乃至更高维度的方程,并研究如何同时利用这些不同维度的数据进行训练。未来不久,研究团队将陆续推出针对二维方程的PDEformer-2、针对三维方程的PDEformer-3,以及融合了不同维度方程的PDEformer。同时,研究团队将扩大考察的方程类型范围,并深入探索更多种类的下游任务。除了已初步研究的反问题,未来还将把PDEformer应用于优化设计、控制、不确定性量化等更广泛的领域。PDEformer能够针对任意类型的PDE,在无网格情况下迅速给出精度可接受的方程解,这让它有望解决传统PDE数值求解方法中编程困难、高计算资源消耗的问题,为所有类型PDE的数值求解提供一种新的范式。
了解更多可查看论文:

相关链接: