单机容器网络
这里以 docker 为例进行分析
原理
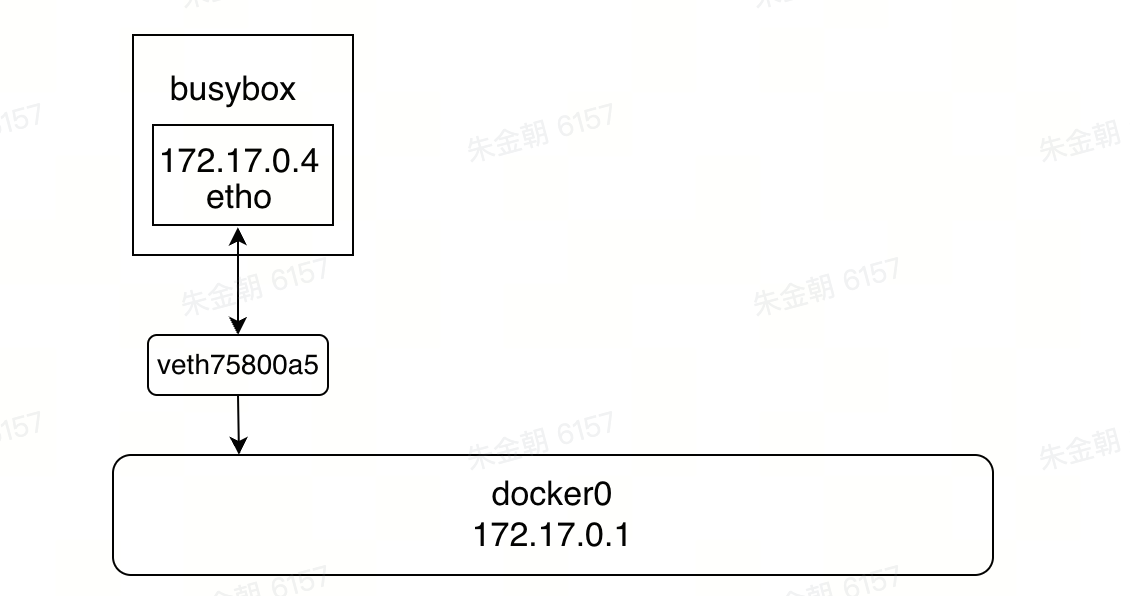
每启动一个容器, docker 会给对应的容器分配一个 ip, 我们只要安装了 docker, 就会有一个网卡 docker0
每创建一个容器则会额外产生一个虚拟网卡,这 个网卡会被桥接到 docker0 上
å
可以发现 veth75800a5 并不是容器的网卡名称
实际上 veth75800a5 和 eth0 是一对 veth pair,而 veth pair是一种成对出现的特殊网络设备,可以将其想象成一根由虚拟网线连接起来的一对网卡,网卡的一头 eth0 在容器中,另外一头 veth75800a5 挂载网桥 docker0 上,其效果就等价于 eth0 也挂在了网桥上
所以网络拓扑结构如下
- 所有的容器在不指定路由的情况下,都是 docker0 路由的, docker 会为我们的容器分配一个默认的可用 IP
- Docker 中的所有的网络接口都是虚拟的, 虚拟的转发效率高!
