数据仓库技术一直是企业数据管理的核心,面对日益增长的数据量和多样化的数据类型,数据仓库技术也在不断创新和升级。在吴炳锡老师的演讲中,你可以了解在基础架构发生变革云时代,Databend 如何利用后发优势,面对数据汇聚平台, 利用低成本高效的方式处理海量数据的存储及破除数据孤岛,同时基于海量的数据帮用户实现一个 Data Market 数据集市。
数据汇聚平台的背景及挑战
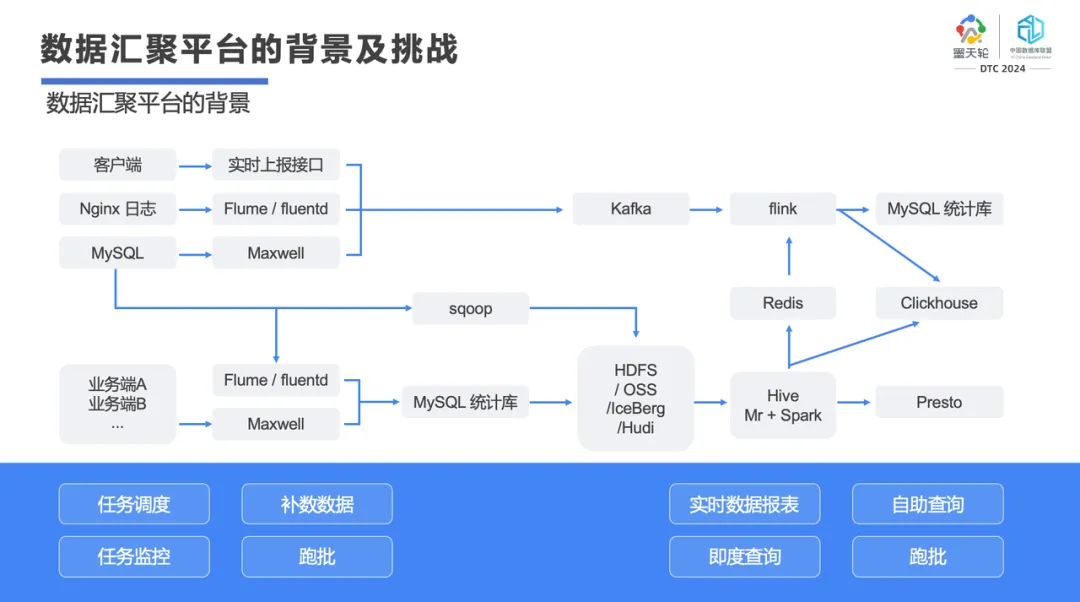
上图是当前很多企业在做数据汇聚平台或大数据平台时常用的架构,包含各种技术栈,可以输出各种好看的图表以及各种内容。但是工程师也很苦逼,各种技术栈让我们眼花缭乱,Oracle、Teradata、Hadoop、 Kafka、Spark、Flink 等等,还有关系型数据库、半结构化、结构化、非结构化数据,甚至包括现在最火的 AI。在这个过程里,我们发现其实每个工程师都在焦虑,很多事情越干越糊涂,挑战越来越多。

以数据搬迁为例,将数据从 a 库搬到 b 库,遇到今天数据不一致怎么办?于是你做了数据重生成,40 分钟、一个小时过去了;还有经常有人问这份数据到底存在哪?你在大数据平台查了一圈后,发现找不到这个数据;一个新同事用一个查询把整个集群资源全干完了,其他人什么也干不了。我们知道一个 SQL 在这种平台里面造成的影响其实是很常见的;在大数据平台里你要做数据汇聚,至少要有 20~30 个技术栈,然后你会发现这些技术栈虽然号称分布式架构,但如果坏一块磁盘,你需要将磁盘从系统里面先删掉,然后重启再加回来。哪怕是一个组件升级或出问题,搞不定的情况下都要全重启一遍。
在大数据里面,大家不管在搞什么,最后都会发现工作很重复根本搞不完。搞数据,搞重启,搞资源恢复,整天就搞这些东西。所以,我们想用一个数据库搞定这些事。我在和朋友刚开始做 Databend 时,当时产品对标的是 Clickhouse。但是,我们发现 Clickhouse 其实很弱,Clickhosue 实质上只是一个查询引擎,数据清洗以及数据流程整理都搞不了。

我们当时其实要解决几个问题:
统一 SQL 接口: SQL 为王,不管用户要什么,都只是一个统一的 SQL 接口;
支持海量数据任意字段查询及任意条件查询: 所有的数据库都要搞分区,查询之前必须带着你的分区键,如果不带这个分区键,所有的 SQL 都搞不过去,甚至有的时候还规定你的分区键必须是数据库的第一个字段,甚至必须是 hint。你会发现要建一张表居然这么难,要记住各种麻烦的规则;
