
本文来自微信公众号:APPSO (ID:appsolution),作者:莫崇宇,原文标题:《苹果开源了!首次公开手机端侧大模型,AI iPhone 的细节就藏在里面》,题图来自:视觉中国
本文介绍了苹果开源的AI大模型OpenELM系列模型,以及苹果在AI领域的最新动向和未来展望。• 💡 苹果发布了OpenELM系列模型,其中包括不同规格和参数量的预训练模型
• 🚀 苹果研究团队提出了Ferret-UI和LLM in a flash等技术,为AI iPhone的发展提供了创新方向
• 🔮 苹果可能在iOS 18中推出全新的AI应用商店,引领手机端AI应用的发展趋势
开源最近成了 AI 圈绕不开的高频热门词汇。
先有 Mistral 8x22B 闷声干大事,后有 Meta Llama 3 模型深夜炸场,现在连苹果也要下场参加这场激烈的开源争霸赛。
近日,苹果宣布在全球最大 AI 开源社区 Hugging Face 发布了 OpenELM 系列模型。
苹果的开源大模型,在行业里什么水平
在介绍苹果的 OpenELM 之前,先对一些热门的开源模型做一个简单的对比:
型号尺寸:
Meta 开发的 Llama 3 模型拥有最大的规模,目前已发布的模型参数数量高达 700 亿。
微软的 Phi-3-mini 模型具有 38 亿个参数,而更大的 Phi-3 系列模型分别拥有 70 亿和 140 亿。
苹果推出的 OpenELM 模型提供多种规格,参数量分别为 2.7 亿、4.5 亿、11 亿和 30 亿。
性能:
在 MMLU 基准测试中,Phi-3-mini 的得分达到了 68.8%,而拥有 30 亿参数的 OpenELM 模型得分仅为 24.8%。
值得注意的是,参数量为 2.7 亿的 OpenELM 模型在 MMLU 上的表现超越了 30 亿参数的版本。
Phi-3-mini 的表现可与 GPT-3.5 等模型相媲美。
预期用途:
Phi-3-mini 旨在实现轻量级、经济实惠的部署,适用于那些处理较小数据集的自定义应用程序。
Meta 的 Llama 3是一个大型的通用语言模型,适用于多种应用场景。
苹果推出的 OpenELM 旨在“赋能开放研究社区”,但该模型也存在潜在偏见。
OpenELM 系列模型涵盖 2.7 亿、4.5 亿、11 亿和 30 亿参数的预训练 OpenELM 模型,以及这些模型的指令调整版本。
论文显示,该系列模型在来自 Reddit、维基百科、arXiv.org 等的 1.8 万亿个代币的公共数据集上进行预训练。

相较于 Grok 1.0 开源的“抠搜”,苹果此次发布了完整的框架,涵盖数据的整理、模型的构建与训练、模型的调整与优化,此外,苹果还提供了多个预先训练好的模型节点和详尽的训练记录等。
基于优化的 Transformer 模型架构,OpenELM 采用了逐层的缩放策略。
在 Transformer 模型架构的每一层中都有效分配参数。通过这种方式,模型可以更好地学习数据,同时避免过度拟合,保持较高的泛化能力。
简单点理解,就是想象有一座多层的图书馆,每一层都放着不同类别的书籍,为了让图书馆运作得更高效,你决定采用“逐层缩放策略”,也就是根据每一层存放书籍的多少来灵活分配图书管理员。

近两年来,业界在一轮轮模型的狂轰滥炸中达成了一定的共识,其中“以小胜大”定律尤为引人关注——经过微调的小模型性能在某些使用场景下未必不如大模型。
与此同时,在商业化这道必答题面前,端侧模型的落地开始变得尤为重要。
去年底,微软发布的 Phi-2 凭借 2.7B 的量级让我们见识到了以小博大的“小小震撼”,在基准测试成绩上更是一举超过当时 Llama 2 7B、 Mistral 7B 等一众先进模型。
