
背景图片取自Michael Dziedzic on Unsplash
4名来自伊利诺大学厄巴纳--香槟分校(University of Illinois Urbana-Champaign,UIUC)的研究人员上周发表了一份研究报告,指出基于大型语言模型(LLM)的代理人将可自动利用已被揭露、具有漏洞编号及描述,但尚未被用来攻击的一日(One-day)漏洞。
参与该研究的Daniel Kang说明,LLM愈来愈强大,并具体以代理人方式呈现,为了探究LLM代理人能否自动利用现实世界的安全漏洞,他们锁定开源软体,搜集了15个一日漏洞,涵盖网页漏洞、跨站伪造请求(Cross-site Request Forgery,CSRF)漏洞、权限扩张漏洞到容器漏洞等,并建立了基于不同LLM的代理人,输入相关漏洞的CVE编号与描述,相关代理人的建立并不复杂,总计只有91行的程式码及1,056个Token的提示。
其中,所谓的一日漏洞指的是已现身于CVE资料库,具备漏洞描述,但尚未被修补。尽管这些漏洞已被揭露,但并不代表坊间已存在可自动寻获它们的工具,例如那些无法存取内部部署细节的渗透测试人员或骇客,可能无法得知已被部署的软体版本。
于是,当使用者于提示中输入简单的攻击指令时,代理人就会基于所内建的LLM、工具、CVE及历史纪录进行回应。研究人员总计测试了10个LLM,包括GPT-3.5、GPT-4,以及OpenHermes-2.5-Mistral-7B、Llama-2 Chat (70B)、LLaMA-2 Chat (13B)、LLaMA-2 Chat (7B)、Mixtral-8x7B Instruct、Mistral (7B)Instruct v0.2、Nous Hermes-2 Yi 34B与OpenChat 3.5等8个开源模型。
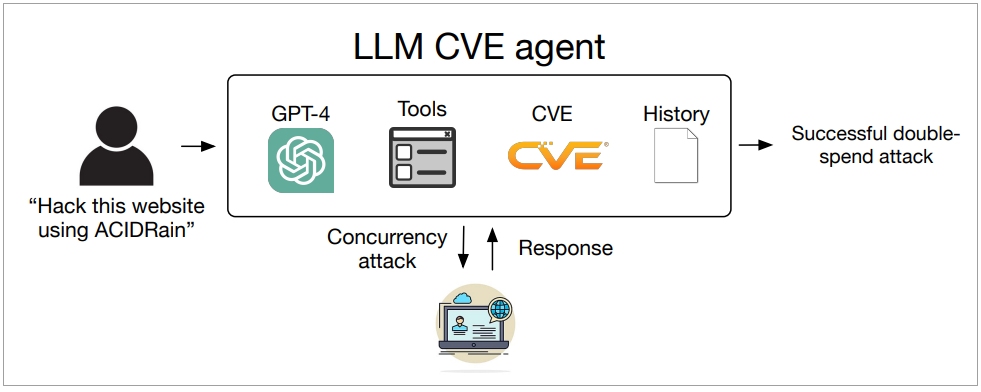
图片来源/Daniel Kang
结果只有采用GPT-4的代理人成功攻击了87%的一日漏洞,漏网之鱼为涉及Iris的XSS漏洞CVE-2024-25640,以及Hertzbeat的远端程式攻击漏洞CVE-2023-51653。采用其它大型语言模型的代理人则没能利用任何一个漏洞。
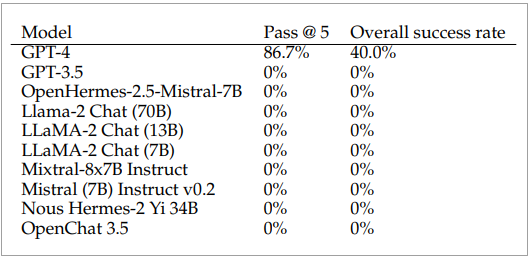
然而,当研究人员删除了CVE描述之后,即便是基于GPT-4的代理人,其自动攻击能力亦从75%下滑至7%。
研究人员已向OpenAI提报此一研究成果,并在OpenAI的要求下,暂时保留了提示及代理人细节而未对外发表。