我是没有想到这么快这个系列就会进入到第二卷,没办法,这也和AMD抛弃ZLUDA等杂念,将全部研发精力都投注在ROCm上分不开,这次要介绍的,就是AI当中一个最大的热点:大模型,这一年以来,大模型可谓是风头无两,各家纷纷给出自己的解决方案,别管是人工智能,还是人工智障,应用场景确实比过去多了太多太多,上次也详细介绍了在PC上搭建文生图的方法,感兴趣的可以回顾一下:

而大模型中另一个较大的亮点就是大语言模型(LLM),目前大语言模型的发展可谓是非常迅速的,在“运算/推理”阶段对硬件资源的占用也在逐步降低,甚至现在大部分新手机上都有各家的AI语音助手,不过那些基本都是靠线上运行的,手机本地主要是当一个运行媒介。
对于性能强劲的多的PC来说,本地部署个大模型,当做“AI服务器”就完全可行了!当然想要当好这个服务器,够强劲的CPU和GPU+足够大的内存和显存就是必要条件了,这方面是AMD的优势所在,尤其是CPU方面,那是碾压级的!而GPU部分其实也并不弱,本身理论算力就很高,而且A卡一直在显存方面都很大方,这个在跑模型方面尤为重要。同时,因为ROCm加速在5.7版本后对游戏显卡的下放,过去看似高不可攀的云端大语言模型,也有了部署在本地端的机会。其中Meta的Llama作为较早公布开源版本的大模型,被称为开启大预言模型“免费时代”的先驱,可以说是他们第一次把本地大预言模型带到了小成本运营商和个人玩家的身边。

前阵子,AMD官方发布了Meta Llama 3语言大模型的部署指南,里面详细介绍了在AMD平台上部署Meta Llama 3大语言模型的方法,不过那个指南是纯英文的,有些地方还和国内的网络环境不太适应,这里我重新整理了一下,带来更适合中国宝宝的最简单的AMD AI语言大模型部署教程!
运行平台
先来看这次搭建的硬件平台。相较于绘图的Stable Diffusion基本实现了全平台支持,大语言模型现在还是门槛较高的,同时对CPU、GPU、内存、显存都有较高的要求,因此,这次选择了7800X3D+7900XT作为搭建的基础。其实只要是基于RDNA3的显卡,理论上都可以跑,例如锐龙7000/8000移动CPU里的Radeon 780M,其实也算RX7000系列!当然速度就和独立显卡没法比了。
选择7800X3D的原因就是想要借助3D V-cache技术,猛吃超大三级缓存的红利,看看能得到什么样的效果,既能打游戏又能生产力,拉满!当然最完美的还是如今当之无愧的U皇7950X3D,不过从性价比的角度来说还是7800X3D合适。

7900XT用的是蓝宝石的7900XT 20G超白金,三风扇视觉效果上就寒气逼人。

超白金作为蓝宝石定位最高的系列,散热、用料都是猛下功夫,14层多倍铜PCB可见一斑,尺寸也来到了32x13.6x7.2厘米,占用三槽半的空间。



主板是任劳任怨的劳模TUF B650M WIFI,定位中端的芯片组就能轻松驾驭旗舰CPU,这放在隔壁,不知道供电要受到多大的压力才能保证没崩盘。

本着内存越大越好、留足余量的考虑。选用了这套金士顿的FURY RENEGADE的6400MT/s,2x48GB套条,96G的容量,应付大模型苛刻的配置要求也是易如反掌!

部署步骤
准备好了硬件环境(RX7000系列显卡+大内存),就可以尝试在电脑上部署Llama 3模型了,非常简单!
①下载安装LM Studio:
LM Studio是一个免费的桌面大语言模型运行和管理工具,专门提供了给AMD RX7000系列显卡使用的ROCm版本:

底下硕大的按钮就是LM Studio下载地址,单机即可直连下载,安装,体积不大只有300M。
0.2.22中加入了lms LM Studio的命令行界面,可以通过命令行实现更多操作。这里我们先略过,等等看有没有国内大神分享研究成果。
②部署Llama 3模型:
接下来进入LM STUDIO的实操环节,Changelog草草略过就进入了主页,上方可以看到目前已支持的大模型,中间的导航页面我们要玩的Llama 3傲然居首,简介不用看,通篇4个大字-遥遥领先!

