01
前言
今天给大家带来的是 Kafka Producer 的全方位解析(基于 Apache Kafka 3.7[2])。考虑到篇幅限制,本文分为上下两篇,上篇将介绍 Kafka Producer 的使用方法与实现原理,下篇将介绍 Kafka Producer 的实现细节与常见问题。
02
使用方法
在介绍 Kafka Producer 的具体实现前,首先看一下如何使用。用 Kafka Producer 向指定 topic 发送一条消息的示例代码如下:
// 配置并创建一个 Producer
Properties kafkaProps = new Properties();
kafkaProps.put("bootstrap.servers", "localhost:9092");
kafkaProps.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
kafkaProps.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(kafkaProps);
// 向指定 topic 发送一条消息
ProducerRecord<String, String> record = new ProducerRecord<>("my-topic", "my-key", "my-value");
producer.send(record, (metadata, exception) -> {
if (exception != null) {
// 发送失败
exception.printStackTrace();
} else {
// 发送成功
System.out.println("Record sent to partition " + metadata.partition() + " with offset " + metadata.offset());
}
});
// 关闭 Producer,释放资源
producer.close();
接下来详细介绍一下 Kafka Producer 的主要接口。
public class ProducerRecord<K, V> {
private final String topic;
private final Integer partition;
private final Headers headers;
private final K key;
private final V value;
private final Long timestamp;
}
public interface Callback {
void onCompletion(RecordMetadata metadata, Exception exception);
}
public interface Producer<K, V> {
// ...
Future<RecordMetadata> send(ProducerRecord<K, V> record);
Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback);
void flush();
void close();
// ...
}
注:在接口 Producer中,还有一些事务相关的接口,例如beginTransaction、commitTransaction等,其在我们另外一篇内容原理剖析| Kafka Exactly Once 语义实现原理:幂等性与事务消息中已经详细介绍过,此处不再赘述。
2.1 ProducerRecord
Producer 发送出的一条消息,包含以下属性
-
topic:必选。用于指定该 record 发送到的 topic
