欢迎阅读 OSCHINA 编辑部出品的开源日报,每天更新一期。
# 2024.6.5
今日要闻
悟空刘歧 (Steven Liu) 成为 FFmpeg 社区委员会成员
FFmpeg 项目今日在邮件列表正式官宣新的 Community Committee 成员:Steven Liu。据悉这是首位成为 FFmpeg 社区委员会成员的亚洲人。
FFmpeg 社区委员会 (Community Committee) 目前共 5 名成员,主要职责是规范开发者在邮件列表与 IRC 频道上的行为,维持工作环境,仲裁调解开发者之间的纠纷,是社区建设相关最终决策者。
via https://lists.ffmpeg.org/pipermail/ffmpeg-devel/2024-June/328921.html

Steven Liu 是中国开发者刘歧 —— 社区人称大师兄悟空。他是 FFmpeg 社区最活跃的贡献者之一,也是 FFmpeg 官方顾问,曾出版技术书籍《FFmpeg 从入门到精通》《深入理解 FFmpeg》。
智谱开源GLM9B系列模型
智谱开源了 GLM-4-9B 系列模型,包含基座模型、不同上下文长度的Chat模型和视觉模型。
从能力测评来看,GLM-4-9B 性能提升40%,表现超越 Llama-3-8B 。除了能进行多轮对话,GLM-4-9B-Chat 还支持网页浏览、代码执行、自定义工具调用,上下文长度最大支持 128K 。同时,模型增加了多语言支持,包括日语,韩语,德语在内的 26 种语言。
此外,智谱还推出了支持 1M 上下文长度(约 200 万中文字符)的 GLM-4-9B-Chat-1M 模型和基于 GLM-4-9B 的多模态模型 GLM-4V-9B。
GLM-4V-9B 具备 1120 * 1120 高分辨率下的中英双语多轮对话能力,在多模态评测中能力比肩GPT 4V。
昆仑万维开源2千亿稀疏大模型天工MoE,全球首创能用4090推理
2024年6月3日,昆仑万维宣布开源 2 千亿稀疏大模型 Skywork-MoE , 性能强劲, 同时推理成本更低。
Skywork-MoE 基于之前昆仑万维开源的 Skywork-13B 模型中间 checkpoint 扩展而来, 是首个完整将 MoE Upcycling 技术应用并落地的开源千亿 MoE大模型,也是首个支持用单台 4090 服务器推理的开源千亿 MoE大模型。
今日观察
社交观察
开源AI让日常调用不同大模型更简单
AI大模型的未来发展趋势,需要怎么在单一大模型和多个专门化小模型之间做平衡和选择?
针对如此现状,两位斯坦福校友创办的NEXA AI,提出了一种新的方法:采用functional token整合了多个开源模型,每个模型都针对特定任务进行了优化。他们开发了一个名叫Octopus v4的模型,利用functional token智能地将用户查询引导至最合适的垂直模型,并重新格式化查询以实现最佳性能。
- 微博 量子位
今年最期待的就是三个模型,2个开源,一个闭源
qwen2是不是快要开源了?阿里在这块还是给力的,qwen1.5覆盖了1.8B,4B,7B,14B,32B,72B,110B。可以说是尺寸最全的模型了。
我之前说过,今年最期待的就是三个模型,2个开源,一个闭源。开源的是llama3,qwen2,闭源的是chatgpt5.
现在半年未到,llama3的小尺寸版本已经开源,挂起来一阵旋风。qwen1.5的动静也不小,非常的给力,现在就看qwen2了。
chatgpt5未必今年发布,不知道是不是遇到了困难。但是chatgpt4o效果还是非常好的。
- 微博 挨踢牛魔王
OpenAI分享他们在RAG技术的最佳实践
客户需求:他们有大量文档(比如10万份),希望模型只基于这些文档进行知识检索。解决方案:
1. 直接将PDF和docx文件嵌入,准确率是45%。
2. 经过20次调优迭代,解决细节小Bug - 准确率到65%
3. 基于规则进行优化,譬如先判断问题属于什么领域(退一步思考),然后再回答,效果提升到85%
4. 发现数据里有一些是结构化数据(如表格),为此定制提取解决,准确率提升到98%。
- 微博 斌叔OKmath
科普一下 Perplexity 这个名字怎么记
per 就是 perfect、perform 的那个 per-
plex 就是 duplex、complex 的那个 -plex
-ity 就是 community、university 那个 -ity
- 微博 宝玉xp
token在NLP语境下指“语言的基本单元”
上条微博提到,token在NLP语境下指“语言的基本单元”,“词元”似乎已经是比较常见的翻译。
在区块链语境下,token指的是可流通的数字权益证明,翻译相对没那么统一,通证、令牌、代币、虎符都见过。
刚刚看到一篇论文(图一),作者陈鹏又提出了一个新的token译法“兑艮”,查了一下,居然还是音义双全的一个翻译(图二),有点妙啊!虽然大概率推广不开,不过用易经的卦象来翻译数字时代的概念,这背后的理念还挺有意思的!
