
本文来自微信公众号:新硅NewGeek(ID:XinguiNewgeek),作者:董道力,编辑:张泽一,题图来自:视觉中国
“写遗嘱的时候错过了deadline怎么办?”
“怀念过去是不是在时间的长河里刻舟求剑?”
“英语听力考试总是听到两个人在广播里唠嗑,怎么把那两个干扰我做题的人赶走?”
以上这些饱含哲学但好像又莫名其妙的问题,出自百度贴吧“弱智吧”2023年年度精选,看似毫无逻辑,但仔细一想好像确实又有点道理。
就像天才吧里没有天才,弱智吧也不收真弱智。然后,它就成为了训练AI中文能力的最佳素材。
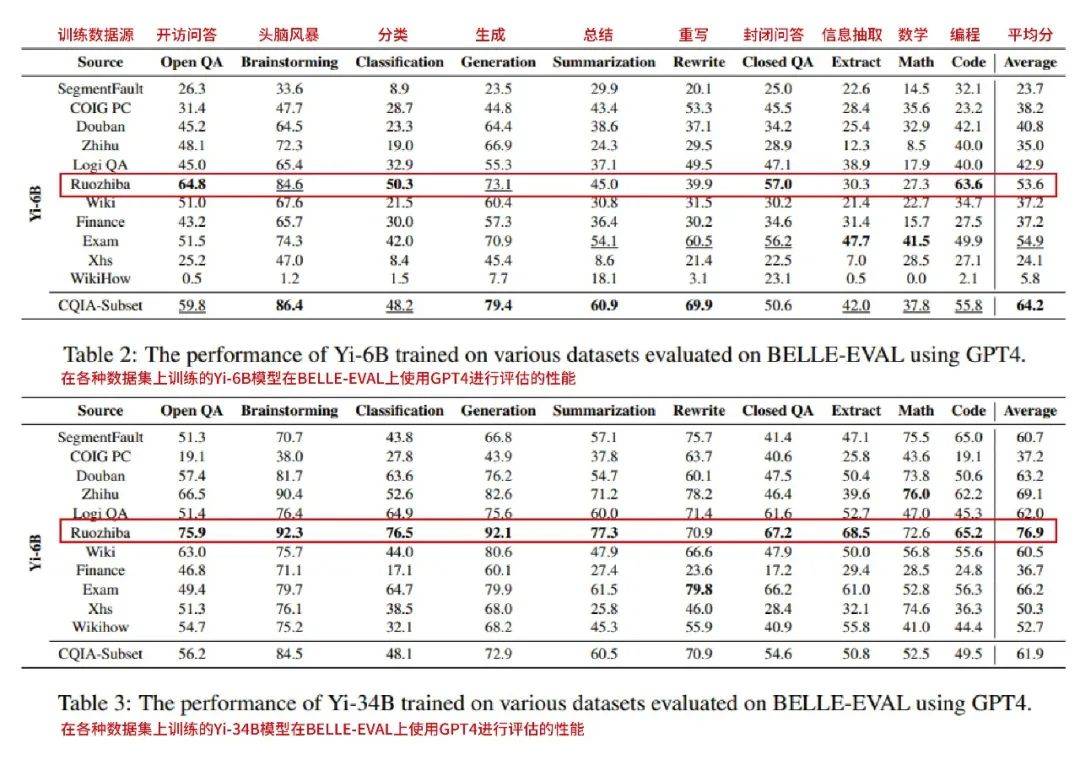
前几天看到一篇中科院牵头的论文,简单来说就是精选了一些中文互联网的语料库喂给各种零一万物的Yi大模型,让它们更加熟悉中文语境的互动。
经常在网上冲浪的朋友们应该都知道,中文互联网博大精深,豆瓣、小红书、微博、贴吧、知乎等等早就各自有一套独特的语言习惯,这些语料库的素材截然不同,训练出来的模型能力也就有所差距。
最终,在GPT-4的打分下,弱智吧训练出来的模型夺冠。
具体来看,在6B小模型上,弱智吧训练出来的模型在开放问答、分类、封闭问答和编程能力上较为突出。
而转战到34B大模型上,弱智吧训练的大模型成绩一骑绝尘,在8项能力中排名第一,平均分也远超其他平台训练出来的模型。
这很难评,弱智吧难道就是最优质的中文语料库?