-
partition:可选。用于指定该 record 发送到的 partition 的序列号(从零开始编号,zero-indexed)。当未设置时,则使用用户指定的
Partitioner或内置的BuiltInPartitioner选择分区(详见下文) -
headers:可选。用户自定义的额外键值对信息
-
key:可选。消息的键值
-
value:可选。消息的内容
-
timestamp:可选。发送消息的时间戳。其生成逻辑为
- 如果 topic 的 message.timestamp.type 配置为 "CreateTime"
-
如果用户指定了 timestamp,则使用用户指定的值
-
若否,则使用创建这条消息的时间(约等于调用
send方法的时间)
-
- 如果 topic 的 message.timestamp.type 配置为 "LogAppendTime",则无论用户是否指定了 timestamp,都使用消息在 broker 上写入时的时间
- 如果 topic 的 message.timestamp.type 配置为 "CreateTime"
2.2 Callback
用于发送消息 ack 后的回调。可能发生的 Exception 有:
-
不可重试
-
InvalidTopicException:topic 的名称不合法,例如过长、为空、使用非法字符等 -
OffsetMetadataTooLarge:调用Producer#sendOffsetsToTransaction时,使用的 Metadata 字符串过长(由 offset.metadata.max.bytes 控制,默认 4 KiB) -
RecordBatchTooLargeException:发送的 batch 的大小-
超过了允许的最大大小(broker 配置 message.max.bytes 或 topic 配置 max.message.bytes,默认 1MiB + 12 B)
-
超过了 segment 的大小(broker 配置 log.segment.bytes 或 topic 配置 segment.bytes,默认 1 GiB)
注:该错误仅可能会发生在老版本的 Client 中
-
-
RecordTooLargeException:单条消息的大小超过了 producer 单个请求的最大大小(producer 配置 max.request.size,默认 1MiB) -
TopicAuthorizationException、ClusterAuthorizationException:鉴权失败 -
UnknownProducerIdException:事务请求中,PID 已过期或 PID 关联的 record 均已过期 -
InvalidProducerEpochException:事务请求中,epoch 非法 -
UnknownServerException:未知错误
-
-
可重试
-
CorruptRecordException:CRC 校验失败,通常由网络错误导致 -
InvalidMetadataException:Client 侧的 metadata 过期-
UnknownTopicOrPartitionException:topic 或 partition 不存在,可能由 metadata 过期导致 -
NotLeaderOrFollowerException:请求的 broker 不是 leader,可能正在选举 leader -
FencedLeaderEpochException:请求中的 leader epoch 过期,可能由 metadata 刷新慢导致
-
-