- 微博 同声翻译樱桃羊
应该拉何恺明跟马毅来一场PK座谈
留言1:马老师微博关注很久了,很敢想也很敢讲,感觉整个Berkeley的风气就是这样,应该拉何恺明跟马毅来一场PK座谈,一个说可以暂时不追求解释性,一个则是白盒到底,肯定有碰撞火花⚡️!
留言2:
看得出来作者做足了功课,而马院长的回答也体现了他清晰的思路和深刻的理解,读完非常有收获。现在的主流是堆算力暴力探索,存在两大命门:巨大的能耗,黑盒的不可解释性。而白盒 AI 恰好可以完美解决这两个问题。马院长的一番话也简单明了地解释了目前的 AI 本质上只是数据压缩,远没有到能毁灭世界的地步。至于更高层次的能够自我纠错自主学习的 AI,个人感觉其中的机制还是太复杂了,涉及到记忆,推理,可能还要涉及到自我意识,个人感觉还需要至少数十年的时间去攻克。
- 微博 出版人周筠
为什么斯坦福大学生要抄袭中国大模型?
开源贯穿互联网发展的始终,也延绵到了人工智能时代,幸好,雷蒙的“眼睛多”定律,不止有助于发现bug,也有助于发现抄袭。
这次事件,在某种程度上也让我们再次感受到了来自互联网开放精神的魅力,从某种意义上来说,这个斯坦福团队犯得最大的错,在于他们利用了互联网的开放性,却忽略了开放性的另一个重要特点:全民监督。
事后,就有网友疑惑评论:“难道他们不怕被发现么?”
也许,再开放的世界,也敌不过一个自我封闭的大脑和视野。
- 微信 吴晓波频道
如何应对“模型抄袭”?对“斯坦福抄袭中国大模型”事件的三重思考
一、责任方面,开源模型“窃书”算不算“偷”?
二、伦理方面,不负责任的行为在模型开源生态中如何控制
三、发展方面,简书这类文化起源性的传统知识,应该如何更有效地利用?
- 雪球 阿里研究院
媒体观察
对话香港大学马毅:“如果相信只靠 Scaling Laws 就能实现 AGI,你该改行了”
当大部分人都相信一件事或趋势时,不同意的人可以选择沉默,也可以大声说出来。前者是少数派中的多数派,后者少数派中的少数派。
马毅就是一个少数派中的少数派。
自 2000 年从伯克利大学博士毕业以来,马毅先后任职于伊利诺伊大学香槟分校(UIUC)、微软亚研院、上海科技大学、伯克利大学和香港大学,现担任香港大学计算机系主任和数据科学研究院院长。
他最早将 “压缩感知” 技术应用于计算机视觉领域,在人脸识别、物体分类等任务上产生了巨大影响。
知名 AI 学者李飞飞是马毅在 UIUC 时参与招聘的第一个华人助理教授,ResNet 一作何恺明是马毅在微软亚研院负责视觉组时招的第一个新员工。
马毅公开表达时直言不讳。AI 业界惊叹于 GPT 等大模型的威力,担心 AI 可能毁灭人类,如图灵奖得主杰弗里·辛顿(Geoffrey Hinton) 和 OpenAI 发起者之一伊隆·马斯克(Elon Musk)就多次将 AI 类比为原子弹,呼吁监管。
“说现在的 AI 危险的人,要么是无知,要么是别有目的。” 马毅在 twitter 上回应 AI 威胁论。
- 晚点LatePost
斯坦福两学生抄袭清华系大模型,是如何被发现的?对话打假者
南都记者尝试联系率先发现清华系模型被套壳的网友,他表示只是做了一名开源社区工作者应该做的事。此次Llama3-V的抄袭行为,“相当于把可口可乐换成可日可乐就说是自己的项目”。
针对此事,面壁智能CEO李大海也作出回应,称技术创新不易,呼吁共建开放、合作、有信任的社区环境。
- 南方都市报