本周二微软再次发布的小尺寸模型 Phi-3 参数最小的版本,虽然只有 3.8B,但其性能甚至能与 Mixtral 8x7B 和 GPT-3.5 等模型相媲美。
和 Phi-3 相类似,OpenELM 同样更适合在笔记本甚至在手机上运行。
例如,苹果的论文指出,该模型的基准测试结果是在配备 Intel i9-13900KF CPU、配备 NVIDIA RTX 4090 GPU、运行 Ubuntu 22.04 的工作站上运行的。
为了在苹果芯片上对 OpenELM 模型进行基准测试,苹果还使用了配备 M2 Max 芯片和 64GB RAM、运行 macOS 14.4.1 的 MacBook Pro。
结果显示, OpenELM 模型的性能表现相当不错,比如 OpenELM-3B 在测试知识和推理技能的 ARC-C 基准测试中取得 42.24 得分,而在 MMLU 和 HellaSwag 上,分别得分 26.76 和 73.28。
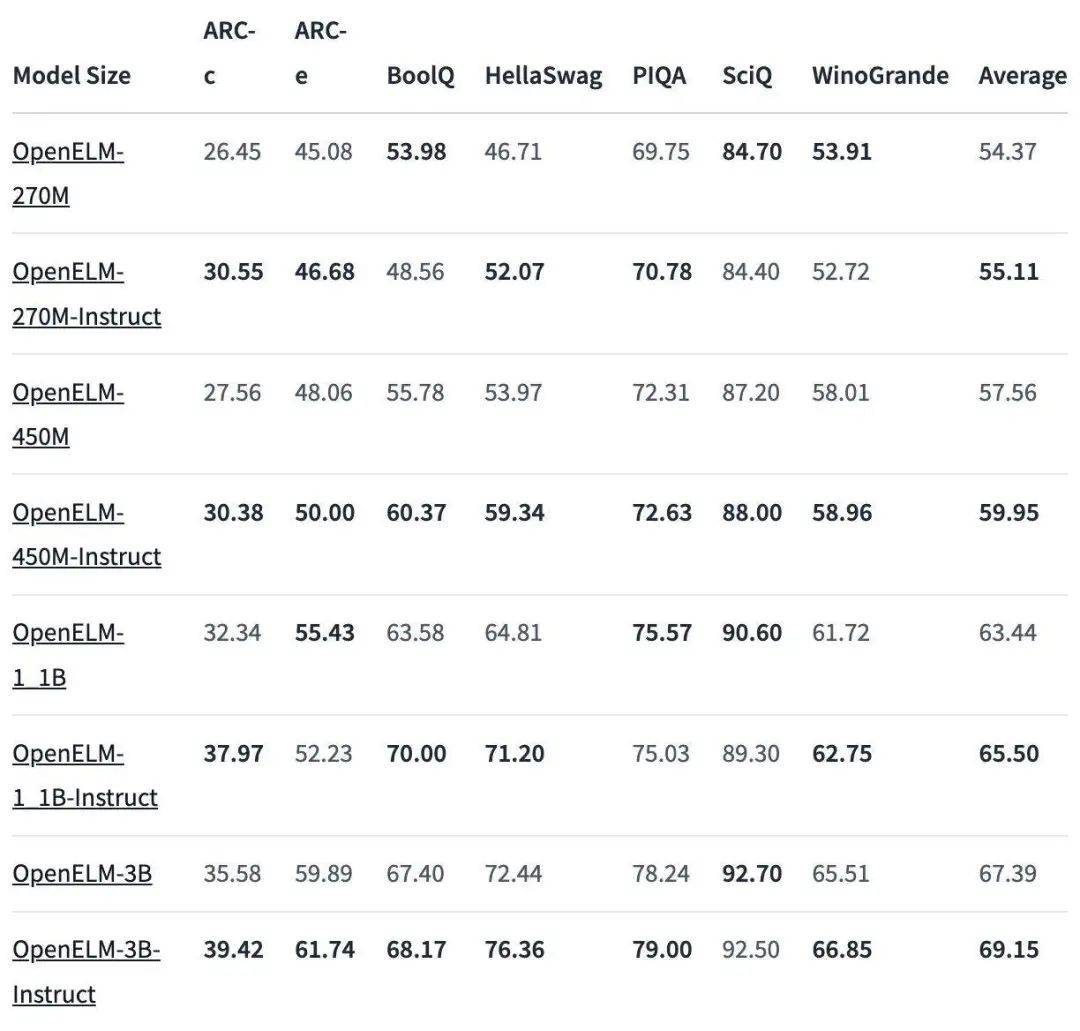
同时拥有 4.5 亿参数的 OpenELM-450M 不光胜在性价比较高,整体的得分表现也相当亮眼。
需要注意的是,苹果在论文中表示,这些模型没有任何安全保证,这意味着,该系列模型依然有可能根据用户和开发人员的提示词产生一些不准确、有害、有偏见的输出。
此外,苹果还开源了深度神经网络训练库 CoreNet,使研究人员和工程师能够开发和训练各种适用于多种任务的模型,如基础模型、物体分类、检测以及语义分割等。
AI iPhone 怎么做?苹果给出了一些答案
在 WWDC24 到来之前,苹果在 AI 领域的每一步举动都备受关注。
翻阅苹果这段时间发布的 AI 论文,几乎都在围绕如何将大模型塞进你的苹果全家桶,而这也是今年 6 月 WWDC24 大会的最大看点。
本月中旬,苹果也发布了一篇名为“Ferret-UI:基于多模态大语言模型的移动 UI 理解”的论文。
其中,Ferret-UI 被描述为一种新的 MLLM,专为理解移动 UI 屏幕而定制,具有“指向、定位和推理功能”。它最大的特点是有一个放大系统,可以将图像放大到“任何分辨率”,使图标和文本更易于阅读。

为了进行处理和训练,Ferret 还将屏幕分成两个较小的部分,将屏幕切成两半。相较于其他大语言模型,传统的更倾向于扫描较低分辨率的全局图像,这降低了充分确定图标外观的能力。
时间再往前拨回到一月份,苹果还发布了一篇将大模型塞进 iPhone 的关键性论文——《LLM in a flash: Efficient Large Language Model Inference with Limited Memory》。
简单来说,研究团队通过尝试用闪存技术优化数据加载、数据块大小,最终实现高效的内存管理。
近两年来,苹果时常为人诟病在 AI 领域动作迟缓,在过往的官方新闻稿中,苹果甚至很少直接提及 AI 一词,相反,他们更倾向于使用“机器学习”等较为保守的词汇。
今年以来,这种偏执开始发生微妙的转变。
无论是库克对于生成式 AI 的频频发声,还是在新款 MacBook Air 新闻稿中将其列为“用于 AI 的全球最佳消费级笔记本电脑”,看得出来大船调转的苹果正在 AII in AI。
当人们谈论人类工作岗位将会被 AI “干掉”时,该论断放在企业的博弈也同样合适,而 AI 的到来正为苹果提供了一个恰逢其时的转型契机。
幸运的是,苹果在 AI 时代默默布局和积累,让其在 2024 年的今天,当我们在讨论 AI 时,依然不能忽视苹果的存在。
作为消费者,我们更关心的是,苹果今年在 WWDC24 上将会带来哪些惊喜?