NotEnoughReplicasException、NotEnoughReplicasAfterAppendException:insync replica 数量不足(broker 配置 min.insync.replicas 或同名 topic 配置,默认 1)。注意,NotEnoughReplicasAfterAppendException会在 record 写入完成后发现,producer 的重试会导致数据重复 -
TimeoutException:处理超时,有两种可能 -
同步调用耗时过长,例如 producer buffer 满、拉取 metadata 超时等
-
异步调用超时,例如 producer 被限流导致没有发送、broker 超时未响应等
-
2.3 Producer#send
异步地发送一条消息,如果需要,在本条消息 ack 后触发 Callback。
保证向同一个 partition 发送的 send 请求的 Callback 会按调用顺序依次触发。
2.4 Producer#flush
标记 producer 缓存中的所有消息立即可用于发送,并阻塞当前线程,直至在此之前的所有消息都被 ack。
注:仅会阻塞当前线程,其他线程仍可正常发送,但对调用 flush 方法后发送的其他消息的完成时机没有保证。
2.5 Producer#close
关闭 producer,并阻塞等待至所有消息发送完成。
注:
-
在 Callback 中调用 close 会立刻关闭 producer
-
仍处于同步调用阶段(拉取 metadata、等待分配内存)的 send 方法将会立即终止,并抛出 KafkaException
03
核心组件
接下来介绍 Kafka Producer 的具体实现,它由以下几个核心组件组成
-
ProducerMetadata & Metadata
负责 Producer 侧所需元数据的缓存与刷新,其中包含 Kafka Cluster 的所有元数据,例如 broker 地址、topic 中的 partition 的分布状态、leader 与 follower 信息。 -
RecordAccumulator
负责维护 Producer 的缓冲区。它会将待发送的消息按照 partition 的维度、基于时间(linger.ms)和空间(batch.size)攒批为 RecordBatch,并等待发送。 -
Sender
维护一个守护线程 "kafka-producer-network-thread | {client.id}",负责驱动发送 Produce 请求和处理 Produce 响应,同时负责超时处理、错误处理与重试。 -
TransactionManager
负责实现幂等(idempotence)与事务(transaction)。包括分配序号(sequence number)、处理消息丢失与乱序、维护事务状态等。
04
发送流程
一条消息的发送流程如下图:
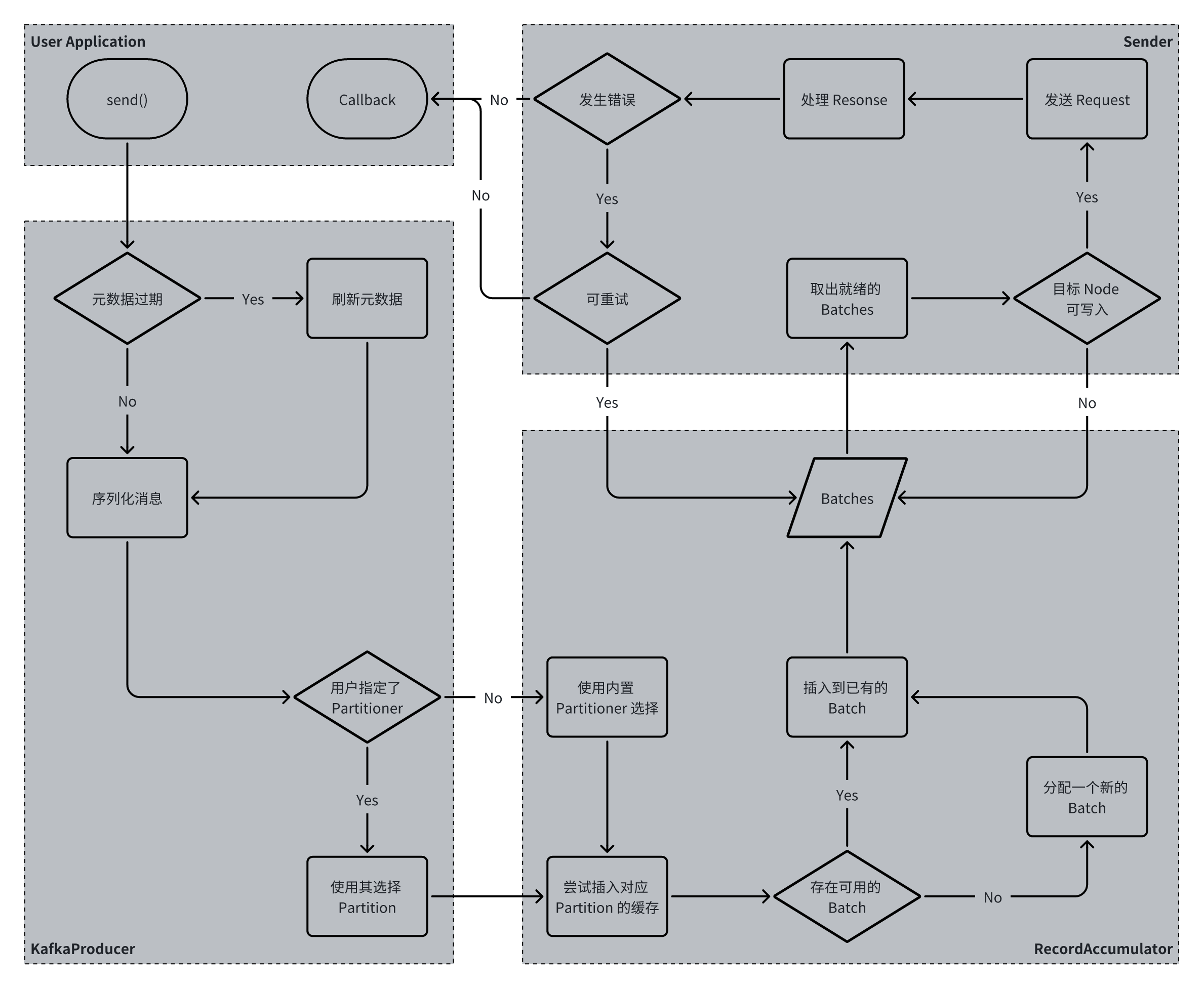
分为以下几步:
-
刷新元数据;
-
使用指定的 Serializer 序列化消息;
-
使用用户指定 Partitioner 或 BuiltInPartitioner 选择发送消息的目标 partition;
-
将消息插入到 RecordAccumulator 进行攒批;
-
Sender 异步地从 RecordAccumulator 中取出可发送的 batch(按照 node 分组),注册回调,并发送;
-
Sender 处理响应,并根据情况返回结果、返回异常或重试。
接下来介绍其中的各项细节
4.1 刷新元数据
ProducerMetadata负责 Producer 侧所需元数据的缓存与刷新,它会维护一个 topic 视图,其中包含 producer 所需的所有 topic。它会
-
在以下场景增加 topic