硅谷手记|AI抄袭背后的硅谷“不光彩文化”
“‘作假,直至成功’,这是硅谷不光彩的文化。”美国斯坦福大学人工智能实验室主任克里斯托弗·曼宁3日就该校某些研究人员抄袭中国清华大学等机构成果的行为这样评论说。他在社交媒体上还指出,该研究团队应该深刻认识自己的错误。
- 新华社
AI明星创业公司大地震:创始人淡出,合伙人及多名高管离职
从去年开始,多名大企业高管离职涌入AI创业大潮,如今这股潮水正在退去。
近日,清华系大模型创业公司衔远科技发生人事变动。新浪科技获悉,衔远科技创始人、前京东AI掌门人周伯文不再主持公司事务,他的下一站可能是上海人工智能实验室担任主任职务。
- 新浪科技
斯坦福团队抄袭事件背后:中美AI研发竞逐“贴身战”
北京智源人工智能研究院副院长兼总工程师林咏华持有更严谨的态度,她对第一财经记者表示,中国在多模态领域弯道超车是有一定可能性的,但更关键的还是看多模态模型成功要素——依然是算力、算法和数据。目前算法层面,中美团队之间差异没有那么大,算力也不会造成最大问题,行业仍有办法去解决算力问题。但是,林咏华认为目前数据的问题是阻力最大的,即使智源一直在做AI训练数据扩展,但要获取海量高质量数据,依然难度很大。
- 第一财经
“百模大战”打了一年: 应用企业仍在摸着石头过河
但时至今日,能转起大模型商业化齿轮的,似乎仍以互联网大厂既有业务为主。典型如谷歌,其搜索引擎并未如业界最初估计的一般被大模型颠覆,既有的广告业务则率先受益于大模型,第一季度广告收入增长约70亿美元。大厂之外,原生的大模型爆款应用依旧稀缺。
- 一财网
锐评| 在这条新赛道上,中国完全不必妄自菲薄
“人工智能是引领这一轮科技革命和产业变革的战略性技术,具有溢出带动性很强的‘头雁’效应。”我们既要“紧张”起来,以时不我待的紧迫感去抢抓机遇,保持第一梯队的位置;也要“放松”下来,以更加自信的姿态,有条不紊、踏踏实实地走好自己的路。时间,永远不会辜负智慧与汗水。
- 北京日报
从GPT-4o看人工智能竞争的走向和挑战
上海Soul人工智能研究院院长陶明日前在对新华社记者谈到GPT-4o发布时说:“不再大谈深奥的技术、不再强调未来投入多少巨资,而是重点展示了家教辅导等应用场景,从中可以看出,此轮AI发展中,关注场景和交互体验将会是必然的趋势。”
零一万物首席执行官李开复日前接受新华社记者采访时表示,多家中国科技公司在开源和闭源领域都发布了大量高质量的模型,性能逐步追齐GPT-4,并在中文能力上达到世界领先。
“大模型的竞赛可以分为几个阶段,第一个阶段是‘卷指标’,在参数和指标的提升中重点关注性能问题,但这也造成了目前的一个行业通病问题——大模型性能和应用严重分离,也就是大家所讨论的‘拿着锤子找钉子’的问题。因此,发展至第二个阶段‘卷场景和体验’,成为一种必然。”陶明说。
- 新华社
卷技术是美国大模型天命,卷价格是中国大模型宿命?
要而言之,大模型技术能力提升才是硬道理,价格战换来的不该是在落后系统上开发应用,而应是「价格力-技术力」相互带动的正循环基础上的系统持续升级。
价格为锚、应用为先,也许能帮中国大模型完成局部赶超意义上的「弯道超车」。但局部之外的部分,只能靠技术创新去补齐。在这点上,没有捷径。
这不是说中国大模型厂商不该卷价格,而是说卷价格的进阶方向还得是卷技术——如果有些人非要怪中国大模型「就知道猛卷价格」,那一切责任在于拜登,谁让他摁下英伟达芯片断供按钮的?
