今天,苹果破天荒整了个大新闻。
苹果开源了一个在设备端运行的AI模型OpenELM,同时还公开了代码、权重、数据集、训练全过程。
就像谷歌、三星及微软着力在PC和移动设备端推动生成式AI模型的开发一样,苹果也加入了这一行列。这是一个新的开源大语言模型(LLM)家族,能够依托单一设备平台运行,完全无需借助云服务器。
OpenELM已经于日前在AI代码社区Huggang Face上发布,由多个旨在高效执行文本生成任务的小模型组成。
苹果投身开源AI战局,在Hugging Face上发布四种新模型!
OpenELM模型家族共有八位成员,其中四个为预训练模型,另外四个为指令微调模型,参数规模在2.7亿到30亿之间(即大模型中人工神经元之间的连接数量,参数越多通常意味着性能更好、功能更强,但并不绝对)。而微软Phi-3模型为38亿。
预训练是让大模型得以生成连续、可用文本的重要方法,而指令微调则能够让模型以相关度更高的输出响应用户的特定请求。具体来讲,预训练而成的模型往往会通过在提示词的基础上添加新文本来完成要求,例如面对用户的“教我如何烤面包”这条提示词,模型可能并不会给出分步说明,反而傻傻回答称“用家用烤箱烤”。而这个问题恰好可以通过指令微调来解决。
OpenELM通过采用层级缩放策略、在公开数据集预训练后微调,实现了Transformer语言模型效果的改进。因此,OpenELM 的transformer layers不是具有相同的参数集,而是具有不同的配置和参数。这样的策略能让模型精度显著提高。例如,在大约十亿参数的预算下,OpenELM的准确率较OLMo提升了2.36%,且预训练所需的Token数量减少了一半。
苹果在其所谓“示例代码许可证”下发布了OpenELM模型的权重,以及训练中的不同检查点、模型性能统计数据以及预训练、评估、指令微调与参数效率调优的说明。网友点评说,“可以说对开发者来说很友好了,毕竟深度网络的很大一部分难点存在参数调节。”
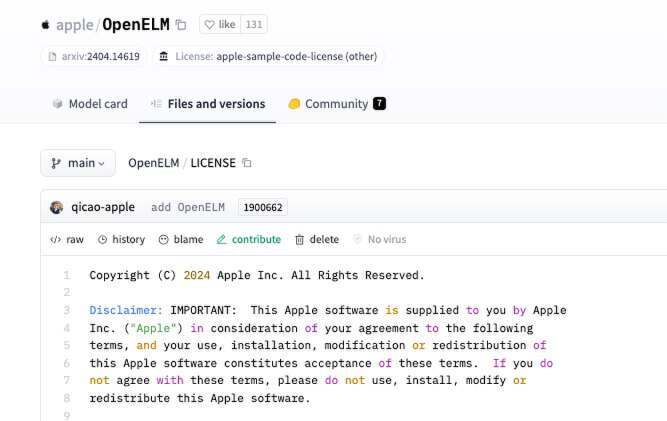
苹果的示例代码许可证并不禁止商业使用或修改,仅要求“如果您以完整且未经修改的方式重新发布苹果软件,则必须在所有此类发布中保留本通知以及以下文本与免责声明。”
该许可不是公认的开源许可证,虽然苹果也没有做过度的限制,但它确实明确表明,如果任何基于 OpenELM 的衍生作品被认为侵犯了其权利,苹果保留提出专利索赔的权利。
苹果公司还进一步强调,这些模型“不提供任何安全保证。因此,模型可能会根据用词提示词生成不准确、有害、存在偏见或者令人反感的输出。”
OpenELM只是苹果公司发布的一系列令人惊讶的开源AI模型中的最新一批。去年10月,苹果方面曾悄然发布具有多模态功能的开源语言模型Ferret,迅速引起各界关注。
目前,大模型领域主要分为开源和闭源两大阵营。闭源阵营的代表企业包括 OpenAI、Anthropic、谷歌、Midjourney、Udio、百度、科大讯飞、出门问问、月之暗面等。开源阵营的代表企业包括 Meta、微软、谷歌、百川智能、阿里巴巴、零一万物等。这些企业致力于开放大模型的技术和代码,鼓励开发者和研究人员参与模型的开发和改进。
苹果长期以来一直以神秘莫测、对外“封闭”而闻名,本次却罕见地加入开源大模型阵营。以前,除了在网上发布模型和论文之外,苹果并未公开宣布或者讨论其在AI领域的探索。
关于OpenELM,我们了解什么?