当发送消息时,指定的 topic 不在缓存的元数据中 -
在以下场景移除 topic
当发现某个 topic 的元数据已经持续 metadata.max.idle.ms 未被使用时 -
在以下场景刷新元数据
当发送消息时,指定的 partition 不在缓存的元数据中(这会发生在 topic 的 partition 数量增加时)
当发送消息时,指定的 partition 的 leader 未知
当发送消息后,收到了 InvalidMetadataException 响应
当持续 metadata.max.age.ms 未刷新元数据时
相关配置有
-
metadata.max.idle.mstopic
元数据的缓存超时时间。即,当超过指定时间未向某个 topic 发送消息时, 则会使该 topic 的元数据过期。默认为 5 min。 -
metadata.max.age.ms
元数据强制刷新时间间隔。即,持续超过指定时间未刷新元数据时,主动进行更新。默认为 5 min。
4.2 分区选择
在 KIP-794[3] 中,为了解决之前版本中的 Sticky Partitioner 导致的“向更慢的 broker 发送了更多的消息”的问题,提出了一个新的 Uniform Sticky Partitioner(并作为默认的内置 Partitioner)。在没有 key 的限制时,它会向更快的 broker 发送更多的消息。在进行分区选择时,分为以下两种情况:
-
如果用户指定了Partitioner,则使用该 Partitioner 选择 partition
-
如果没有,则使用默认内置的
BuiltInPartitioner-
如果设置了 record key,则基于 key 的哈希值唯一选择一个 partition。具体地说
-
拥有相同 key 的 record 会被始终分配到同一个 partition
-
但当 topic 的 partition 数量变化时,不保证变化前后相同的 key 仍会分配到同一个 partition
-
-
如果没有设置 key,或者 partitioner.ignore.keys 设置为 "true",则使用默认策略——向更快的 broker 发送更多的消息
-
相关配置有
- partitioner.class
分区选择器的类名,可以由用户根据需求自行实现。提供了一些默认实现
-
DefaultPartitioner与UniformStickyPartitioner:会 "sticky" 地向各 partition 分配消息,即,在某个 partition 攒满一个 batch 后,切换至下一个 partition。但其实现上存在问题,会导致向更慢的 broker 发送更多消息,现已标记为废弃。 -
RoundRobinPartitioner:将会忽略 record key,循环(round robin)地向每个 partition 分配消息。注意,它存在一个已知问题:在创建新的 batch 时,会导致不平均的分配。
目前建议使用内置 partitioner 或者自行实现 partitioner。
- partitioner.adaptive.partitioning.enable
是否根据 broker 的速度决定发送消息的数量,若不开启,则会随机地选择 partition。仅在未配置 partitioner.class 时生效。默认为 "true"。
- partitioner.availability.timeout.ms
仅在 partitioner.adaptive.partitioning.enable 设置为 "true" 时生效。当“为指定 broker 攒出一批消息的时间点”和“向指定 broker 发送消息的时间点”相差超过此配置时,则不再向指定 broker 分配消息;设置为 0 意味着不开启此逻辑。仅在未配置 partitioner.class 时生效。默认为 0。