集群扩缩容方便,计算秒级扩缩容: 很多数据库都说可以做分布式扩缩容,但切割机器后发现,在做数据平衡时,两个 TB 的磁盘可能搞了两个小时,如果再拿一个 40T、50T 的节点迁进去的话,可能一个月都搞不平衡;
支持半结构化对象: 半结构化、非结构化、Json 数据的处理,很多人说搞个 ES 吧,但 ES 又贵的不行;
当平台有的函数不支持时,能不能用一个扩展语法来实现,这就要支持外置 UDF,实现二进制的解析;
存算分离: 现在大家经常听到的一个词是 Serverless,其实我们搞湖仓这也是最重要的一点,其中非常重要的基础就是存算分离架构;
支持即席查询: 现在有一些公司里会请很多博士去搞这种事情,他们的查询都很随意,想到什么就搞什么。你要告诉他查询不带分区搞不了,不能把整个集群资源都搞完,他肯定吐槽你。如果一个 SQL 要跑一天,他肯定也不同意,一天时间就在等你这个 SQL 吗?所以我们就要求查询必须要快,要接近实时查询;
资源隔离: 要保证用户做一个即席查询,不能让整个集群资源崩;
流计算的能力处理: 现在很多数据库大部分时间都用来做数据的去重,包括大宽表,数据的加工治理,任务调度能力;
复杂任务友好出错处理机制: 当复杂的处理任务出错了,怎么能友好的通知用户,最好是外挂一个函数能把它搞定。
新一代湖仓 Databend 如何应对?
以上种种,就是我们在做大数据平台时面临的各种各样的挑战。这些挑战就要求我们不能再像 Oracle 或者 PG 那样的路径去走,那么面向云原生我们要如何思考?接下来,我们来看 Databend 是如何应对的。Databend 是 2021 年用 Rust 开发的,在 GitHub 上开源,截止到现在收获了 7200+ Star,平均每个月保持着较快 的增长,项目贡献者大概有 180+。
Databend 支持向量化计算,提升单机计算性能和分布式集群能力。我们从研发 Databend 的 DayOne 起就定义它一定是一个在云上的存算分离架构,它的底层基于对象存储,在上面构建了列式存储引擎,提供了一个更高性能的查询。我们也借鉴了 Git 实现了支持事务和数据回溯特性。因为我们几个创始人原来是从关系型数据库过来的,所以也非常注重 MVCC。在一些传统公司数据清算场景的大数据分析中,因为我们支持事务,所以获得了很多比传统大数据平台更好的性能。

此外,我们支持像 HDFS、Cloud-based Object Storage 等 20 多种对象存储协议。我们还在对象存储上,实现新一代存算分离引擎。我们还内置了 Stream(CDC)+ Task 流式运算及任务调度,实现了流批一体化方案。
