谁如果能替我省钱,我也会实名制点赞。
都说大模型可以让“人人都是开发者”,但其中最底层的逻辑就在于云计算和许多AI工具的普及,只不过,还有许多人看不清楚而已。
数字化转型是一个不转不行的过程。
那我们做一个简单的假设,如果所有传统企业老板在转型的过程中,都以“一己之力”,那么流程大抵如下:先从大厂挖人做大模型,卷ChatGPT、再卷通义千问;然后发广告、做视频、搞直播,宣传自己的技术如何如何,最后变现。但是毕竟数字化转型是为了管理端和业务端服务的,而非仅仅为了“炫技”。如果你是做新媒体的,这就相当于“曲线求国”了。可话说回来,明明两点之间直线最短,你为什么要走曲线呢?
大模型行业有一个名词叫做“套壳”。从个人角度而言,“套壳”其实并不是什么丢人的事儿,与其反复造轮子,不如借力打力。对于传统行业数字化转型一样,既然知道做大模型成本高、支出贵,那你直接借用成熟的大模型好了;云服务器贵,那你直接上云好了。
一、大模型时代的AI基础设施:云计算
有一位自己创业的朋友用阿里云归档存储,做公司服务器的每周备份。他跟我说过一句话:说白了,效率提高的背后就是AI工具进化了,而AI工具的基础设施就是云计算和云存储。
关于云计算是什么可能不用过多赘述,实际上它就是一种将可伸缩、弹性、共享的物理和虚拟资源池以按需自服务的方式供应和管理,并提供网络访问的模式。在大模型时代,“上云”总是和性价比绑定出场。
像是题主提到的百川智能这类大模型厂商,在其训练模型的过程中大概面对三个共性需求:大规模的算力资源支持、运维易用性和稳定性、模型推理效率和成本。
 图源网络
图源网络大模型这几年确实非常火,但是训练大模型一个逃不开的话题就是“烧钱”,就拿GPT-4来说,其训练规模大概在13万亿个tokens左右,预估的训练成本大概是6400万美元。由于大模型的训练需要消耗大量的GPU计算资源,因此现在许多厂商选择“上云”替代搭建云服务器。尤其是基于阿里云云计算的支持,百川智能建立起了2千卡以上规模集群,可以进行长时间、高效率的模型生产和迭代。之前走“月更”路线的百川智能,现在也开始变成了“半月更”了。
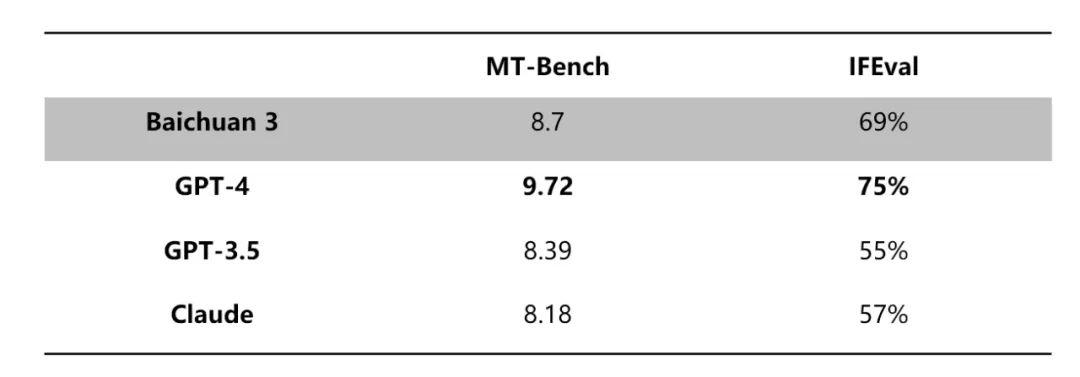 Claude等大模型,图源网络
Claude等大模型,图源网络在MT-Bench、IFEval等对齐榜单的评测中,Baichuan 3超越了GPT-3.5。
由于大模型训练涉及算力、网络、存储、大数据、AI框架、AI模型等多方面技术,因此对于大模型厂商而言,与其自建复杂高性能网络、集群管理和调度系统和AI开发平台,不如将目光转向一体化的AI开发平台。道理很简单,肯德基为什么不让每个门店养鸡、捉鸡、烤鸡,而是要做中央厨房,因为一体化的AI开发平台就像中央厨房,可以简化模型训练流程、支持快速上线、降低运维难度,同时还能实现稳定性。依然拿百川智能举例,据说,百川智能的整体方案基本上可以在2天内完成部署、投入使用,相当于把两个月的活儿缩短到了两天干。

实际上,百川如今走的路正是大模型厂商现在或者是将来要走的。一言以蔽之,大模型训练需要消耗巨大的计算资源,而云计算可以提供弹性资源调度能力,像买燃气费一样按需获取并快速释放大规模GPU集群等硬件资源。这也是为什么阿里云成为了AI时代领先企业的共同选择。
大模型时代,就应该是一个分工合作的时代,各自聚焦擅长的领域,把1+1做到真正的大于2,比如阿里云提供的先进AI、普惠算力都能够成为其中之“1”。
二、如果没有云计算,传统企业何去何从?