- partitioner.ignore.keys
选择 partition 时是否忽略消息的 key,若为 "false",则根据 key 的哈希值选择 partition,否则忽略 key 值。仅在未配置 partitioner.class 时生效。默认为 "false"。
4.3 消息攒批
在 RecordAccumulator 中,按照 partition 维度维护了所有待发送的 batch。有以下几个重要方法:
public RecordAppendResult append(String topic,
int partition,
long timestamp,
byte[] key,
byte[] value,
Header[] headers,
AppendCallbacks callbacks,
long maxTimeToBlock,
boolean abortOnNewBatch,
long nowMs,
Cluster cluster) throws InterruptedException;
public ReadyCheckResult ready(Metadata metadata, long nowMs);
public Map<Integer, List<ProducerBatch>> drain(Metadata metadata, Set<Node> nodes, int maxSize, long now);
-
append:将消息插入到缓冲区,注册一个 future 并返回,该 future 会在消息发送完成(成功或失败)时完成。
-
ready:筛选出所有拥有可发送消息的 node 列表。有以下几种情况:
已经攒批出 batch.size 大小的消息
已经持续攒批超过了 linger.ms 时间
分配给 producer 的内存已耗尽,即,缓冲区的消息大小总和超过了 buffer.memory
需要重试的 batch 已经等待至少 retry.backoff.ms 时间
用户调用了 Producer#flush 以强制发送消息
正在关闭 producer -
drain:对于每个 node,遍历其上的每个 partition,取出每个 partition 上最早的 batch(如果有),直至攒够 max.request.size 大小的消息,或遍历完所有 partition
相关配置有
-
linger.ms
每个 batch 会等待的最大时间。默认为 0。
值得说明的是,当设置为 0 时,不意味着不再进行攒批,而是不在发送前进行任何等待。如果希望禁止攒批,应将 batch.size 设置为 0 或 1。
调高该配置会
增大吞吐(发送每条消息的 overhead 会变得更低,压缩的效果会更好)略微增加延迟
-
batch.size
每个 batch 的最大大小。默认为 16 KiB。
当设置为 0(等价于设置为 1)时,则会禁用攒批,即,每个 batch 中仅有一条消息。
当单独某条消息的大小超过 batch.size 时,它会作为单独一个 batch 发送。
调高该配置会-
增大吞吐
-
浪费更多内存(在每次创建一个新的 batch 时,都会分配出一块 batch.size 大小的内存)
-
-
max.in.flight.requests.per.connection
在未收到响应前,producer 向每个 broker 发送的 batch 的最大数量。默认为 5 -
max.request.size