Databend 的代码量基本上从第一天到现在接近 30 多万行,代码方面基本上是业界里面评价最高的,团队参与度都还是蛮不错的。
Databend 还支持高弹性+强分布式,致力于低成本地解决大数据分析和复杂度问题。
我们在外面经常讲 Databend 就是 Snowflake 的 Plan B。如果你在正在使用 Snowflake,那么你完全可以选择 Databend 做一个备份,从体验上我们与 Snowflake 基本没有任何体验上的改变,你可以直接对标 Snowflake 去用。
01 Databend 的场景应用方案
1️⃣ 秒级写入场景
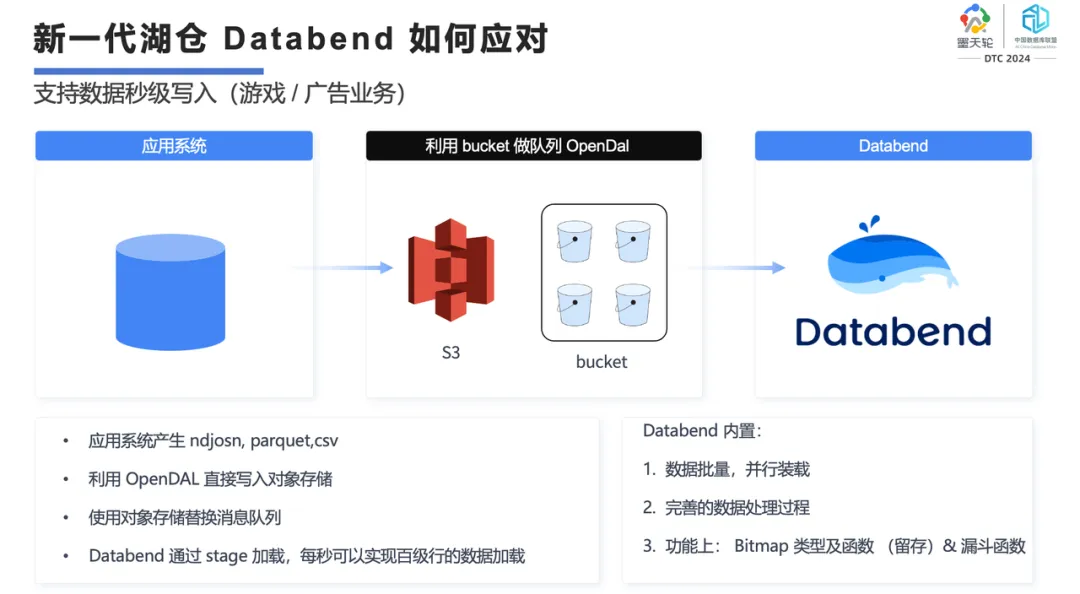
在云上,大家在传统模型下可能还会去构建虚拟机,然后在虚拟机上搭建各种模型。你会发现云上的虚拟机有个问题,实际上所有虚拟机的 SSD 盘吞吐量就 200-300 MB,其实是很慢的。做大数据的话,你如果买云上的这种 SSD 盘实际上是很亏的。而云上的对象存储的吞吐量基本上能到 2-10GB,是本地盘的好多倍。
原来大家在做大数据写入的情况下,会借助 Kafka,再去做 ETL,再到 OLAP 去做分析,现在我们的做法是建议用户直接把数据写到对象存储里,我们可以将对象存储里的数据加载到 Databend 里,然后生成自己的计算引擎。这样我们就简化了整个程序的开发逻辑,可以实现秒级的数据加载。
在这种场景里面,我们基本上能做到每秒钟百万行数据级别的加载,基本上目前所有的数据从进入到可见都不会超过秒级。甚至说用户的一些数据从产生到业务上最终访问可能就是 5 秒,多的话也就十几秒。我们把原来大数据那种 T+1 的,甚至 1 小时的,都能变到秒级。这里面我们也做了如漏斗函数、Bitmap 等,一些复杂的算法也用函数的方式提供给用户。在 Databend 内部可以直接借助 SQL,将原来要做的留存、路径算法都能很好地表达出来。
2️⃣ 流计算方案
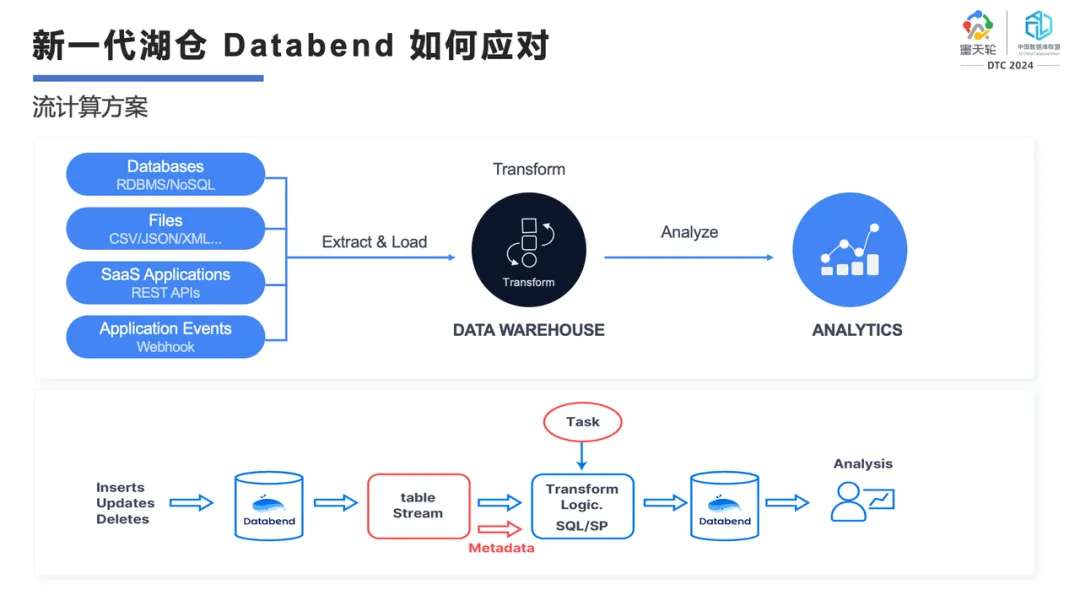
在传统大数据模型里,流计算要借助 Kafka、Spark 或 Flink 才能处理。我们这个方案就会让用户很舒服,可以把数据文件直接抽取到 Databend 内部,写成 JSON、CSV,压缩或不压缩都可以。到了这个位置后,我们会以一个 pipline 的方式把它加载到 Databend 内,实现数据去重和数据打宽,甚至直接去做 join。
3️⃣ ETL 与 ELT
在 Databend 内部可以实现数据的转换,支持增量数据的计算。比如说一个表每次写 100万数据 ,很快这个表就到了亿级别,要如何对增量数据做计算呢?