- 数字社会发展与研究
今日推荐
开源项目
dragonflydb/dragonfly
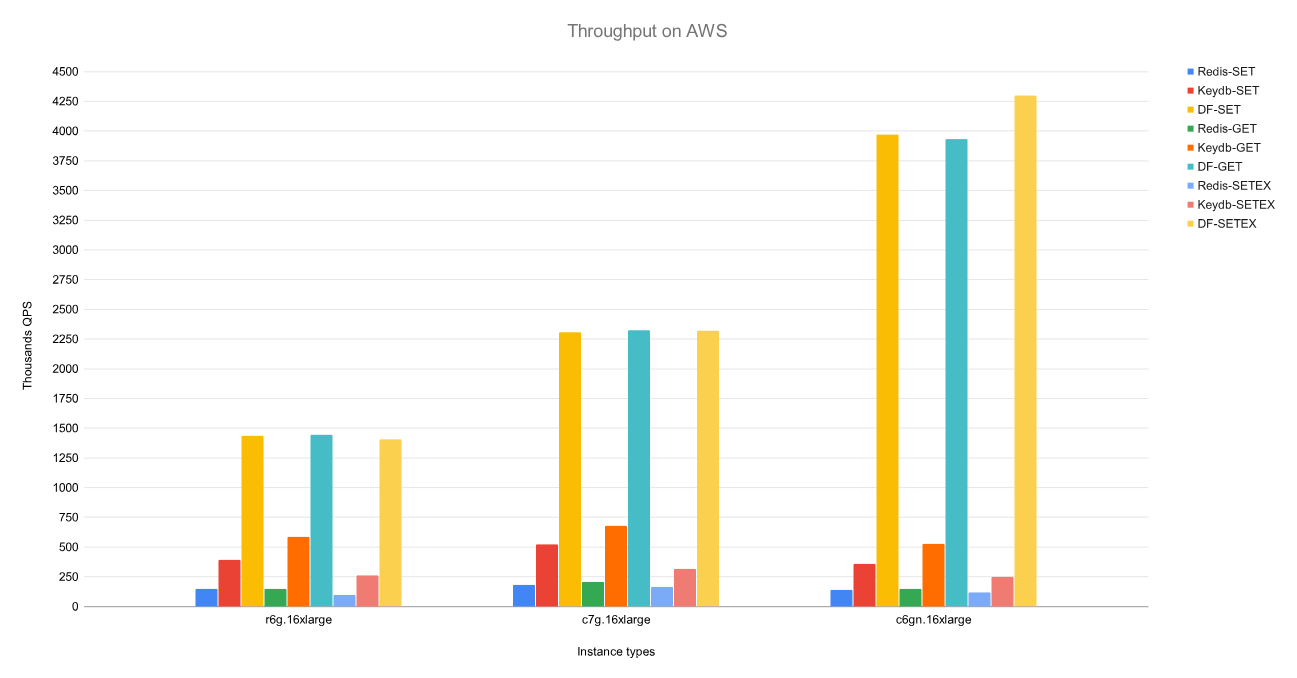
https://github.com/dragonflydb/dragonfly
Dragonfly 是一个现代化的开源内存数据库,兼容 Redis 和 Memcached API,可作为两者的替代方案。与传统的内存数据存储相比,Dragonfly 提供了更高的吞吐量和缓存命中率、更低的尾延迟 (tail-latency),以及便捷的垂直可扩展性。
每日一博
JIT 真的比解释执行快么 —— 关于 JS 引擎的一些热门话题
在编程语言的世界中,如何高效地执行代码一直是一个热门话题。随着脚本语言的普及和性能需求的提升,解释执行和即时编译(JIT)成为了两种常见的代码执行方式。本文探讨了这两种技术,通过详细的实例和深入的分析,为我们揭示了它们的工作原理、性能差异以及各自的优缺点。

开源之声
用户观点
“土猪拱白菜” 演讲者张锡峰后悔为赚钱学计算机
- 观点 1:现在的计算机需要高技术型人才,仅仅完成学校里面的学业是远远不够的
- 观点 2:为了赚钱选择计算机没毛病,996几年考编上岸啊
- 观点 3:我也是村里的,但我不能理解“分不清自家球门和对手球门”,这明显不是有没有钱的问题吧。“私家车接送孩子”,没私家车家里至少有个摩托车、电瓶车吧,难道是没被父母接送过?