- 只要容器删除, 对应网桥对就没了
网络模式
- bridge: 桥接 docker (默认的网络模式)
- none: 不配置网络
- host: 和主机共享网络
- container: 容器网络联通 (不建议使用)
# 我们直接启动的命令, --net bridge, 这个就是 docker0
docker run -it -d --name "busybox-01" busybox
docker run -it -d --name "busybox-01" --network bridge busybox
# 创建一个自定义网络,网络名字为 "mynet"
# --driver bridge 表示创建新的bridge网络
# --subnet 192.168.0.0/16
# --gateway 192.168.0.1
docker network create --driver bridge --subnet 192.168.0.0/16 --gateway 192.168.0.1 mynet
# 将容器置于创建的子网中
docker run -itd --name "busybox-01" --network mynet busybox
docker run -itd --name "busybox-02" --network mynet busybox
除了 none, host, bridge 这三个自动创建的网络,用户也可以根据业务需要创建 user-defined 网络。
Docker 提供三种 user-defined 网络驱动:bridge, overlay 和 macvlan;overlay 和 macvlan 用于创建跨主机的网络
访问通信
启动两个容器
docker run -itd --name "busybox-01" busybox
docker run -itd --name "busybox-02" busybox
可以观测到docker0网桥上接入了两个设备
➜ ~ brctl show docker0
bridge name bridge id STP enabled interfaces
docker0 8000.0242afea7847 no veth1ca1b42
veth7738acb
此时两个容器是互通的
容器互通
- 两个 veth-pair 设备就相当于连接到 docker0 网桥就相当于连接到同一个交换机
- 容器内有默认的路由规则,发送数据包到网桥
容器网络怎么和外界通信
- busybox 发送 ping 包:172.17.0.2 -> www.bing.com
- docker0 收到包,发现是发送到外网的,交给 NAT 处理
- NAT 将源地址换成 enp0s3 (主机host的网卡) 的 IP:10.0.2.15 -> www.bing.com
- ping 包从 enp0s3 发送出去,到达 www.bing.com
通过 NAT,docker 实现了容器对外网的访问
外界怎么和容器内部网络通信
使用端口映射
docker 可将容器对外提供服务的端口映射到 host 的某个端口,外网通过该端口访问容器。容器启动时通过-p参数映射端口
docker run -itd --name=mynginx -p 8888:80 nginx 运行一个nginx容器,指定端口映射
每一个映射的端口,host 都会启动一个 docker-proxy 进程来处理访问容器的流量
可以看到现在已经有一个
docker-proxy 进程在 8888 端口进行监听
以 0.0.0.0:8888->80/tcp 为例分析整个过程如下:
- docker-proxy 监听 host 的 8888 端口。
- 当 curl 访问 [host]:8888 时,docker-proxy 转发给 nginx 容器的 80端口。
- nginx 容器响应请求并返回结果
跨主机网络
对于跨主机的容器通信则是交给了第三方实现,这就是 CNI 机制
CNI,它的全称是 Container Network Interface,即容器网络的 API 接口。kubernetes 网络的发展方向是希望通过插件的方式来集成不同的网络方案, CNI 就是这一努力的结果
CNI 只专注解决容器网络连接和容器销毁时的资源释放,提供一套框架,所以 CNI 可以支持大量不同的网络模式,并且容易实现
平时比较常用的 CNI 实现有 Flannel、Calico、Weave 等
CNI 插件通常有三种实现模式:
- Overlay:靠隧道打通,不依赖底层网络;
- 路由:靠路由打通,部分依赖底层网络;
- Underlay:靠底层网络打通,强依赖底层网络;
Overlay 网络简介
Overlay 网络 (overlay network) 属于应用层网络,它是面向应用层的,不考虑网络层,物理层的问题
这里借用知乎大佬@南风向北的一张图片
定义: Overlay 网络是指建立在另一个网络上的网络。该网络中的结点可以看作通过虚拟或逻辑链路而连接起来的。虽然在底层有很多条物理链路,但是这些虚拟或逻辑链路都与路径一一对应。
举例: 许多P2P网络就是 Overlay 网络,因为它运行在互联网的上层。 Overlay 网络允许对没有IP地址标识的目的主机路由信息,例如:Freenet 和DHT(分布式哈希表)可以路由信息到一个存储特定文件的结点,而这个结点的IP地址事先并不知道。
特点: Overlay 网络被认为是一条用来改善互联网路由的途径,让二层网络在三层网络中传递,既解决了二层的缺点,又解决了三层的不灵活
Flannel 网络
工作原理
Flannel 实质上就是一种 Overlay 网络,也就是将 TCP 数据包装在另一种网络包里面进行路由转发和通信,目前已经支持 UDP、VxLAN、AWS VPC 和 GCE 路由等数据转发方式。
