Meta 宣布正式推出下一代开源大语言模型 Llama 3;共包括 80 亿和 700 亿参数两种版本,号称“是 Llama 2 的重大飞跃”,并为这些规模的 LLM 确立了新的标准。
目前,Llama 3 已集成到智能助手 Meta AI 中。预计 Meta Llama 3 将很快在 AWS、Databricks、Google Cloud、Hugging Face、Kaggle、IBM WatsonX、Microsoft Azure、NVIDIA NIM 和 Snowflake 上提供,并得到 AMD、AWS、戴尔、英特尔、NVIDIA 和高通提供的硬件平台的支持。
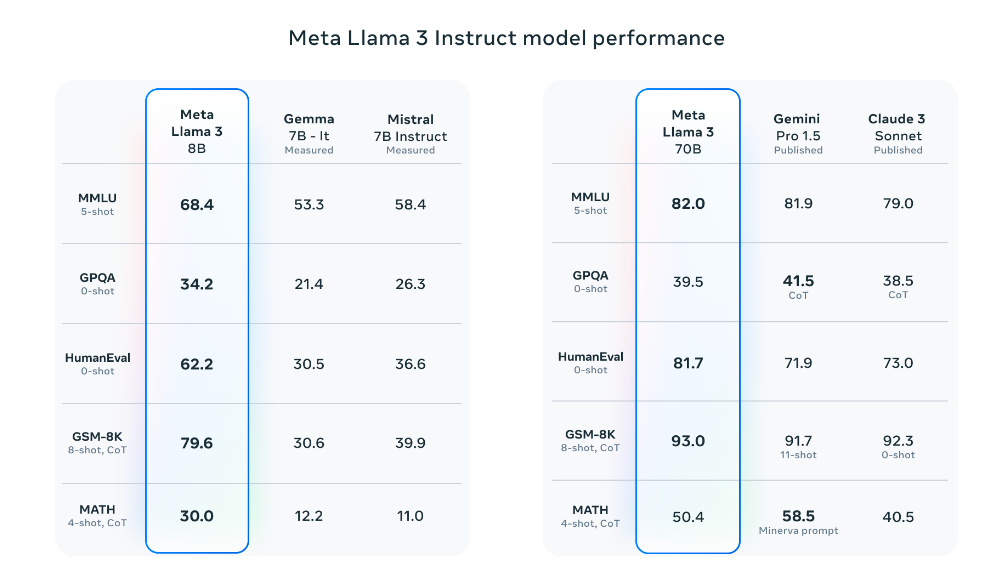
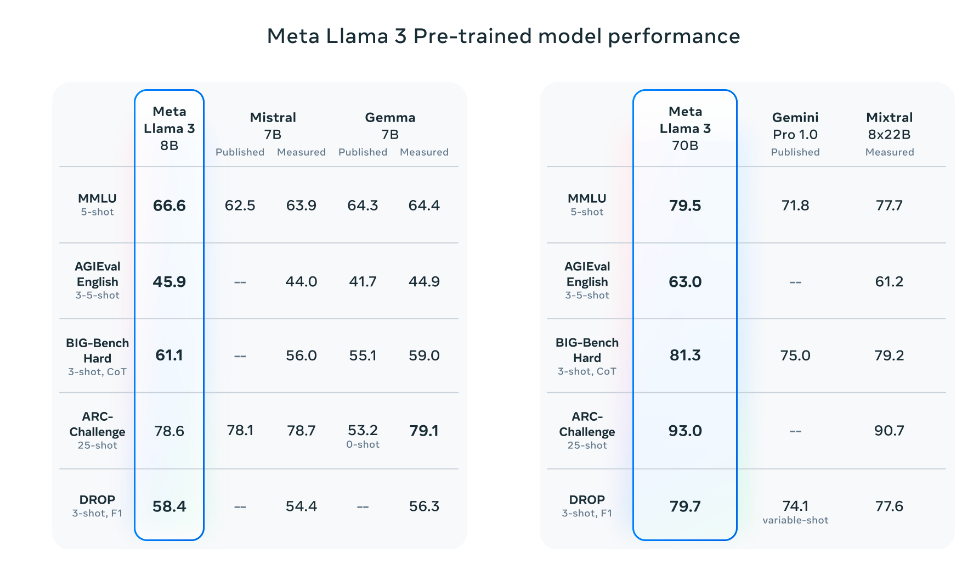
“由于预训练和训练后的改进,我们的预训练和指令微调模型是当今 8B 和 70B 参数规模的最佳模型。我们训练后程序的改进大大降低了错误拒绝率,改善了一致性,并增加了模型响应的多样性。我们还看到了推理、代码生成和指令跟踪等功能的极大改进,使 Llama 3 更加易于操控。”
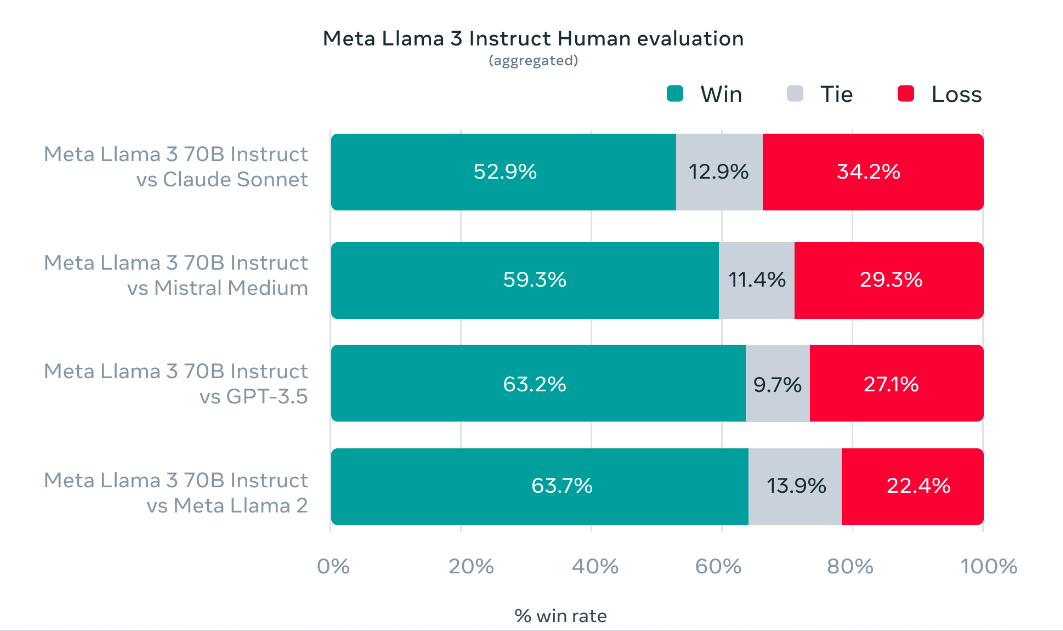
此外,Meta 还开发了自己的测试集。包含 1,800 个 prompts,涵盖 12 个关键用例:寻求建议、头脑风暴、分类、封闭式问答、编码、创意写作、提取、塑造角色/角色、开放式问答、推理、重写和总结。
