在4 月 18 日 Llama3 发布前两天,面壁智能低调开源了大模型 Eurux-8x22B。据悉,该模型在代码和数学等体现大模型核心素质的复杂推理综合性能方面超越 Llama3-70B,刷新开源大模型 SOTA,堪称“理科状元”。
除了开源时间早于LlaMa3,Eurux-8x22B的激活参数仅有39B,推理速度更快,目前支持 64k上下文,相比之下 Llama3-70B 的上下文大小为8K。
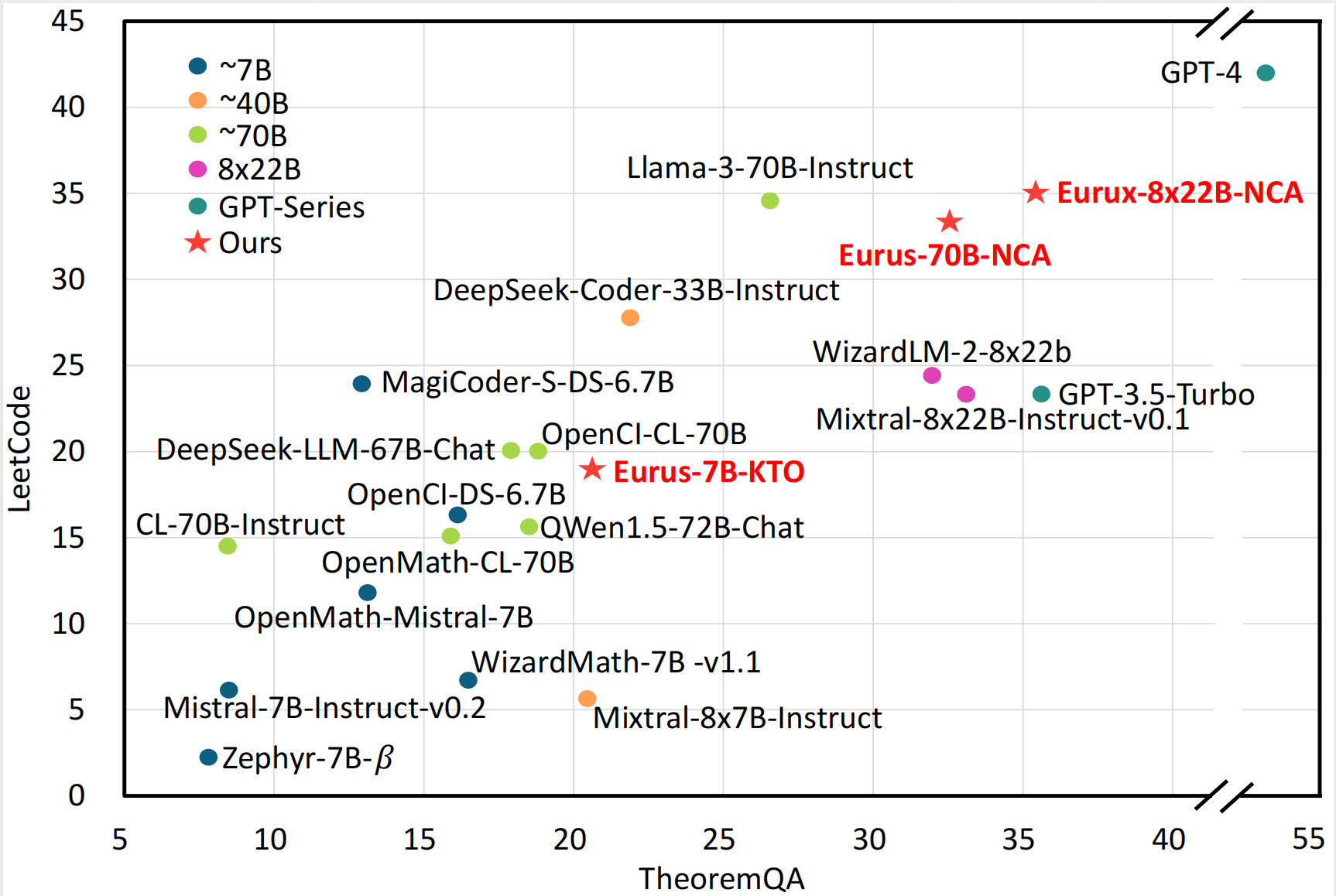
此外,Eurux-8x22B 由 Mistral-8x22B 对齐而来,综合性能不输 Llama3-70B。

