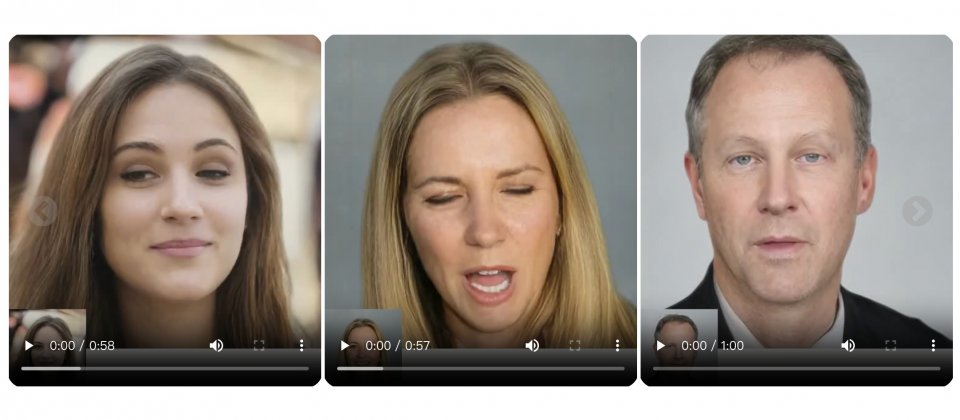
微软公开其最新虚拟人像技术VASA-1框架,该框架只要使用一张肖像照以及一段语音音讯,就能够产生精确逼真的人脸对嘴说话影像,影像中人物甚至可展现自然的表情和头部动作。VASA-1框架可即时生成高达40 FPS的512×512影像,适合虚拟形象的即时互动用例。
以人工智慧生成能够说话的脸孔,可使人工智慧技术更具互动性,丰富数位通讯体验,也能强化沟通的无障碍性,在教育、医疗和社交都有许多用处。但过去的技术,距离产生真实且自然的说话脸孔还有一大段距离,不少研究聚焦在对嘴上,脸部动态行为通常被忽视,因此生成的脸部也会显得僵硬且缺乏说服力。
除了表情之外,头部运动在增强虚拟人像的真实感,也发挥极大的作用,但与模拟脸部表情所遭遇的问题相同,目前生成的动画和人体运动模式之间存在相当大的差距。另外,生成效率也是该项技术的一大重点,唯有足够低延迟,脸部生成技术才能良好地支援即时通讯等应用。
微软VASA-1框架克服了以往虚拟人像生成技术的限制。此框架的特别之处在于,研究人员利用扩散Transformer模型,在整体脸部动态和头部运动潜在空间进行训练,该模型将所有可能的脸部动态,包括嘴唇动作、表情、眼睛注视和眨眼等行为,视为单一潜在变数,并统一建模其机率分布。
研究人员针对整体脸部动态建模,在加上联合学习的头部运动模式,最终产生各种逼真且情感丰富的说话行为。同时,微软利用3D技术辅助表示脸部特征,并特别设计损失函式,使得VASA-1不只能够生成高品质脸部影像,且能有效地捕捉和重现脸部3D结构。
VASA-1不只图像生成品质自然良好,另一大优点更是能高效运作,即时生成逼真的说话脸部,而这对于通讯的即时互动更是关键性的能力。研究人员在Nvidia RTX 4090 GPU桌上型电脑进行评估VASA-1,线上串流模式512×512解析度可达40 FPS,延迟时间仅有170 ms。