2024年ASPLOS (Architectural Support for Programming Languages and Operating Systems)大会在4月27日到5月1日于San Diego举行,作为横跨体系结构、编程语言和操作系统等多个领域的顶级会议,吸引了超过800位老师和同学线下参加。老规矩,我会在这份评述中,尽可能讲一些Presentation细节和参会感受,希望对感兴趣的朋友有帮助。
Workshop & Tutorial
大会前两天是各种Workshop和Tutorial,参加的人没有主会那么多。Workshop重点不是Poster,而是很多业内专家的Invited Talk,覆盖的话题很广,干货也很多。值得一提的是,今年ASPLOS各个Workshop的组织者还特意邀请了很多做LLM推理优化的人来给Talk,比如Amir Gholami、Tri Dao、Song Han,今年我也受邀在XTensor Workshop上对我们CMU Catalyst Group近期的工作进行了分享。
第二天的Young Architect Workshop算是意外之喜,包括Samira Khan的个人励志成长故事分享以及几位领域内的专家老师的Panel讨论,都对青年学子有很大的帮助。值得一提的是,今年来自国内的团队贡献了三场Tutorial,包括来自中科院计算所包云岗老师团队的“香山”RISC-V 处理器项目,来自SJTU的OpenHarmony项目,以及来自浙大的Janus 2.0量子计算框架,欢迎感兴趣的同学查阅相关资料。这些Talk和Tutorial其实干货不比主会少,感兴趣的同学建议都可以参加一下。另外这里也打个广告,今年接下来我们团队马上也会有两个Tutorial,一个是今年6月份将在智利举办的SIGMOD 2024,做开场报告,关于Data Management for LLM,另一个是今年7月份将在奥地利维也纳举办的ICML 2024,关于LLM Serving System Optimization,欢迎线下参会的同学围观!
比较令人意外的是,ASPLOS的Poster环节设计在了开幕前一天的傍晚,好处是确实是“红旗招展,人山人海”,坏处就是Presenter可能会比较辛苦,尤其这次我要同时handle两个论文的Poster,幸亏有小伙伴帮忙分摊压力... 总之,确实是在一开始就感觉到了大家的参会热情。
开幕
29号开始大会正式开幕,是比较常规的总结发言:1)今年比去年参会人数几乎翻了一倍;2)论文Submission数量的增长速度大概是1.5倍左右,不过这个增速大概率不会持续到2025;3)这其中一年三轮的投稿安排起到了很大的作用,当然这也给PC们带来了很大的压力,每人平均要交15份review… 不过所幸ASPLOS的committee覆盖范围广,囊括OS,Arch,PL三大方向,似乎勉强还能扛得住,在这里还要恭喜一下陈海波老师荣获“Most Die-Hard Reviewer” Award!评审们都太不容易了......

大会开了3天,总共44个Session,193篇论文,涉及MLSys的占比大概25%,每个Session大概4篇论文,每篇论文12分钟报告+3分钟Q&A,每次同时会有4个Session并行开始,再加上中间Break也不是很久,很难把所有有关MLSys的Presentation都刷一遍。所以这次我就不再逐个论文介绍了,只挑选一部分我听到的比较有趣的论文进行推荐。以下内容谨代表个人理解,仅供参考,发表论文不易,还是建议大家直接阅读论文呀!
Day 1
Session 1B: Optimizing ML Communication
我其实对这个Session抱有比较高的期待,主要是因为里面有一些涉及到Computation-Communication Overlapping的工作,如果大家有印象,去年ASPLOS就收录过来自Google团队的一篇相关论文,还被用到了PaLM Inference System当中。


作为今年Best Paper之一的Centauri其实讲的有点低于预期,可能是因为报告时间有限,个人感觉和之前工作相比的区分度不太够,拆分张量实现Tensor Model Parallelism中计算和通信的Overlap应该不算是什么新的idea,不知道为什么似乎也算到了Contribution里,Scheduling部分应该算是亮点,可惜也没能讲清楚,感兴趣的同学可以阅读论文。


来自AMD的T3讲的非常好,实现了细粒度的GEMM和通信的kernel fusion,如果能做到NV的卡上应该对Tensor Model Parallelism非常有用。


Two-Face则是针对Distributed SpMM类似BlockSparse的通信优化(总感觉不是第一次看到呢...)
Session 2D: ML Inference Systems
这个Session大概是这届ASPLOS观众最多的之一,一次性几乎坐满了两个厅,毕竟也是这届ASPLOS唯一一个主要针对LLM Inference System的Session了。


SpecInfer是首个Tree-based Speculative Inference System for LLMs,自从我们去年5月对外发布后,就得到了大量的关注,Follow-up的工作也有很多,不过大部分都是侧重Speculation算法改进的,很多人都忽略了投机式推理在系统层面的挑战,感兴趣的同学可以阅读我们的正式版论文,相信可以解读你的大部分疑惑。

ExeGPT听下来其实就是在做LLM中Prefilling & Decoding的Disaggregation,据韩国小哥说,他们做的其实很早,应该远早于SplitWise以及DistServe,但是由于ASPLOS投稿和开会时间隔比较久,所以现在才正式发布,某种程度上也说明了这个领域当前的“卷”的程度...