Databend 可以对这种增量表建立一个 Stream,每次计算只对增量数据做计算。假如增量计算进来 30 万数据,那就只对这 30 万数据进行计算,这样就可以把计算从原来的天级别缩短到分钟级甚至是秒级。所以你会发现,原来可能需要几十台、上百台计算资源去做处理,在 Databend 里可能只需要一个 small 节点就能帮你搞定。通过这种流的方式,把原来大的计算拆成这种小的方案来处理。以前我见过一个公司里面有 40 台 Clickhouse、100 多台前端的接入,加上 Kafka 和数据中转,架构非常复杂。通过 Databend 这套方案,可以把前面那种复杂的架构变得非常简单。
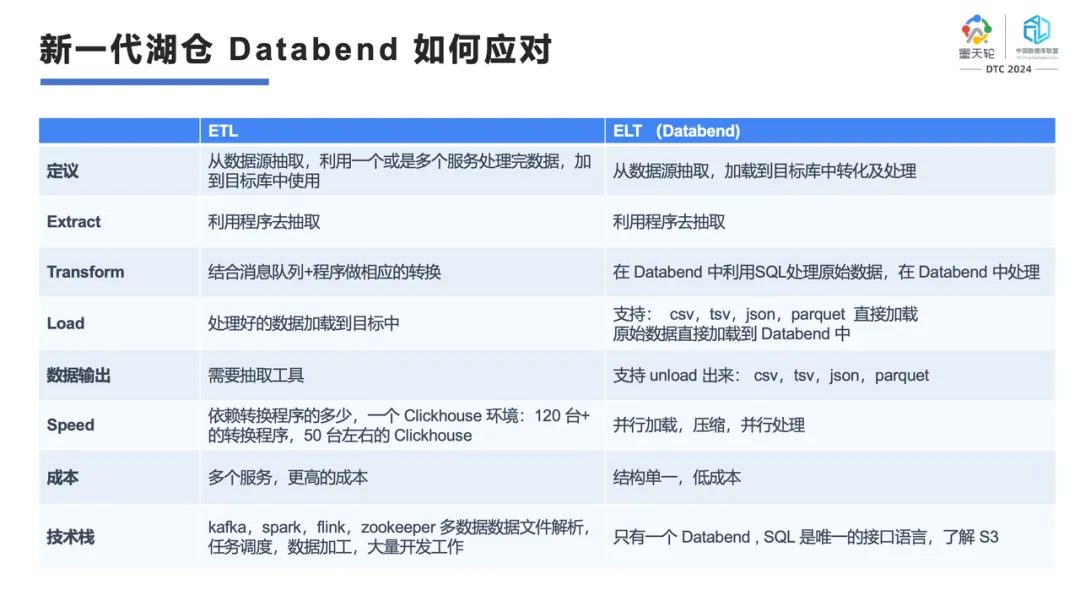
现在网上有一个非常流行的概念 ELT,这是相对 ETL 说的,它建议我们不要在数据库外做那么重的 ETL,可以把所有东西转到数据库里做。那么,转到数据库里做有什么好处?
我们是 Rust 写的处理方式,编译完后就是二进制,比 Java 处理性能高不止一倍,在替换 Hive 的情况下能达到 5 倍以上;
数据中转我们可以更好的批量操作,在程序抽取方面只用利用程序即可简单地抽取出来;
我们支持处理的格式也非常多,CSV、TSV、JSON、Parquet 等都可以直接加载;
数据可以方便地从 Databend 里向外导出,unload 出来成为一个 CSV、TSV、JSON、Parquet 文件,供外部的数据源使用。用户的数据可以很方便的进,很方便的出。
用户处理 1 TB 的数据不到一个小时就搞定了。我们帮一个用户从 AWS 的新加坡区转到了国内的某个云,基本上1 TB 数据一个小时就搞定了;
支持并行加载。并行加载实际上是分布式架构里很有意思的一点,我们的并行加载是按 CPU 的 core 来加载的,如果你的数据集群里面有 200 个 core,那么你的并行任务就可以达到 200。只要你的数据量足够大,并行就足够的快。而且我们有非常好的跟踪日志,能让你看到任务到底用了多少个 core,用了多少时间;
我们的结构很单一。我们的私有部署就是 K8s + 对象存储,你也可以直接使用我们的 SaaS 服务 Databend Cloud。我们的产品就这两种形态,不需要再去关注其他东西,你只需要关注好 K8s helm chart,用 helm chart 做好资源定义,升级的时候用 helm chart 更新就可以直接搞定。在原来的传统部署方式下,你要先找资源再去手工部署,升个级也很痛苦,我们用 helm chart 的方式就搞定了;