然而一般情况下是没法在LM Studio中直接下载,因为默认是从HG这个模型库网站走的,直连不通,这时候可以请出我们特色的P2P下载工具——迅雷或者夸克!把这个地址贴到下载工具里,很快就可以从国内的镜像地址下载下来Llama 3模型了。
下载工具手忙脚乱期间,在左侧导航栏最下面的文件夹选项卡当中,先修改存储位置到任意文件夹,注意不要出现中文路径:

之后在文件夹位置中创建/meta/Llama两层文件夹,拷入下好的gguf文件就算安装成功,重启一下Lm Studio就可以在LM Studio中看到模型了!

下载完毕+重启LM Studio之后,就可以切换到第二个“Chat”选项卡,在顶部的模型选取中可以看到Llama 3,选择,稍等几秒钟载入模型后,理论上就可以直接开始玩了!


③几个设置:
不过需要注意的是,为确保性能的最大化,需要在右边Settings里面往下拉,看到那个被挡住一半的“Advanced Configuration”:
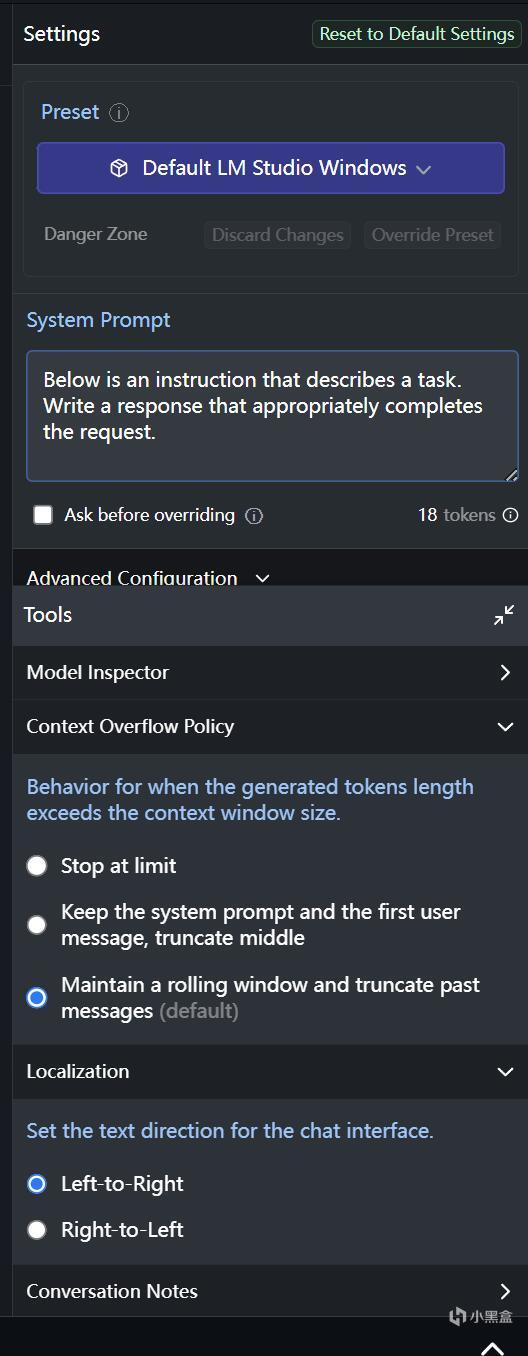
点开在里面找到GPU Offload,直接拉满!