Flannel 会在每一个宿主机上运行名为 flanneld 代理,其负责为宿主机预先分配一个子网,并为 Pod 分配IP地址。Flannel 使用 Kubernetes 或 etcd 来存储网络配置、分配的子网和主机公共IP等信息。数据包则通过 VXLAN、UDP 或 host-gw 这些类型的后端机制进行转发。
Flannel 规定宿主机下各个 Pod 属于同一个子网,不同宿主机下的 Pod 属于不同的子网
网络模型案例
以下面的网络模型举例
Overlay network 建立在容器网络的上层,为每个节点为配一个子网网段,一共可分配 2^16 个网段
每个网段分配给节点后,节点上的 pod 按照该网段地址来获得分配的IP
比如:机器上已经成功部署好了 flannel 插件
root@n37-074-180:~# crictl ps | grep -i flannel
6cae4471d933e 85c9944d9ff56 11 days ago Running kube-flannel 6 2f197363dcdb0 kube-flannel-ds-qjng
我们查看 flannel 的子网配置
root@n37-074-180:~# cat /run/flannel/subnet.env
FLANNEL_NETWORK=172.23.0.0/16 这是flannel的一个总网段
FLANNEL_SUBNET=172.23.19.129/26 这是flannel分配给当前node的子网段,pod的ip都会在这个网段
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true
宿主机和容器网络
pod中使用宿主机网络命名空间
如上图所示:单独的 pod 可以使用宿主节点的网络接口,而不是拥有自己独立的网络;这意味着这个 pod 没有自己的ip地址;如果这个pod中的某一个进程绑定了某个端口,那么该进程将被绑定到宿主节点的端口上
apiVersion: v1
kind: Pod
metadata:
name: pod-with-host-network
spec:
hostNetwork: true # 使用宿主节点的网络命名空间
containers:
- name: main
image: busybox
command: ["/bin/sleep", "999999"]
使用宿主节点的 PID 与 IPC 命名空间
k8s 如何在容器中看到宿主机上的进程,pod的配置里有两个字段
apiVersion: v1
kind: Pod
metadata:
name: test
spec:
containers:
- name: test
image: busybox
command: ["sleep", "3600"]
dnsPolicy: ClusterFirst
hostPID: true
hostIPC: true
-
hostPID被设置为true,表示该 Pod 将与宿主机共享 PID 命名空间。这意味着容器内的进程可以看到宿主机上的所有进程 -
hostIPC被设置为true,表示该 Pod 将与宿主机共享 IPC 命名空间。这意味着容器内的进程可以访问宿主机上的 IPC 资源,如共享内存段、信号量等
容器中如何操作主机
关于容器中如何操作主机,这里提供两种方式
方式一:利用 ssh 登录
在容器内通过挂载卷的方式添加公私钥到主机上,然后直接 ssh 从容器进入到宿主机内
参考 https://github.com/BoomChao/K8s/tree/main/pod-to-host
方式二:直接使用特权容器
使用特权容器加上 nsenter 命令,nsenter 命令很强大
只需要在容器中执行的脚本前加上这样一行代码,便进入到了容器中,然后便可以执行自己想要在宿主机上操作的一些逻辑
nsenter -t 1 -m -u -i -n
-t, --target <pid> target process to get namespaces from
-m, --mount[=<file>] enter mount namespace
-u, --uts[=<file>] enter UTS namespace (hostname etc)
-i, --ipc[=<file>] enter System V IPC namespace
-n, --net[=<file>] enter network namespace
关于容器的命名空间namespace 相关的知识后面可以单独出一期文章来写
总结
k8s的网络通信大致可分为如下
对于单机网络,其网络通信原理其实不难理解
- 对于 Pod 内部容器通信,由于 Pod 内部的容器处于同一个 Network Namespace 下(通过 Pause 容器实现),即共享同一网卡,因此可以直接通信。
- 对于同主机 Pod 间容器通信,Docker 会在每个主机上创建一个 Docker0 网桥,主机上面所有 Pod 内的容器全部接到网桥上,因此可以互通。
对于跨主机网络,其网络通信原理就是利用的CNI网络模型,诸如Calico,Flannel 等
对于想要从pod中访问宿主机,提供了两种方式,一种利用ssh密钥,一种利用特权容器➕nsenter 命令
参考文章
https://zhuanlan.zhihu.com/p/603642190
https://blog.laputa.io/kubernetes-flannel-networking-6a1cb1f8ec7c?gi=cc983635ddfa
https://draveness.me/whys-the-design-overlay-network/