从技术栈上来讲,用户只需有一个 Databend,SQL 是唯一的接口语言,稍微了解下 S3,就可以做到很好。
4️⃣ 数据转换典型场景
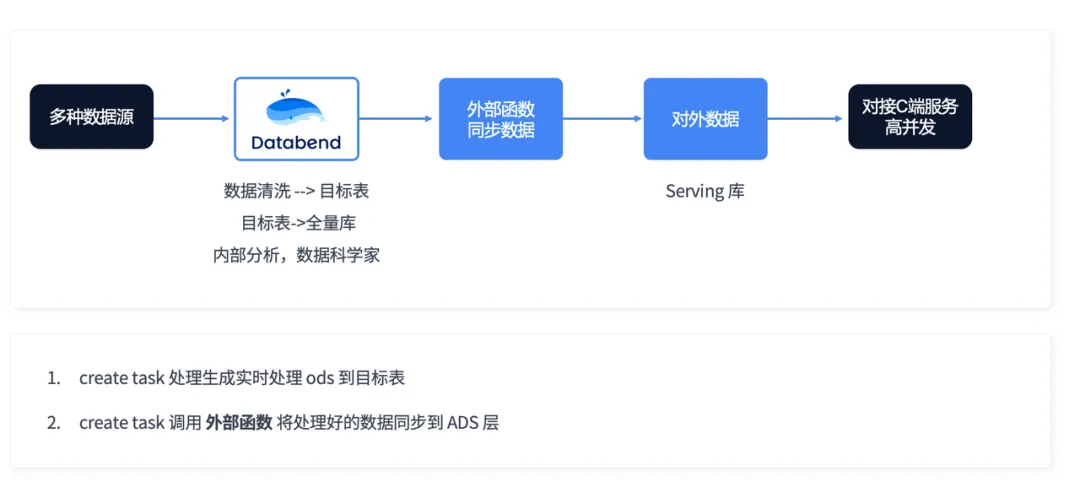
上图是一个海外用户做的模型,我觉得比较有意思。这个公司里面有数据科学家,要很快地对游戏客户或直播间的用户做相应的反馈。比方说榜一大哥来了,在哪个直播间里面互动,这个数据怎么汇总,停留时间什么样。作为后台的运营人员,是需要看到这个数据的,他最终是如何快速搞定这件事的呢?
通过 Databend,多种数据源可以很方便地直接写入对象存储,每秒钟能产生接近 1 万左右的文件,每个文件大概有 100 多行数据,整个加载不到一秒就能进来。进来之后再经过打宽,然后一部分可以直接对外提供服务,另外一部分再同步到生产库。同步到生产库后,我们可以通过调用一个外部的函数做一个通知,然后再把这个数据同步走。
这里面我们解决了几个问题:第一,所有的数据汇总到 Databend 内部,这个数据科学家在 Databend 内部就都可以搞定,不用再去各种地方找数据,原始数据到目标数据生成的全部过程全在这里面;而且所有的东西都是以 SQL 的方式来处理;此外,我们是 Serverless,Databend 在不用的情况下你可以关掉,不再产生费用。你的数据平时是在对象存储里面,对象存储存 1TB 数据一个月,还不到 1000 块钱;另外我们的数据是经过压缩的,通常能压缩到至少三倍以上,有的数据我们甚至能压到 40 到 50 倍。所以平时看起来十几亿、几百亿的数据,在这种模型里都不会特别大,压完之后可能就 50TB。
原来有一些公司里需要有 30 多人的大数据团队,支撑着整个公司的业务发展,每天要各种加班,做数据处理。通过采用这种模型后,公司里面的人员就只需要写 SQL,管理好自己的 SQL 就可以了。
这个东西是我们第一个创建出来的吗?其实也不是,我们也学习了 Snowflake 整个流程的理念、数据管理的理念。为什么我们能更快地做这个事,我们就是朝着 Snowflake 的目标走的,所以我们的整个模型、整个产品的开发也是跟着 Snowflake 的用户来做的。