我们不妨先看看在面对弱智吧问题的时候,各个模型的表现。
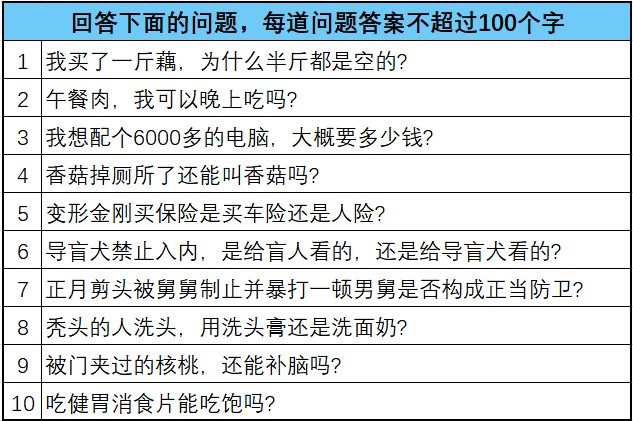
本次受害大模型分别是ChatGPT-3.5、Gemini、文心一言和Kimi,测试方法是让大模型理解弱智吧的典型问题,并要求他们模仿写一个类似的问题出来。
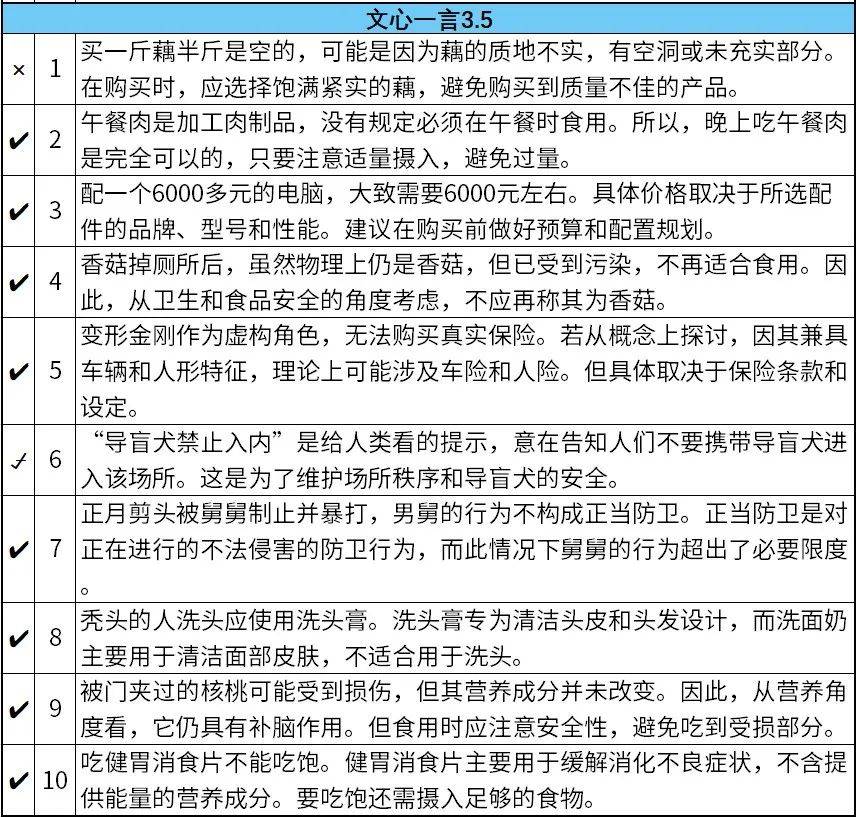
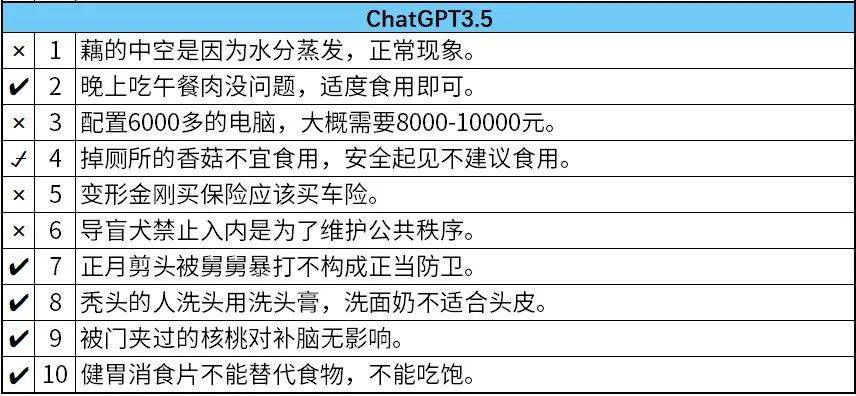
国产大模型对弱智吧的问题有更好的理解,Kimi和文心一言回答的准确率较高,能答对8道题,答错和半错半对各1道。分别在“我想配个6000多的电脑,大概要多少钱?”和“我买了一斤藕,为什么半斤都是空的?”上栽了跟头。
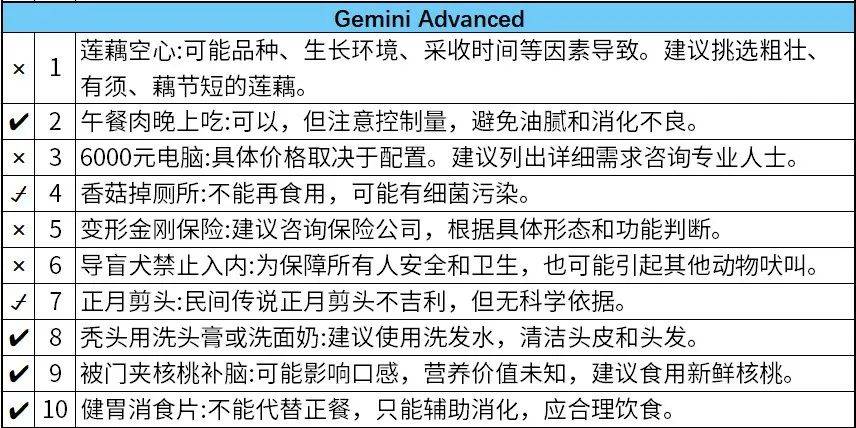
谷歌的Gemini和Open的ChatGPT-3.5可能因为水土不服,准确率较低。
ChatGPT-3.5甚至认为变形金刚应该购买车险,不知道是专属的幽默还是没看懂这道题。6000元的电脑要花8000~10000元,也属于错得比较离谱的了。