目前曝光的论文已经略见端倪,其一是大模型进 iPhone 只是时间问题,其二是你的 iPhone 将会变得越来越聪明。
此前彭博社记者 Mark Gurman 也报道称,苹果在 iOS 18 中推出的第一批新 AI 功能将立足端侧,摆脱对云端服务的依赖。
大模型“瘦身”进手机只是开始,打造应用体验才是关键所在。
华尔街咨询机构 Melius Research 主管 Ben Reitzes 曾在接受 CNBC 采访时表示,苹果可能会在 6 月份的 WWDC 上,推出一个全新的 AI 应用商店,预计当中将包括各大供应商提供的 AI 应用。
Reitzes 预测,苹果将在开发者大会上详细说明如何从 App Store 购买 AI 应用程序,并且,全新的 AI 应用商店也会拥有专属的 App、AI 助手以及升级版 Siri。
在 Android 阵营这边,语音助手仍旧是最核心的解题思路,为了让你手机上 Siri 变得更智能,苹果默默耕耘了十三年,而今年,Siri 也将会迎来有史以来最重磅的更新。
鉴于苹果在生成式 AI 领域根基尚浅,此前有消息称苹果为了 AI 不惜考虑要上 Google 等公司的船,这表明 iOS 18 预计不会出现苹果自研 GPT。
苹果花了十年都未能简化的“Hey Siri”,在上个月也有了新的进展。
苹果的 Siri 研究团队在论文《利用大型语言模型进行设备指向性语音检测的多模态方法》中讨论了一种去掉唤醒词的方法。
结果显示,相比于单一的纯文本/纯音频模型,使用多模态系统的 iPhone 能够大幅降低设备指向性语音检测任务上的错误率。
也就是说,继去年 WWDC23 大会宣布省去“hey”之后,未来 Siri 将有机会顺带连“Siri”的唤醒词也一同省略,让 Siri 更加自然地融入到我们的对话之中。
在《MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training》这篇论文中,苹果首次披露一个具有高达 300 亿参数的多模态模型。
MM1 的多模态能力倘若被集成到 iPhone 上,预计 iPhone 将能够通过视觉、语音和文本等多种方式理解并响应用户的需求,
例如,OCR 功能的增强,iPhone 用户能够更方便地从图片中提取文字信息;而多图像推理和思维链推理的能力,则能提升用户与 Siri 的对话质量。
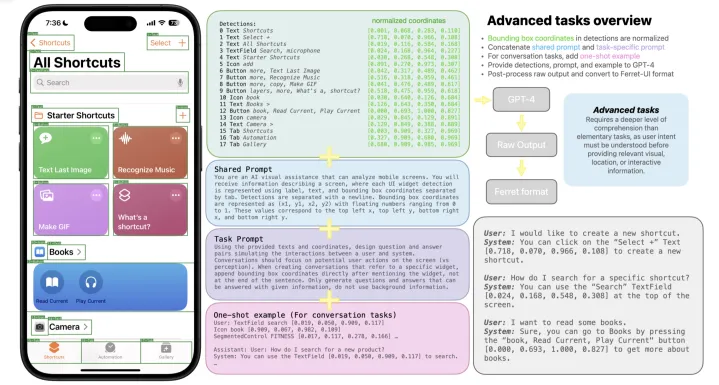
此外,上文提到的 Ferret-UI 模型能准确识别和定位屏幕上的各个元素及其功能,反过来赋能到 Siri 上,将有望提升响应用户指令的准确性。
想象一下,当 iPhone 能够将整个 UI 界面转化为清晰的语音描述时,或者提供精确的语音操作指引,甚至能够对复杂的功能进行详细的讲解,也能为视障人士、老年人或是儿童带来极大的便利。
当然,理想与现实之间,毕竟隔着一条名为“实践”的河流,最终的“One more thing”,还需在 WWDC24 的舞台上揭晓。
本文来自微信公众号:APPSO (ID:appsolution),作者:莫崇宇