尽管OpenELM(全称为开源高效语言模型)才刚刚发布、尚未进行过公开测试,但苹果在Hugging Face上指出其目标是在设备端运行这些模型。这明显是在紧跟竞争对手谷歌、三星和微软的脚步——微软本周刚刚发布了能够纯在智能手机端运行的Phi-3 Mini模型。
在arXiv.org上发表的一篇模型阐述论文中,苹果表示OpenELM的开发“由Sachin Mehta领导,Mohammad Rastegrai与Peter Zatloukal则额外做出贡献”,该模型家族“旨在增强并赋能开放研究社区,促进未来的研究工作。”
苹果的OpenELM模型分为四种规模,分别拥有2.7亿、4.5亿、11亿与30亿参数,各模型均比现有高性能模型更小(通常为70亿参数)且各自拥有预训练与指令微调两个版本。
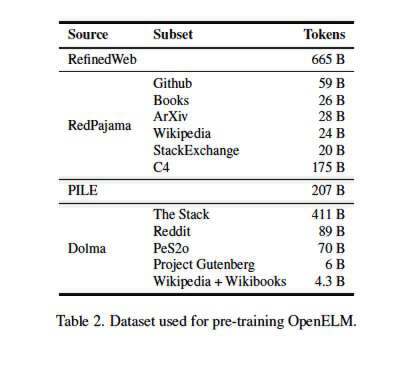
这些模型的预训练采用来自Reddit、维基百科、arXiv.org等网站总计1.8万亿tokens的公共数据集。
OpenELM模型适合在商用笔记本电脑甚至部分智能手机上运行。苹果在论文中指出,他们分别在“配备英特尔i9-13900KF CPU、64 GB DDR5-4000 DRAM和24 GB VRAM的英伟达RTX 4090 GPU,运行有Ubuntu 22.04的工作站上”、以及“配备M2 Max系统芯片与64 GiB RAM、运行有macOS 14.4.1的苹果MacBook Pro上”运行了基准测试。
网友测试运行OpenELM模型
有趣的是,新家族中的所有模型均采用分层缩放策略来分配Transformer模型中每一层内的参数。
据苹果公司介绍,这种方式能够提供更加准确的结果,同时提高计算效率。该公司还使用新的CoreNet库对模型进行了预训练。
该公司在Hugging Face上提到,“我们的预训练数据集包含RefinedWeb、去重版PILE、RedPajama的一个子集以及Dolma v1.6的一个子集,总规模约1.8万亿个tokens。”
值得肯定,但性能并非顶尖
在性能方面,苹果公布的结果显示OpenELM模型相当出色,特别是其中的4.5亿参数版本。
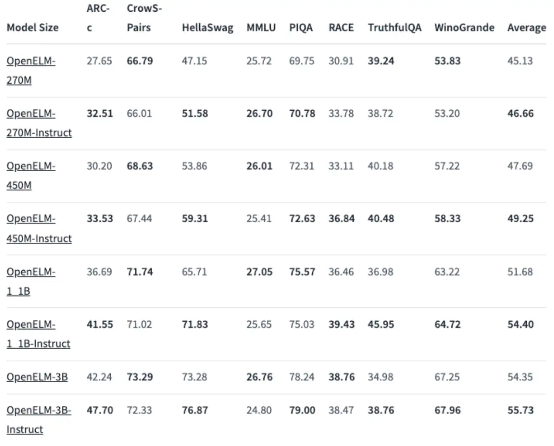
此外,11亿参数的OpenELM版本“比拥有12亿参数的OLMo模型性能提高了2.36%,且需要的预训练tokens仅为后者的二分之一。”OLMo是艾伦AI研究所(AI2)最近发布的“真正开源且最先进的大语言模型”。
而在强调测试知识与推理技能的ARC-C基准测试中,经过预训练的OpenELM-3B版本的准确率达到42.24%,同时在MMLU与HellaSwag上分别得到26.76%与73.28%的成绩。
一位参与该模型系列测试的用户指出,苹果的模型成果似乎“稳定且性能一致”,就是说其响应结果并不具备灵活的创造力,也不太可能冒险涉及“不适合上班时浏览”的内容。
竞争对手微软近期推出的Phi-3 Mini拥有38亿参数及4k上下文长度,目前在性能层面仍处于领域地位。
根据最新发布的统计数据,Phi-3 Mini在10-shot ARC-C基准测试中得分为84.9%,在5-shot MMLU上得分为68.8%,在5-shot Hellaswag上得分为76.7%。
但从长远来看,OpenELM肯定还会继续得到改进。目前开源大模型社区对于苹果的加入非常兴奋,也期待看到这位“闭源”巨头如何将其成果引入于各类应用场景。
大模型是智能手机的未来
手机厂商们都很看好手机上的AI前景。
高通和联发科等公司已推出了智能手机芯片组,可满足人工智能应用所需的处理能力。此前,许多设备上的AI应用实际上是在云端进行部分处理,然后下载到手机上。但云端模型也存在弊端,如推理成本很高,一些 AI 创业公司训练+生成一张图片的成本可能就要一元。而先进的芯片和端侧模型则会推动更多AI应用程序在手机端运行,节省成本的同时,也能给用户带来更好的实时计算能力,从而催生出新的商业模式。
从ChatGPT火爆至今不过一年左右,手机厂商就都已将AI大模型技术落地在自家手机中。
今年三星新发布的 Galaxy S24 系列上搭载了能处理语音、文本、图像的端侧 Galaxy AI。谷歌也发布了一款搭载自家 AI 模型的手机 Pixel 8 系列,该设备搭载了 Gemini Nano。谷歌 Pixel 部门产品管理副总裁 Brian Rakowski 还表示谷歌最先进的大模型也会于明年直接登陆智能手机,“我们在压缩这些模型方面已经取得了相当多的突破。”
国内头部手机厂商也争相布局。小米于去年10月发布了澎湃OS以及小米自研大模型加持的各类应用;vivo 也去年宣布推出了蓝心大模型,并开源了面向手机打造的端云两用大模型 BlueLM-7B;OPPO 也在去年11月发布了安第斯大模型(AndesGPT),以“端云协同”为基础架构设计思路,推出了多种不同参数规模的模型规格。
今年世界移动通信大会MWC 的一大亮点也是大模型能够在设备本身上本地运行,“这就是最具颠覆性的地方。” CCS Insight 首席分析师 Ben Wood 感叹。在这次大会上,还展示了一些未来AI概念手机,比如德国电信和 Brain.ai 完全放弃App而采用 AI 界面的T phone。因此,也有预测认为,随着AI占领我们的智能手机,App时代的终结可能指日可待,从而带来全新的生态和竞争格局。"
手机大模型之战,此前只差苹果,而现在,苹果终于带着它的开源大模型来了。
参考链接:
https://www.infoq.cn/article/h2ceezfmjdbo2epareyh"