SpotServe是首个面向Spot Instance场景的LLM Serving System。最近有蛮多工作考虑使用廉价的弹性计算资源来降低AI Infra的成本,尤其是中小企业和个人用户,但主要都是面向大模型训练场景。对于LLM推理,使用Spot Instance的主要挑战就是处理Preemption所导致的Latency过长的问题。SpotServe借助于Re-parallelization和Live Context Migration (包括Params和KV-Cache)技术可以高效应对Preemption,可以实现在平均推理延迟几乎无影响的情况下,降低一半的云计算资源开销。
其他
第一天下午还有Session 3C: ML Cluster Scheduling以及Session 3D: ML Quantization and Memory Optimizations,但是它们时间上是冲突的,只能选其一,我听了两个Scheduling Session的报告。

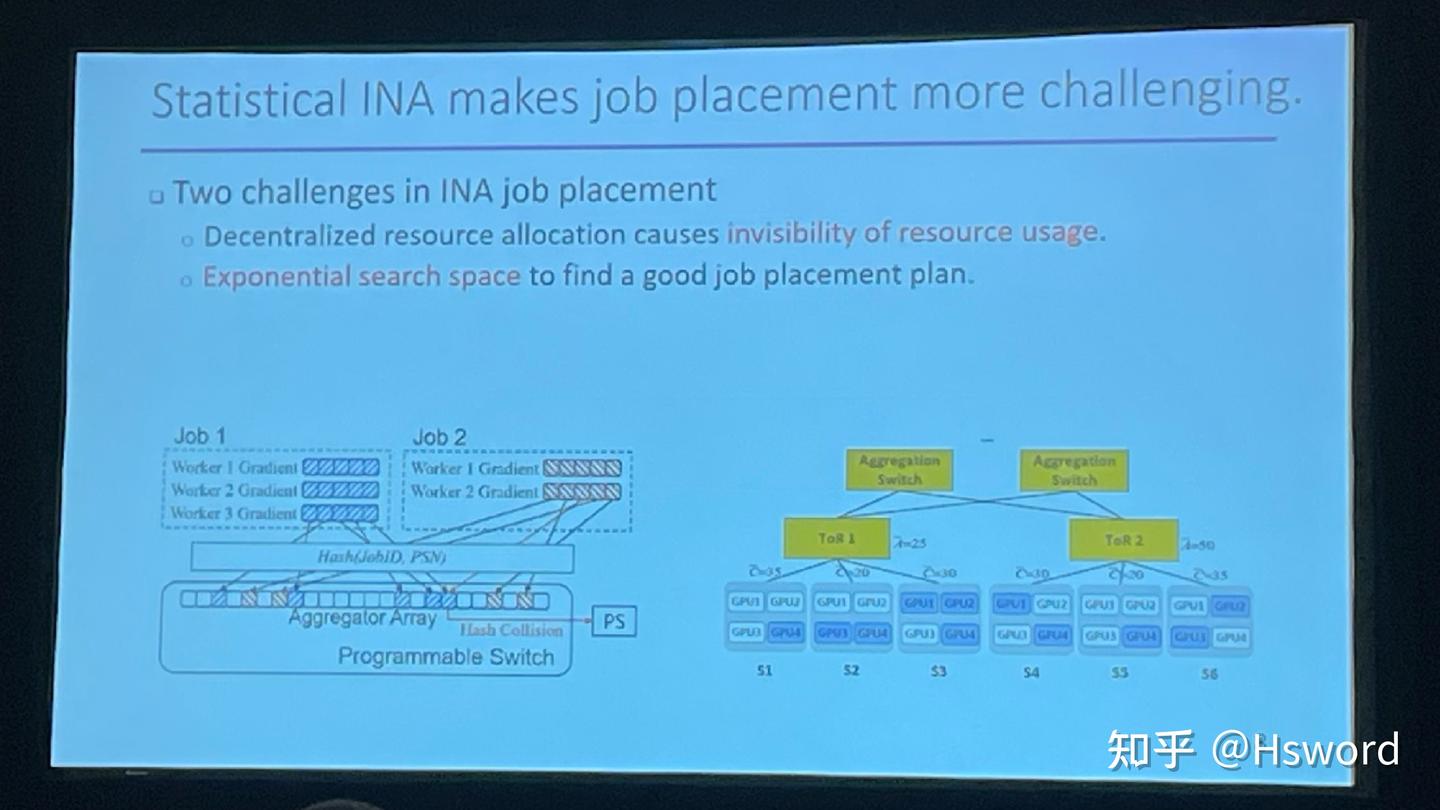
一个是来自北大的吴文斐老师团队的NetPack,还是借助Programmable Switch来实现分布式训练时的的梯度求和,这次主要是面向多任务的场景。