除了答不上来弱智吧的问题,AI也写不出弱智吧的帖子。弱智吧的帖子高度抽象,各种修辞、脑洞和梗,普通人想一个都需要随缘,一板一眼的AI更难想出来了。
同样,作者尝试让ChatGPT-3.5、Gemini、文心一言和Kimi学习上文提到的弱智吧的10个问题,模仿写几个问题出来。



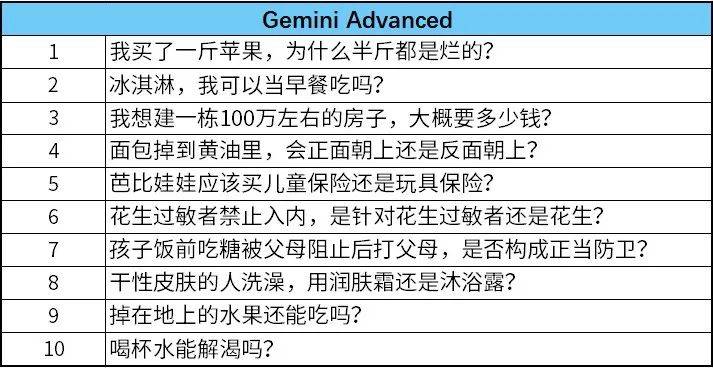
几个大模型写出来的问题都不太行,基本上都是对弱智吧问题拙劣的模仿。
像“我晚上想吃烧烤,早餐可以吃吗?”“掉在地上的冰淇淋,还能叫冰淇淋吗?”“在电梯里放屁被邻居投诉,我是否有权利保持沉默?”等,在形式上和弱智吧的问题一样,但都没有掌握问题的精髓——逻辑。
可以说,弱智吧里的内容,AI看不懂也写不出。
为什么强大的AI就搞不定弱智吧呢?可能源于弱智吧独有的脱离日常的逻辑,弱智吧的吧友非常擅长从日常生活中找到漏洞,并加以利用。
比如,午餐肉能不能晚上吃?香菇掉厕所了还能叫香菇吗?老鼠生病了可以吃老鼠药吗?精神分裂在调查问卷里算一个样本还是两个样本?