02 典型案例

上图是去年我们做的几个案例。第一个是 Oracle 到 Databend 的迁移,原 Oracle 中有 740 个表,6.8 TB 数据,我们花了差不多 6 个小时就已经迁完了,每秒钟 100万行的速度。迁移完数据大概在 2TB多,所有复杂查询压到了 5 秒以内。原来它的复杂查询很多是 80 多秒,甚至有的超时查不了,我们用了三个节点就扛了下来。
第二个例子是在数据稽核场景中从 Hive 到 Databend 的迁移。我们在同一行场景中,1 亿行+ 的大表,比 Hive 缩短了两个小时,Databend 亿级数据可以在 5-10 秒搞定。
第三个例子是我们在物流公司里面替换了 Greenplum。现在很多传统公司还在用 Greenplum,它其实蛮好的,但现在在云上,你再用 Greenplum 去搭建的话,一点优势都没有。云上的磁盘其实 IO 吞吐量特别小。你不如换一个 Databend,性能提升绝对在 5 倍以上。
第四个,我们在云上替换了某个医药集团的 CDH。替换完成本下降了80%,并且性能没有任何退化。用户觉得 Databend 特别简单,特别爽,原来整个管理结构很复杂,现在 K8s 加对象存储就搞定了。
03 与 Snowflake 的性能测试对比
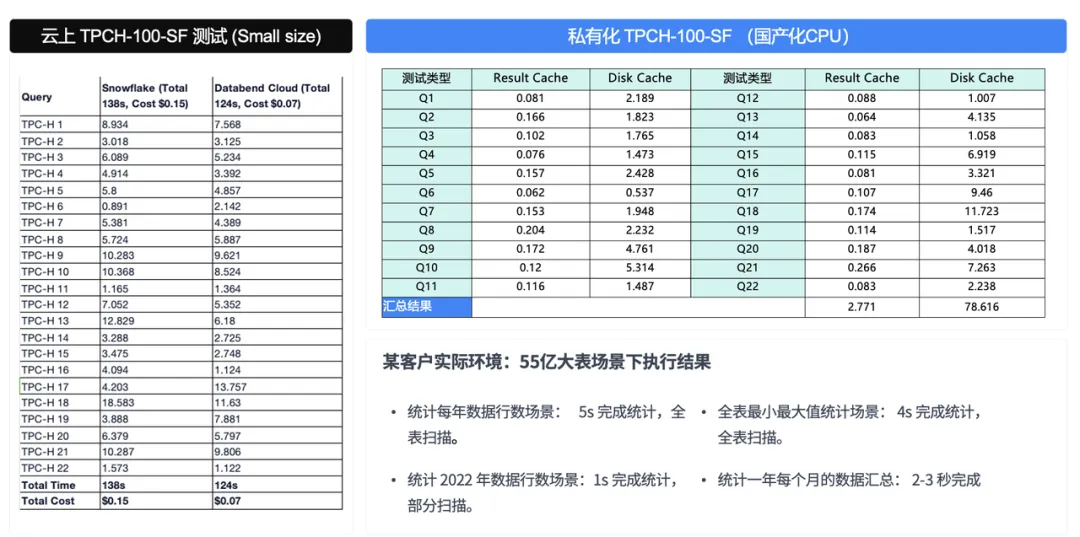
作为一个数据工作者,我现在有一个感触,如果你的查询追求在 100 毫秒以下,你可能不是我们的用户。如果你的查询要求在 100 毫秒到秒级,这就是我们的场景了。因为我们的底层是对象存储,跟对象存储的 100 毫秒交互是省不了的。通过测试,我们在一些国产硬件下,TPCH 大概在 70 多秒。在英特尔 16 核 64G 的情况下,跑一个 TPCH 100大概能跑到 50 多秒,如果再 cache 的话那就更不用说了。
另外大家可以观察一下左边这个图,这是我们在海外的用户做的 benchmark。海外用户已经不再关注它到底跑多快,而更关心你做这件事到底花了多少钱。在同样的 TPCH 测试,我们在 Snowflake 上大概需要花 0.15 美元,在 Databend 上只花 0.07 美元。
这其实就是为什么现在经常看到海外的人已经不参加 TPCC 和 TPCH 协议的测试了。大家更关注到底要花多少钱,而不是说弄了1000 台、10000 台机器去做性能测试。