传统企业数字化转型的基建变了又变,“三十年河东、三十年河西”,过去云是IT的一部分,但是如今IT是云的一部分。
简单来说,早期的云计算就是IaaS和Paas,用来提供基础的计算资源和服务。但是到今天,云计算的涵义有了延展,它已经成为一个集成了各种先进技术和服务的综合平台。这个平台能够支持从数据处理、存储,到复杂的人工智能应用等一系列功能。下至芯片指令级别,到网络存储、云主机、云服务器,上至云原生架构、微服务架构、大数据技术、数据库技术、容器化部署、Serverless,乃至于视频云服务,以及大型网络数据中心之间的资源调度等等。
 云计算部分产品,图源阿里云官网
云计算部分产品,图源阿里云官网分众传媒和阿里云的结合就是对Serverless的一次探索。
 图源:阿里云官网
图源:阿里云官网分众传媒的核心业务是广告投放与效果展示,尤其是电梯广告,其中包含广告设计、视频处理到投放排期和统计等等。主打的就是静态海报和电梯屏幕广告,用分众传媒自己的话说,城市人口4亿人,其中就有3亿人看分众传媒的电梯广告。
基于阿里云云原生应用架构,支持了手机APP和视频终端等多种业务应用,如员工接入、CRM、视频处理、图片识别、数据上报、数据分析和新兴的视频直播业务。具体来说,比如你告诉Serverless 计算平台,每周六周日有两百万处理量,需要在两天完成,其中高峰是早上九到十点或者下午三到四点,就可以实现资源的自动弹性收缩;同时,也可以提供大规模的识别能力,对于200万张静态电梯海报的每周上刊任务,可以实时监控图片上刊情况,一旦图片放错或放反,系统会自动通知相关人员,确保问题在一小时内得到解决。可以说,用阿里云,让企业开启AI时代领先之道。

三、大模型时代有哪些上云姿势
一个不得不承认的事实是,云计算正在大幅度降低开发者和初创企业的试错成本。云计算提供了一个低成本、高效率的开发环境,让低初级的开发者、初创企业以及传统企业极大地降低了应用开发的试错成本。
用一个直观的例子来说,就是从买“计算机”变成了买“计算”。云计算和云服务从“稀缺资源”变成了像水电煤气一样的基础设施。
概括而言,有两种主要的上云姿势:一种是保守型上云,也就是在较低的成本范围内保证数据的可控性和可用性;另一种则是大刀阔斧式的改革,将底层架构彻底云原生化,虽然成本较高,但是长期来看收益明显。
就拿AIGC产品刚刚冒头的那一次“盛况”——妙鸭相机的刷屏来说,或者至少在我朋友圈的刷屏。其实为什么妙鸭相机生成一个照片,用户需要等待十几个小时,就是因为照片的生成需要大量的GPU算力资源,如果在高峰期大概需要几千台GPU服务器才能满足。用脑子想想也知道,几千台GPU服务器很难线下部署。
 图源网络
图源网络它其实就是阿里云+全球云基础设施在云计算应用的一个很好的例子,在用户获得“美美哒”的写真之前,妙鸭相机需要对用户上传的照片进行微调训练,同时完成短时间的在线推理。而这些工作的完成,都基于阿里云在全球的3000多个边缘计算节点,以及阿里云提供的十万卡以上GPU规模的算力,同时可承载多个万亿参数大模型同时在线微调训练和推理,这样才能保证低延时和高弹性。
当然,之所以说试错成本低,也包括字面意义上的含义。今年年初阿里云全线下调云产品官网售价,平均降价幅度超过20%,最高降幅达55%,涉及100多款产品、500多个产品规格等等。
 图源:阿里云官网
图源:阿里云官网写在最后:
熟悉我的都知道,我自己也会带一些研究生,以前每到他们毕业,都会说一句,希望我们顶峰相见。
到了现在,或许可以说,我们“云”上见。