除了这些流出的让人会心一笑的问题,弱智吧内还有不少富含哲理的帖子。
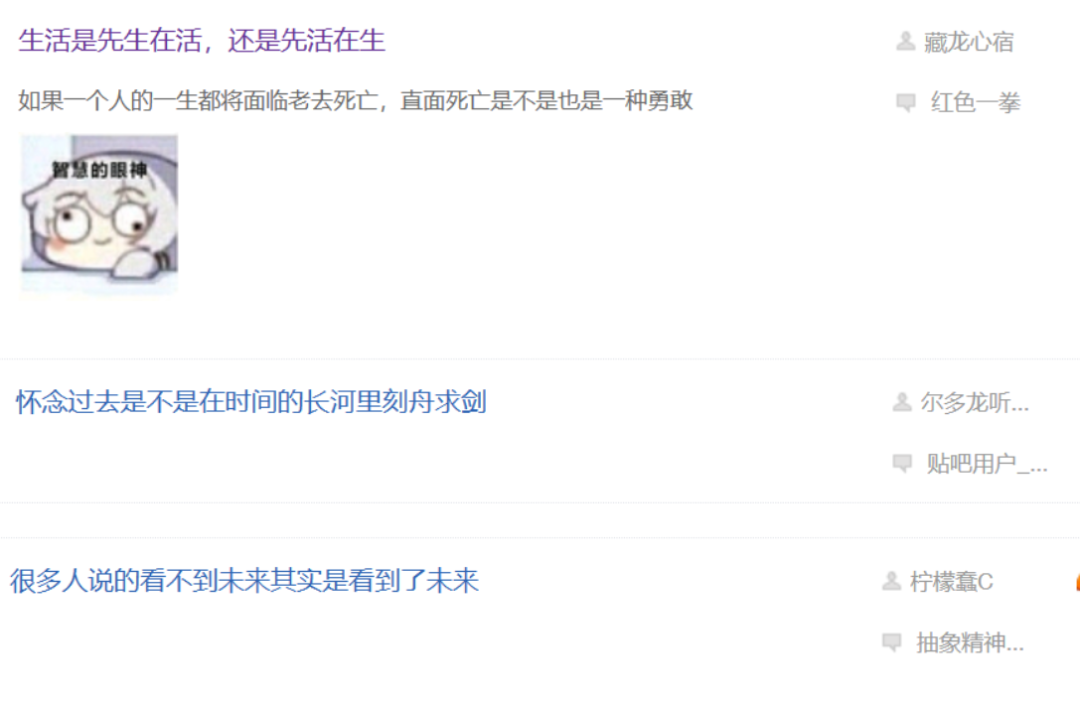
也有诗人在弱智吧里冒充弱智写诗,用最简短的句子,给网友带来最强的杀伤力。
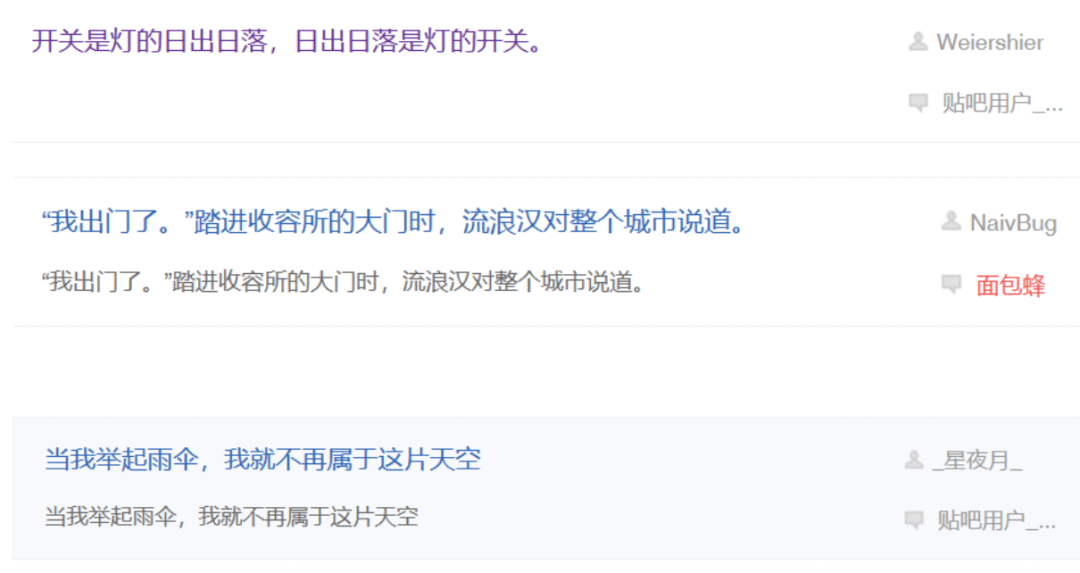
弱智吧的内容常用“逻辑反推”“谐音双关”“跨服聊天”等手法生成各种离谱的段子或幽默又带有思考的句子。普通人想看懂弱智吧里的问题也要思考一下,找到问题里的梗,更别说AI了。
这也就是为什么弱智吧会成为人类在AI面前最后的堡垒的原因。
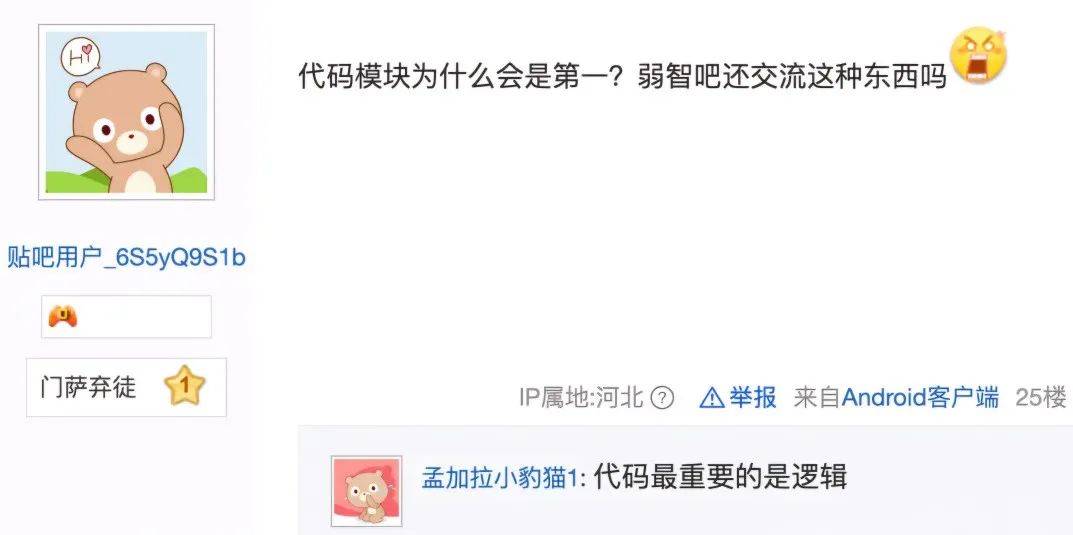
有人吐槽,弱智吧训练出来的模型,编程能力为什么那么高,吧里也没人在搞编程啊。随后有吧友回复道出秘密:编程最讲究逻辑,弱智吧最不缺逻辑。
纵观整个中文互联网平台,都在讲文章的可读性,如何让读者读下去。
知乎上的热帖,先要下飞机,再讲故事,最后引申到主要话题。小红书上的热帖,先喊你一声家人,再给你充足的情绪价值。弱智吧不一样,内容的可读性几乎没有,就一句话,需要读者反复思考,才能看懂作者想要表达的内容。
比如你问:“今天天气怎么样?”
知乎网友会告诉你:“谢邀,刚下飞机,纽约的太阳很大,刚刚拒绝了一个200w年薪的工作。”
小红书网友回你:“家人们,谁懂啊,今天太阳晒死我了,大几千的防晒也没用。”
而弱智吧吧友会说:“太阳翘班了,云正在赛跑。”
正是这样非常抽象的逻辑,才是人类与AI区别最大的地方,也是AI目前学不会的。
当然,其他中文社区不用气馁,也可以发挥特点构建自己的堡垒,比如知乎可以教AI地理,让它搞不清越南到底是哪个国家。
本文来自微信公众号:新硅NewGeek(ID:XinguiNewgeek),作者:董道力,编辑:张泽一