Databend 整体架构
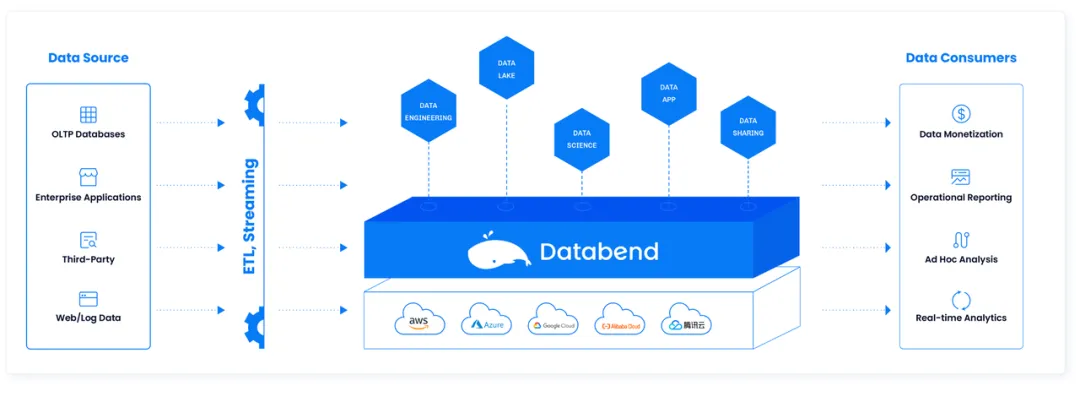
Databend 整体架构中,上层是 meta,中间是 query,底层是计算引擎,最下面是对象存储。meta 层其实我们吸取了很多教训,我们 meta 做得非常轻,里面就是用户数据、用户权限数据和表对应的位置,包括一些事物信息,还有一些加载数据的原数据信息。其他东西一概不存到这里,我们只依赖对象存储来搞定;Query 我们有一个非常方便的分布式计算。这里面我们做的一个创新是放弃了分区的概念,任意字段都有分析型索引和 bloom index 索引,这样的话可以做到任意条件可查。所以我们做 AI to SQL、大模型等这些东西都是非常方便的;Databend 也提供了 AWS、腾讯云、华为云、阿里云相应的 SaaS 服务,大家可以在这些平台上都能搜到 Databend。
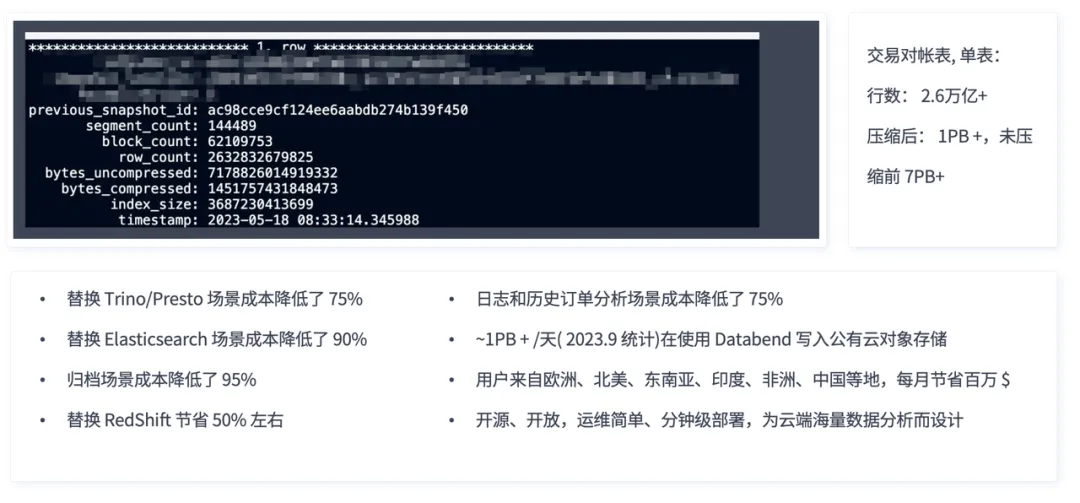
上图是去年一个用户发我的一个截图。这是让我特别震惊的一个产品,因为它的行数已经到了万亿级别了,单表压缩后是 1 个多 PB,没压缩前是 7 个多 PB。大概有 30 多台机器,扛着一个高频交易的订单场景,用来做每天每周每个月的对账。这个用户原来的系统在这么大的数据量情况下,经常对账对不齐。用户看到我们提供了基于对象存储这样的方案后,就替换了原来的系统,发现也跑下来了。这是我们靠技术领先力做的一个非常大的用户。
另外,我们也在替换 Trino/Presto 的场景中帮用户将成本降低了 75%,在替换 Elasticseach 的场景成本降低了 90%,归档场景成本降低了 95%,替换 Redshift 节省 50% 左右成本,在日志和历史订单场景里,我们的成本控制方面都是非常明显的。
上个月有一个用户原来在 redshift 上做报表,整个花费在一个月 3000 美元左右,迁到 Databend 之后,每个月花费不到 200 美元。但是他每个月做数据迁移、数据同步费用大概花 800 美元左右。后面有时间我可以帮他把数据增量部分再搞定,成本还能降到更低,一个月能降到 500 美元以内。
据统计,现在每天有 1PB+ 的数据在使用 Databend 写入到公有云对象存储里面,用户遍及欧洲、北美、东南亚、非洲、印度、中国等地,每月可为用户节省百万美元。
