
大数据流水线系统πFlow V1.8版本正式发布,本次更新包含以下内容:
-
新增特性:
-
新增对非结构化数据的解析能力。
-
-
已有功能优化:
-
Server端H2数据库;
-
自定义Python算子;
-
模板功能;
-
流水线。
-
一、πFlow新增对非结构化数据的解析能力
πFlow新增非结构化解析组件以支持用户从原始非结构化文档中提取结构化内容。这些组件将文档分解为 Title、NarrativeText 和 ListItem 等元素,使用户能够决定要为其特定应用程序保留哪些内容。例如,如果要训练摘要模型,则可能只对 NarrativeText 感兴趣。使用该功能需将Server端配置文件中的unstructured.parse属性设置为“true”。
下表展示了πFlow当前支持的非结构化解析组件。
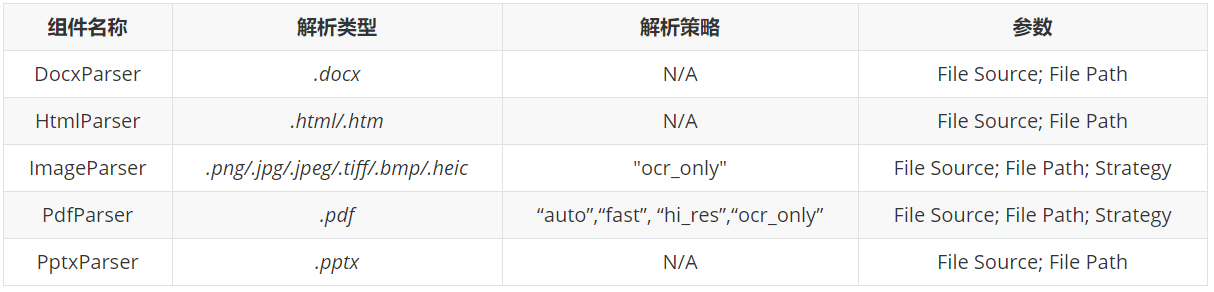
DocxParser
DocxParser是用来解析.docx的组件,参数说明如下:

组件样例配置如下:
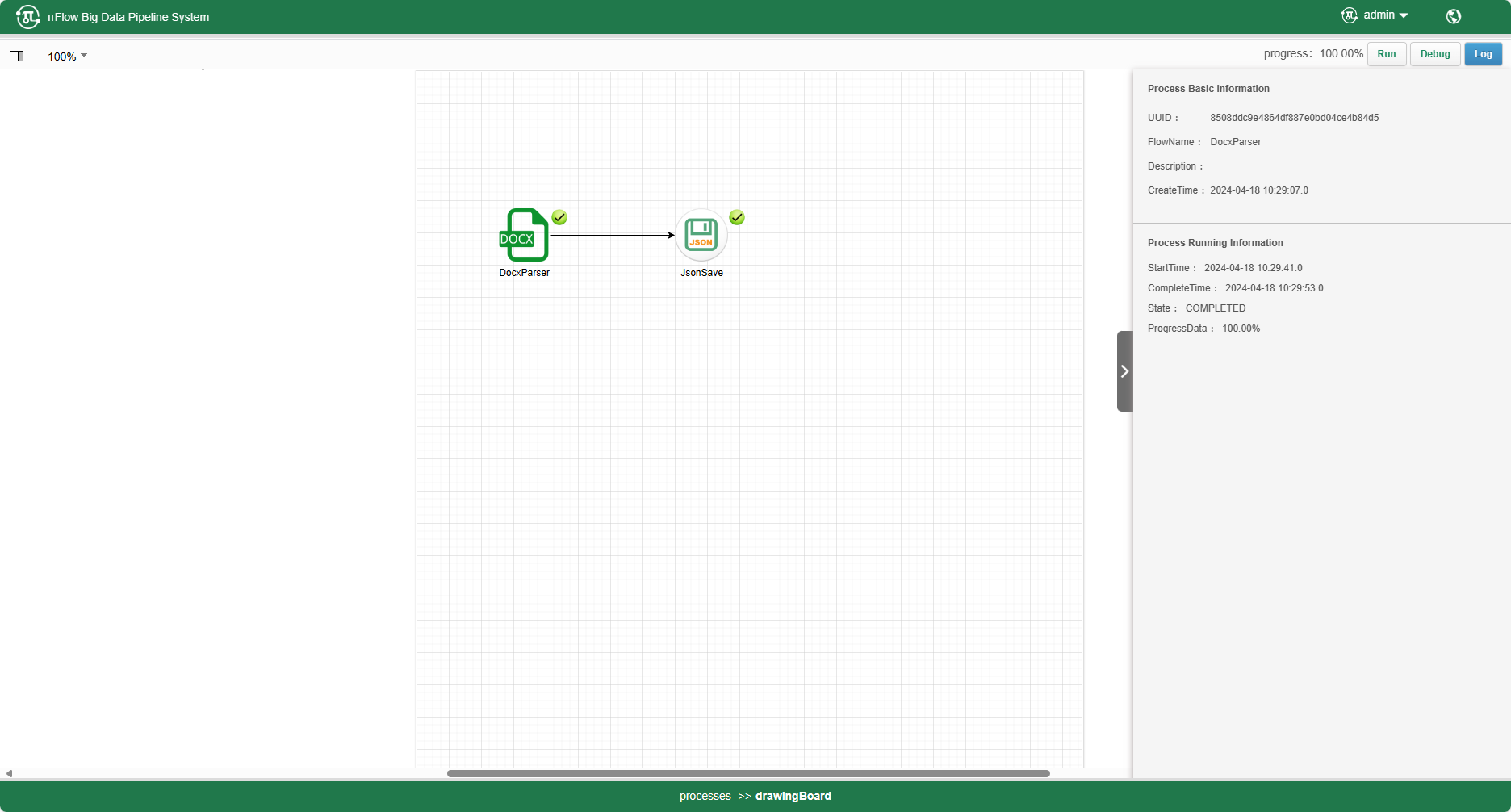
HtmlParser
HtmlParser是用来解析.html或.htm的组件,参数说明如下:

组件样例配置如下:
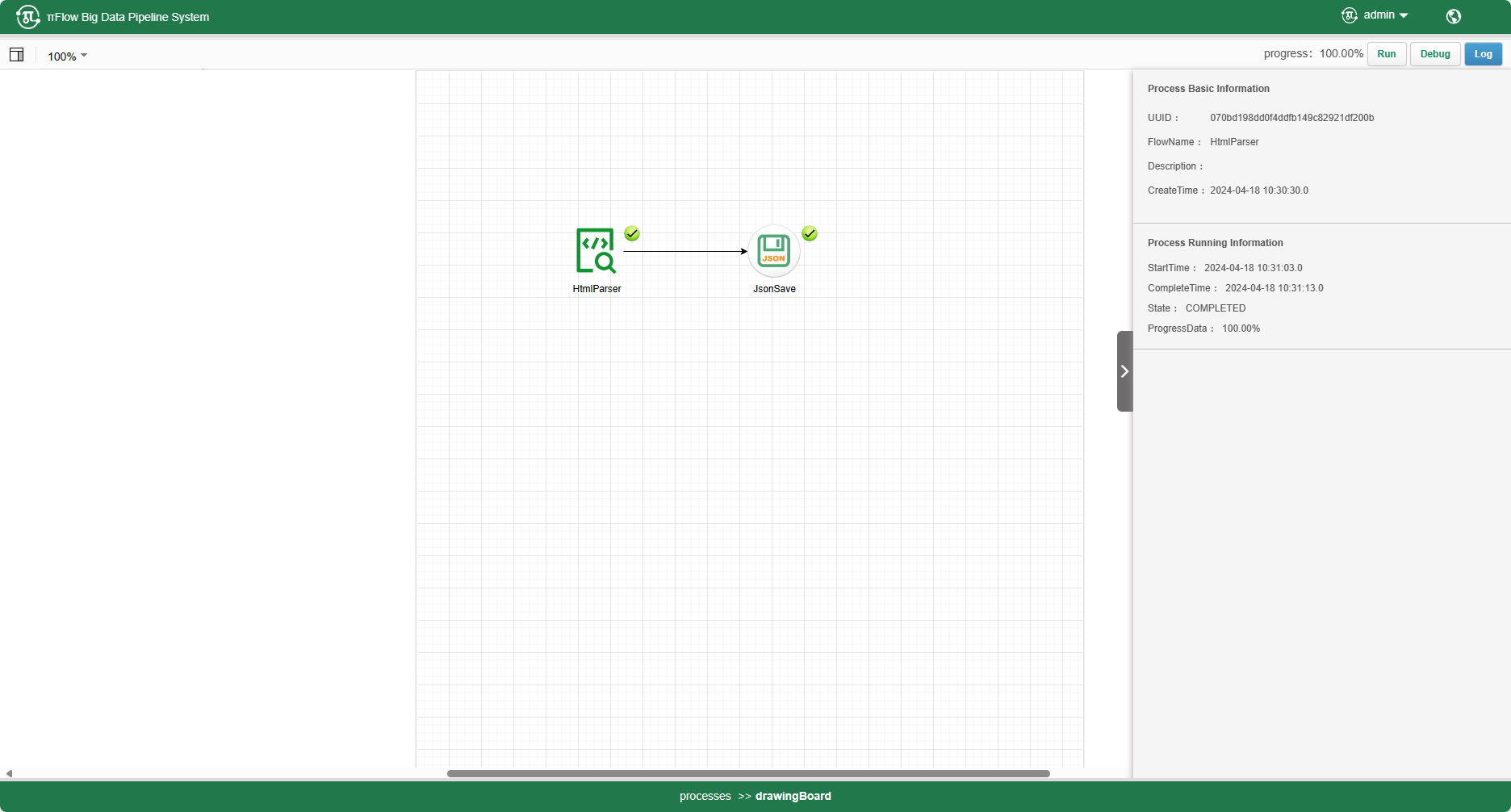
ImageParser
ImageParser是用来解析图片的组件,支持解析.png/.jpg/.jpeg/.tiff/.bmp/.heic,参数说明如下:

组件样例配置如下:
PdfParser
PdfParser是用来解析.pdf的组件,其中strategy参数用来控制解析PDF的策略,可用的策略有:“auto”、“hi_res”、“ocr_only”和“fast”。
- “auto”将根据文档特征和功能属性选择解析策略。如果PDF中含有可提取的文本,“auto”将选择“fast”,否则选择“ocr_only”。“auto”是默认策略。
-
“hi_res”策略将使用detectron2识别文档的布局。“hi_res”的优点是它使用文档布局来获得关于文档元素的附加信息。如果您的用例对文档元素的正确分类高度敏感,我们建议使用此策略。此外,请注意该策略会耗费较长时间。
-
“ocr_only”策略通过Tesseract提取文档。目前,“hi_res”难以为具有多列的文档排序元素。如果您的文档有多个列,但没有可提取的文本,我们建议使用“ocr_only”策略。如果Tesseract不可用并且文档具有可提取的文本,“ocr_only”会回落到“fast”。
-
“fast”策略使用pdfminer提取文本。如果PDF文本不可提取,“fast”会选择"ocr_only"。我们建议在PDF具有可提取文本的大多数情况下使用“fast”策略。
其他参数说明如下:

组件样例配置如下:

PptxParser
PptxParser是用来解析.pptx的组件,参数说明如下:

组件样例配置如下:
二、πFlow已有功能优化
本次发版πFlow共有4个方面的优化,具体包括:
-
Server端H2数据库优化
支持自定义h2数据库的名称。在server的config.properties中添加"h2.name",即可生效。
-
自定义Python组件优化
在自动构建镜像的功能上,摒弃了docker-java的工具类,采用原生java API 实现,提高成功率。但目前仍有需改进的地方,比如构建镜像耗时较长(在线构建过程中不可避免),后续还会通过增加对上传镜像等功能的支持来改进这一问题。
-
模版功能优化
修复了加载模板时自定义算子的参数顺序和保存时不一致的问题;修复了部分算子加载为模板失败的问题。
-
流水线优化
修复了执行过程中某组件失败流水线状态不同步更新问题。
三、相关链接
我们希望通过 πFlow 技术人员和更多大数据领域的有志之士,一起将 πFlow 开源社区打造成国内一流的大数据处理开源社区,欢迎你的加入!
GitHub 地址: https://github.com/cas-bigdatalab/piflow
Gitee 地址: https://gitee.com/opensci/piflo