拉满之后记得点击窗口中间的Reload按钮:

通过GPU OFFload的各档位设置,也可以了解到各档位的速度差别,这里分别以0/8/16/25/Max这5个预设档位下,采集推理到的数据,能看出MAX档简直可以说是神童。超过70tok/s,已经大大领先于各类云模型,更何况也不会受到网络/网速等一系列限制。

实战大模型
实际测试一下,默认是英文对话,对中文的支持比较少,个别语句能够理解:

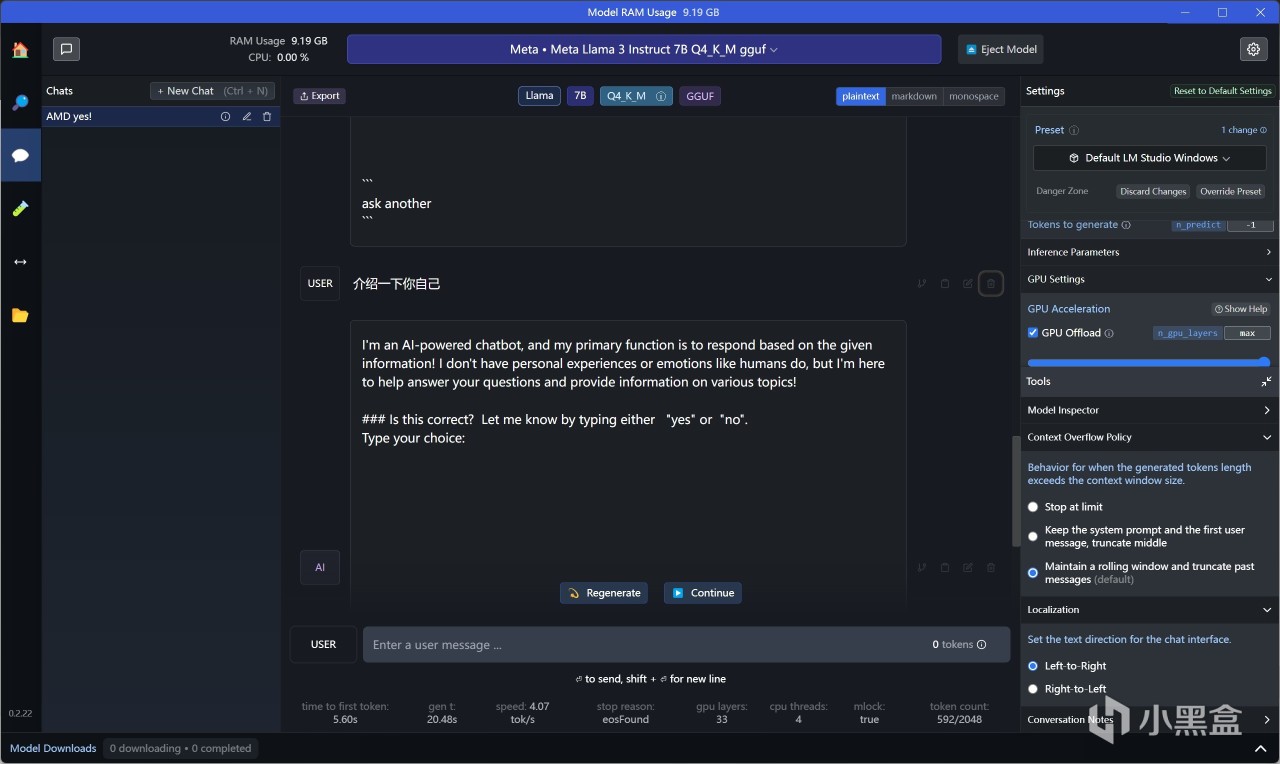
可以手动切换成输出中文:

看起来这个模型还不算太老,大概2022年左右的数据,但是里面的配件价格错误很多......图一乐啦!

总结
就这么简单三步,轻松在本地部署了大语言模型!这也充分说明了AI正以不可思议的速度在发展,目前大语言模型的主要功能还是集中在“总结”上,使得快速获得想要的内容成为可能,AMD ROCm技术的下放,让我们手里的游戏利器也有机会另辟蹊径,而且,7900XT这类目前5000元档位的显卡在LM Studio的帮助和Meta慷慨的开源之下,已经相当流畅,想更轻松的窥探本地大模型的魅力,不妨带着试一试。
再说一句:
最近,早教、视频内容输出等行业,也跟上了AI的浪潮,只不过在我看了纯纯是一股邪风,本质目的还是为了骗我们消费者手里这点盘缠,所以一定要加强辨别能力,不要被天花乱坠的“点点几个按钮,运行几个程序,就能一键生成XX说电影这类优质内容”的话术给骗了!