在汇聚平台上构建数据集市
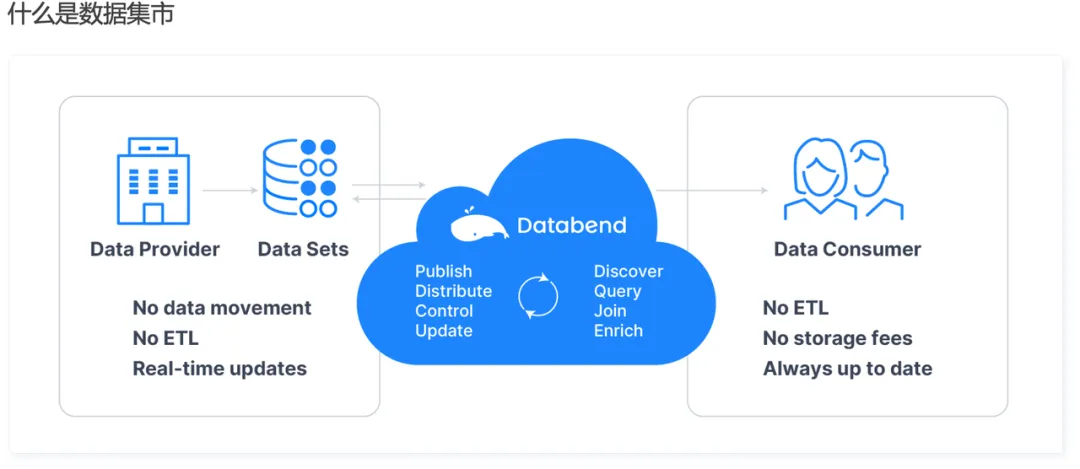
最后介绍的是一个我们做的比较有意思的东西。我们想做一个类似于 Data Market 的东西,但是我们在国内只对部分用户开放,没有向公众开放。在这个数据集市上,一个用户可以发布数据的需求,另外一个用户可以提供这个数据,你可以订阅它。那么,这个东西和传统的数据集市有什么不同呢?
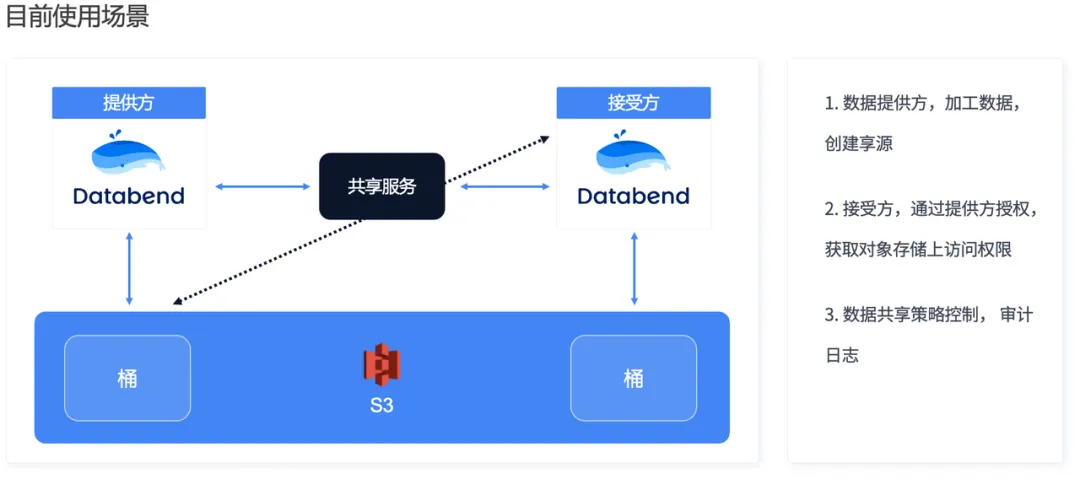
现在大家看到的数据集市更多是数据目录加数据库权限的代理。我们做的数据集市是这样一种机制:你发布完数据后,通过一个共享服务接受方可以通过向提供方请求,提供方给你授权,你可以访问任何数据,但是你不会连到我自己的 Databend 的内部。这样的话,我的节点、我的计算资源是与你隔离的,你想怎么搞是你的事,我只授权了你访问这个数据,你出访问数据的费用也可以,出数据的清洗的费用也可以。
这个模型跑的最好的一个场景是在某个用户的零售商里面。以前他每天的库存必须上传完才能下班,一旦系统出问题了,他就要加班了。现在他可以把每个商店的库存共享给总部,那么总部随时是可以查的,这样他下班就不再成为困惑了。
以下是能公开的一些案例,其中很多都是比较大的用户,像某果手机就是其中之一。另外还有像尼泊尔电信、茄子快传、微盟、多点等。

如果你对 Databend 感兴趣的话,欢迎来体验、试用,点击以下链接,立即试用 Databend Cloud!
https://app.databend.cn/register?utm_source=weixin&utm_medium=article&utm_campaign=dtc2024
关于 Databend
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的新式数仓。期待您的关注,一起探索云原生数仓解决方案,打造新一代开源 Data Cloud。👨💻 Databend Cloud:https://databend.cn
📖 Databend 文档:https://docs.databend.cn/
💻 Wechat:Databend
✨ GitHub:https://github.com/datafuselabs/databend