Eurux-8x22B 模型和对齐数据,全家桶开源:
https://github.com/OpenBMB/Eurus"
https://huggingface.co/openbmb/Eurux-8x22b-nca"
LeetCode 周赛超越80%的人类选手
复杂推理能力是体现大模型性能差异的最核心能力之一,也是大模型真正落地应用所需的关键能力所在。根据测评,Eurux-8x22B在代码和数学等复杂推理的综合性能方面刷新开源大模型 SOTA。
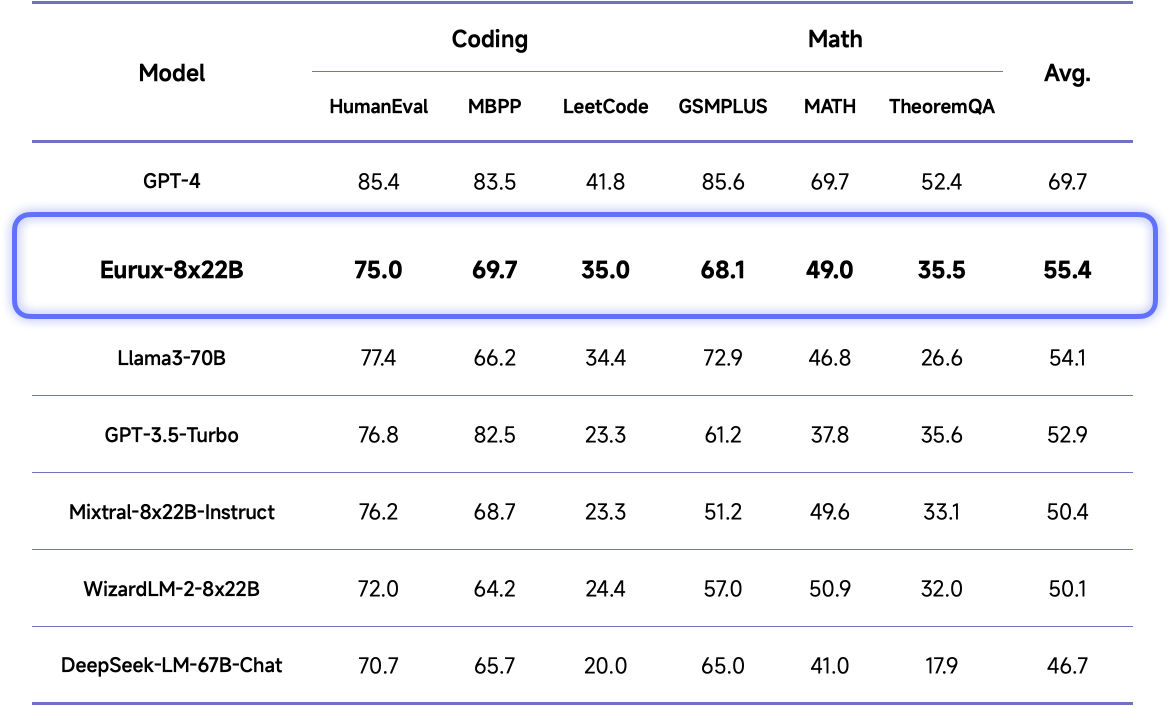
具体而言,Eurux-8x22B在 LeetCode (180道LeetCode编程真题)和TheoremQA(美国大学水准的STEM题目)这两个具有挑战性的基准测试中,超过现有开源模型。
那么开源大模型“理科状元”Eurux-8x22B在实际应用中表现如何呢?
代码能力方面,面壁智能让其参加了近期的一场 LeetCode 周赛,这是一个检验人类程序员编程能力的真实竞技场。
结果显示,Eurux-8x22B 的Python编程能力非常优秀,成功解决了四道算法题中的三道,其综合排名超越了80%的人类参赛选手,可以初步通过互联网大厂的程序员编程面试。下面是周赛中Eurux-8x22B对一道中等难度算法题的真实解答:


除了代码能力优秀,Eurux-8x22B 解答数学题也是轻而易举。
例如,给它一道高中排列组合题,Eurux-8x22B 首先给出了清晰的解题思路,然后一步步地拆解执行,再进行结果汇总,最后得到了正确答案。

再考察它一道代数题,Eurux-8x22B 直击要害,运用二项式定理,清晰简洁地给出了正确解答。

接着给它一道向量代数题,Eurux-8x22B 也能轻松拿下:

高考函数题可能是令很多人回忆起来就头疼的一类题,Eurux-8x22B 也能解答无误:

(注:Eurux-8x22B 没有针对中文语料进行额外的微调和对齐。)
大模型“上分神器”
面壁智能是国内极少数兼具大模型算法与 infra 能力的团队:匹配大模型作为系统工程的本质要求,打造了一条从数据原材料、到模型制作过程中训练与调校工艺环环相扣的全流程高效模型生产线,被戏称为“大模型界最强Buff厂”。
本次 Eurux-8x22B 更快、更长、理科更好的全方位惊艳成绩,即来自面壁 Ultra 对齐技术(Ultra Series)更新:新增了大规模、高质量对齐数据集UltraInteract。
UltraInteract是专门设计用于提升大模型推理能力的大规模、高质量的对齐数据集,包含了覆盖数学、代码和逻辑推理问题的12个开源数据集的86K条指令和220K偏好对,共有五十万(条)左右数据。而相比之下,LLaMA 3-70B模型则是使用了千万量级的对齐数据,这从侧面证明了 UltraInteract 数据集的优质性——数据质量胜过数据数量。
面壁智能团队是如何构建高质量的对齐数据?
严格质量控制和筛选。首先,面壁从多个开源数据集中抽样出难度较高、考察多样推理能力的86k复杂推理问题,并使用多个模型来采样答案。通过自动化格式检查和人工质量抽查结合的方式保证了答案格式的一致性和内容的正确性。
逐步推理。对于每条指令,模型都会按照思维链(CoT)格式进行逐步推理(如下图①),生成格式统一但模式多样的推理过程。
多轮交互。在模型给出推理过程之后,会自动与答案对比确定推理过程是否正确(如下图②),如果不正确,UltraInteract会使用另一个批评模型(如下图③)指出错误并给出改进建议,生成新的逐步推理(如下图④),再与策略模型进行多轮交互(如下图⑤⑥),直到答案正确或达到轮数上限为止。这一步有助于模型学会反思和改错能力,在实际表现中让其可以更好地和人进行多轮交互问答。

图注:UltraInteract两轮交互的过程
首创偏好树结构。为了深入探究偏好学习在复杂推理中的作用,UltraInteract还为每个问题都构建了一棵偏好树(如下图所示),其中问题作为根节点,每个回复作为一个子节点,每一轮生成两个节点(一对一错相配对)。所有正确推理对应的节点都可以用于SFT,而配对的节点则可以用于偏好学习。

图注:UltraInteract(第三列)是当前唯一一个树状结构的对齐数据集
除了UltraInteract数据集的大力加持,偏好对齐也对Eurux-8x22B的推理性能提升有所帮助。
面壁智能团队发现,在推理任务中,提升正确答案的奖励值对于偏好对齐的效果十分重要,因为正确答案的空间比错误答案更有限,因此更加重要,模型在训练过程中不能偏离正确答案。然而,当前流行的DPO算法会使正确答案和错误答案的奖励值共同降低,因此在实验中效果不佳。面壁智能采用了另外两种偏好对齐算法KTO和NCA,取得了更好的效果,能在SFT的基础上进一步提升模型性能。
此外,UltraInteract 数据集也在开源社区受到了广泛好评:

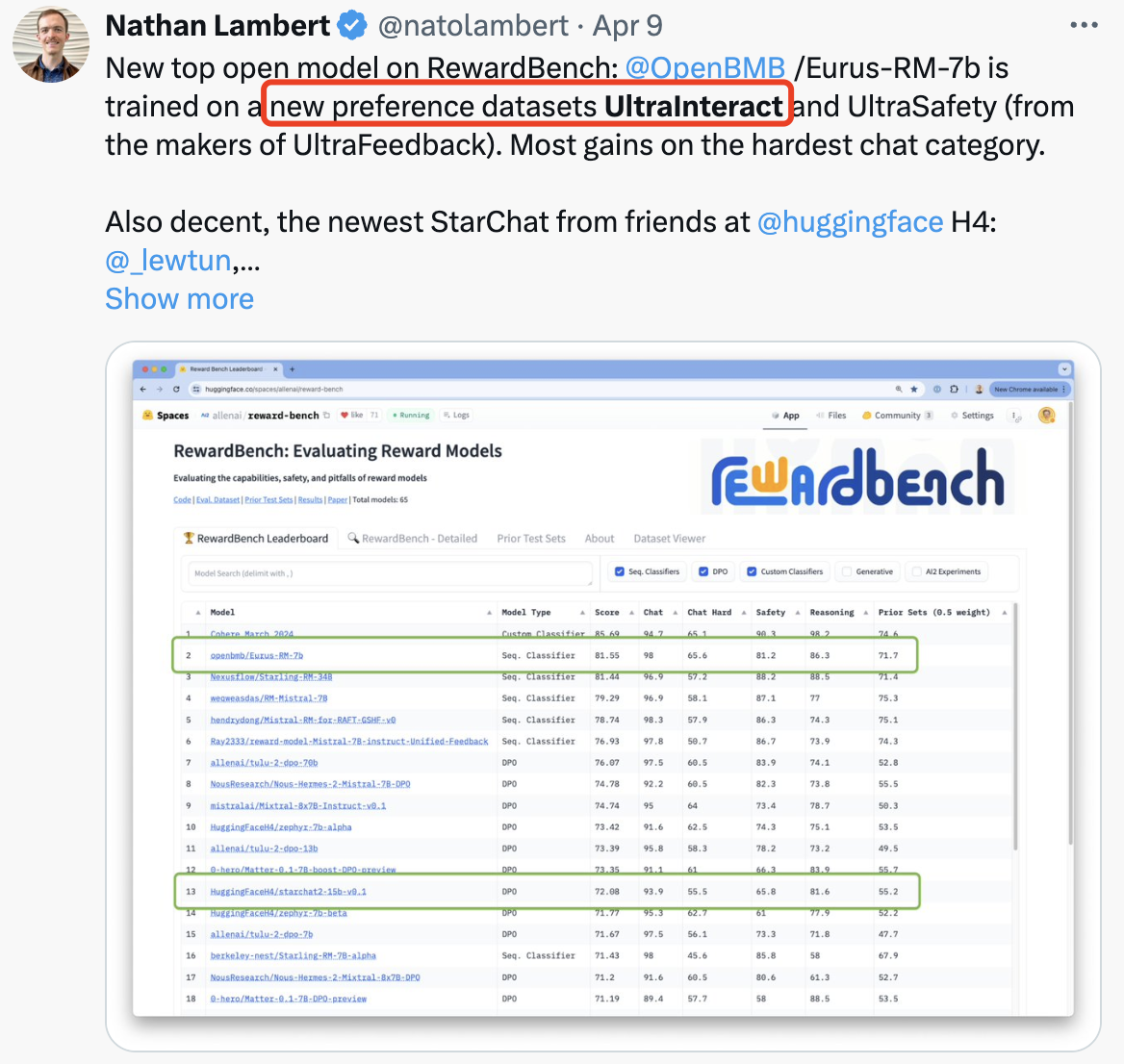
据悉,面壁 Ultra 对齐技术此前已经“强壮”了全球超 200 个大模型,尤其擅长提升大模型“以小博大”能力。例如,在面壁 Ultra 数据集的加持下,Zephyr-7B 以更小规模,在不少指标上超越了 LLaMA2-70B-Chat,同时帮助“小钢炮”MiniCPM-2B 取得与 Mistral-7B 一较高下的惊艳表现。
面壁智能表示,未来将持续开源高效大模型及其数据集,开源开放的精神最终将惠及所有人。