另一个是来自UCSD的丁雨霏老师团队的的RAP,听下来大概是想把DLRM里对特征预处理的一些常规CPU算子挪到GPU上,然后做了一些Fusion和Scheduling上的优化,去提高执行效率。

第一天的晚上主要是大会主办的一些其他活动,比如Debate和WACI。晚上8点还有一个Business Meeting,其实这个Meeting是蛮有意思的,但是时间安排的很晚,学生们基本都没参加,基本上只有非常senior的业内大佬professor留下来参加了。不仅仅是盘了一波大会的财务收支,更重要的是对整个ASPLOS community未来发展的关键问题展开了讨论,比如如何应对投稿量的扩张、如何保证某些领域的评审专业性、是否继续多轮审稿等等,很喜欢这种公开透明的决策和讨论风格!
Day 2
第二天和MLSys有关的Session主要是在下午,首先是6B: Processing-In-Memory (PIM) for ML和6C: Optimization of Tensor Programs,时间依然是冲突的。
Session 6C: Optimization of Tensor Programs
这个Session主要是ML Compiler相关的论文。

Felix这个听了后半部分,似乎核心思想是想把张量程序转化成Symbolic Schedule,从而把其中包含的Schedule变量变成可以微分求解的目标。不过这里还是有一些潜在的问题,比如图的划分、是否可微/全局最优、搜索空间的一致性等等,甚至于最终生成的kernel性能好坏也不单单取决于这些Variable。整体上结合实验来看,算是搜索空间探索方法上提供了一种不一样的尝试。


PyTorch 2的报告宛如大型报告现场+吐槽大会,简单说就是:你们这些人都是在搞“玩具”,好好看看我们是怎么做实用系统的。最重要的是,公布了一个Benchmark,希望ML Compiler的同行都能关注一下吧!

Korch是我们团队今天的第三篇ASPLOS论文,主要思想是告诉大家在做kernel fusion的时候不需要拘泥于现有的算子定义,而是可以进一步拆分(kernel fission),在细粒度层面上进行计算图优化,可以发现更多前所未见的优化机会。由于实验对比里干掉了PyTorch 2,还引来了前一个报告人的公开Q&A,真是太有意思了.
晚宴
第二天后续其实还有两个并行的MLSys Session,分别是7A: Architecture Support for ML和7D: Graph Neural Networks,不过不太感兴趣就没有去听。


当天晚上的Banquet在中途岛航母博物馆(USS Midway Museum)上举行,可以在船舱里玩飞行模拟器,在甲板上吃晚饭看颁奖典礼!

饭后颁奖,首先是Distinguished Artifact Award,总共选了10篇,恭喜各位获奖者!

然后是Best Paper Award,总共6篇,恭喜各位Best Paper得主!今年不仅把Distinguished Paper改回了Best Paper,还故意降低了获奖论文的比例(大概率是为了减少25年的投稿量),根据大会主席的解释,今年总共有18篇无负面意见的论文作为获奖候选,经过一轮额外的评审,最终选了6篇出来。

最后是Influential Paper,选了3篇,分别来自ASPLOS'12,13,以及14,其中还包括DianNao(寒武纪)!
Day 3
第三天仍然有MLSys的Session,分别是9C: ML Systems and Optimizations,10C: ML Sparsity and Dynamic Shapes,11C: ML Training Optimizations,不过毕竟是最后一天,听众就没有前两天那么多了。
结语
几天参加下来,整体上感觉,ASPLOS应该算是参会体验最好的顶会之一,大会组织方付出了很多努力和心血。既保证了传统方向的比重,又兼顾了新的话题和领域,达到了很好的平衡。
尤其是对于做MLSys的同学,大家可以发现,ASPLOS在MLSys这个Topic上,选择的内容覆盖面很广,而且选择的都是比较重要的话题,不光有LLM Serving,还有Scheduling/Overlapping、Compiler、Sparsity等等,你想看的这里几乎都有。
- 1B: Optimizing ML Communication
- 2D: ML Inference Systems
- 3C: ML Cluster Scheduling
- 3D: ML Quantization and Memory Optimizations
- 6B: Processing-In-Memory (PIM) for ML
- 6C: Optimization of Tensor Programs
- 7A: Architecture Support for ML
- 7D: Graph Neural Networks
- 9C: ML Systems and Optimizations
- 10C: ML Sparsity and Dynamic Shapes
- 11C: ML Training Optimizations
这种兼具专业性和话题度的安排,对于Committee的Expertise考验很大,能做到这种程度其实很不容易,相比于隔壁某LLMSDI做的确实好太多了... 期待鹿特丹的ASPLOS‘25(和EuroSys’25合办)!
最后,以上评述谨代表个人看法,抛砖引玉,个人精力有限,未能仔细斟酌考量,欢迎大家在评论区提出宝贵意见,如果刚好有作者路过,对于理解错误或描述不妥的地方,也请批评指正。希望这个分享能够帮助到大家!