每次请求中消息总大小的最大值,同时也是每条消息的最大大小。默认为 1 MiB注意,broker 配置 message.max.bytes 和 topic 配置 max.message.bytes 也对每条消息的最大大小做出了限制
4.4 超时处理
Kafka Producer 定义了一系列超时相关的配置,用于控制发送消息的各个阶段允许耗时的最大值。梳理如下图:
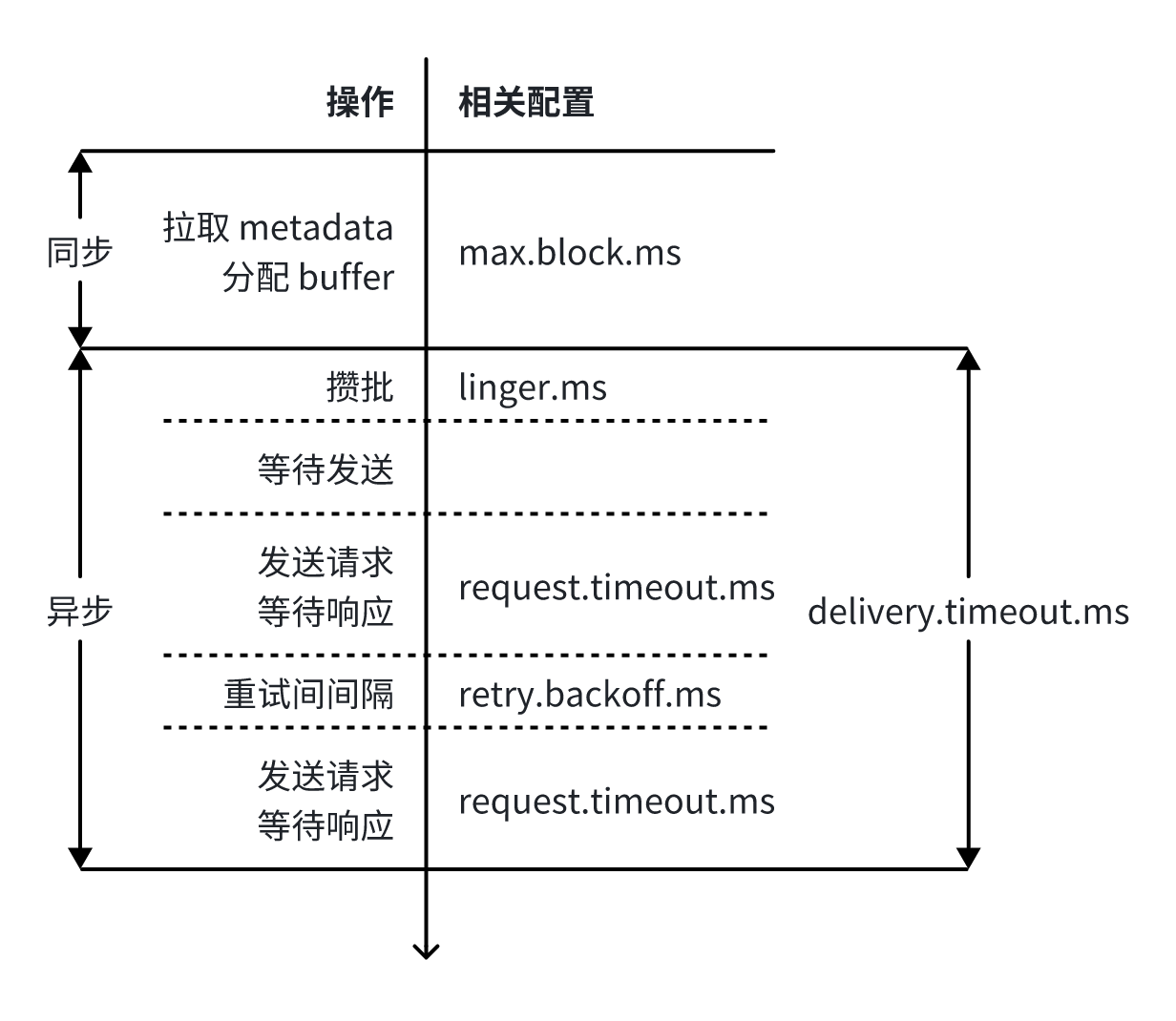
具体地说,相关配置有
-
buffer.memoryproducer buffer 的最大大小。默认为 32 MiB。当 buffer 耗尽时,会阻塞地等待最多 max.block.ms 的时间,随后报错。
-
max.block.ms调用 send 方法时,会阻塞当前线程的最长时间。默认 60s。其包含1.拉取 metadata 的时间2.producer buffer 满时等待的时间不包含1.序列化消息的时间2.调用 Partitioner 选择 partition 的时间
-
request.timeout.ms从发送请求到收到响应的最长时间。默认 30s。
-
delivery.timeout.ms异步发送消息的最长总耗时,即,从 send 方法返回后,到触发 Callback 的总耗时。默认 120s。其包含1.producer 内部攒批的时间2.向 broker 发送请求并等待返回的时间3.每次重试的时间它的值应不小于 linger.ms + request.timeout.ms。
-
retries重试的最大次数。默认为 Integer.MAX_VALUE。
-
retry.backoff.ms 与 retry.backoff.max.ms二者组合控制发送失败后重试的指数退避策略——随着重试次数的增加,从 retry.backoff.ms 开始按照 2 的指数次幂增加重试等待时间,并增加一个 20% 的扰动,且最大不超过 retry.backoff.max.ms。默认为 100ms / 1000ms。
05
小结
我们的项目 AutoMQ[1] 致力于构建下一代云原生 Kafka 系统,解决过去 Kafka 的成本、弹性问题。作为 Kafka 生态的忠实拥护者和参与者,我们将持续为 Kafka 技术爱好者带来优质的 Kafka 技术内容分享。在上篇中,我们介绍了 Kafka Producer 的使用方法以及基础的实现原理;在下篇中,我们将介绍 Kafka Producer 的更多实现细节与使用中的常见问题。欢迎关注我们以了解更多。
参考资料
[1] AutoMQ: https://github.com/AutoMQ/automq
[2] Kafka 3.7: https://github.com/apache/kafka/releases/tag/3.7.0
[3] KIP-794: https://cwiki.apache.org/confluence/display/KAFKA/KIP-794%3A+Strictly+Uniform+Sticky+Partitioner
END
关于我们
我们是来自 Apache RocketMQ 和 Linux LVS 项目的核心团队,曾经见证并应对过消息队列基础设施在大型互联网公司和云计算公司的挑战。现在我们基于对象存储优先、存算分离、多云原生等技术理念,重新设计并实现了 Apache Kafka 和 Apache RocketMQ,带来高达 10 倍的成本优势和百倍的弹性效率提升。
🌟 GitHub 地址:https://github.com/AutoMQ/automq
💻 官网:https://www.automq.com
👀 B站:https://space.bilibili.com/3546572478482870?spm_id_from=333.337.0.0
🔍 微信公众号:AutoMQ