在模型架构方面,Llama 3 选择了一个相对标准的纯解码器 Transformer 架构。与 Llama 2 相比,做了几个关键的改进。Llama 3 使用一个包含 128K tokens的分词器,可以更有效地编码语言,从而显著提高模型性能。
为了提高 Llama 3 模型的推理效率,在 8B 和 70B 两种规模上都采用了分组查询注意力(GQA)机制;同时在 8192 个tokens的序列上训练模型,使用掩码确保自注意力不会跨越文档边界。
为了训练出最好的语言模型,Meta 在预训练数据上投入了大量资金。Llama 3 使用超过 15 万亿个公开可用来源的 token 进行了预训练,训练数据集相较 Llama 2 大了有七倍,代码量是 Llama 2 的 4 倍。它支持 8K 上下文长度,是 Llama 2 容量的两倍。
其中超过 5% 的 Llama 3 预训练数据集由涵盖 30 多种语言的高质量非英语数据组成,以为即将到来的多语言使用用例做好准备。不过“预计这些语言的性能水平不会与英语相同。”
值得一提的是,Meta 公司还在训练更大的模型,拥有超过 4000 亿参数。在接下来的几个月中,他们预计将发布多个具有新功能的模型,包括多模态、以多种语言交谈的能力、更长的上下文窗口和更强的整体功能。一旦完成 Llama 3 的训练,还将发布一份详细的研究论文。

更多详情可查看官方公告。