- 观点 4:农村娃还真没接触过足球这项运动,留守儿童都是自己回,哪有人接
- 观点 5:去土木打几年灰就老实了
- 观点 6:现在计算机也不行了吗?其他专业还有行的吗
- 观点 7:不是不行,是计算机行业需要的不是劳动力是创新型和高技术人才,学生不管你学得好还是学得不好都是远远达不到现在的需求水平,只能去做一些简单的活,但是简单的活已经没有市场了,缺的是站在顶峰的人才不是劳动力
- 观点 8:极度扭曲的社会环境自然产生极度扭曲的价值观
- 观点 9:相比较而言,计算机的就业还算不错的啦
警惕“付费购买iPhone灵动岛截图”骗局
- 观点 1:如果大家觉得骗子的手法很弱智,那就说明大家不是骗子的目标客户。
- 观点 2:可以入选营销/诈骗经典案例了,一下就筛选出来了喜欢贪小便宜的iPhone用户
- 观点 3:有点搞笑
- 观点 4:放下助人情结,尊重他人命运
- 观点 5:没看懂啊??怎么看着是没有苹果的人想要一个有灵动岛的截图来装逼? 然后骗子反过来通过那些苹果用户赚快钱的心理来锁机?
- 观点 6:后半句是对的,但“想要用灵动岛截图来装逼”也正是骗子
- 观点 7:所以这个产业链能存在就很迷,针对这个畸形产业链再去做黑产那真的是妥妥的......毕竟用户都自动筛选过了
刚被微软砍掉的WSA“整活”了——腾讯接盘、还穿上了马甲「AOW」
- 观点:1:装了应用宝,wsl 用不了,疯狂的是我卸载了应用宝,开了 htper-y ,开了虚拟平台,都不行,这玩意有毒,慎重安装,我觉得我得重装系统了
- 观点 2:我也试过了,需要关闭 wsl 和虚拟化 重启,再开启 虚拟化和 wsl 再重启 貌似不是真的关闭虚拟化平台只是禁用
- 观点 3:一坨答辩,wsa原版能在hyper-v运行,到腾讯就不行了
- 观点 4:以后再衍生出应用宝会员、VIP、SVIP、蓝钻会员、红钻会员、粉钻会员、黄钻会员……
- 观点 5:安装后 wsl 跟 wsa 都打不开了
- 观点 6:又是这个破hyper-v,hyper-害死人
- 观点 7:但是原版可以运行在Hyper-V
- 观点 8:审查才是关键,扯那么远干嘛。
- 观点 9:希望不是国区特供
- 观点 10:现在看起来真的是国区特供
- 观点 11:应用宝桌面版目前还不能自由安装apk,果断卸载了
- 观点 12:安卓模拟器最重要的两个指标,一是性能、二是兼容性,腾讯应用宝在这两方面做的如何呢
- 观点 13:安卓模拟器从来没听过应用宝,只用过蓝叠。听评论区有人说应用宝不能安apk,那我就不明白了,这种屎一样的东西市场份额是怎么占到51%的?
- 观点 14:游戏,腾讯针对自家游戏做了pc适配,可以用键盘玩,而别家的模拟器则游戏会提示非法设备直接封禁
- 观点 15:直接和Google Play合作不香?
- 观点 16:那谁当话事人
中国开源大模型技术有多强——通义千问 “霸榜” 开源榜单、斯坦福团队“抄袭”清华系大模型
- 观点:1:通义的能力和格局,会让它走得更远。
- 观点 2:整个就一学术圈的事(还是本科生),和产业毫无关系
- 观点 3:你们都让开,打扰到我文心一言限速了
- 观点 4:这种就是具象的泡沫,由想要骗融资驱使带来的行为结果,是超出了行业目前合理价值的杠杆部分。
- 观点 5:这篇文章算比较中肯了
- 观点 6:和我想的完全一毛一样
- 观点 7:让现在的大模型写藏头藏尾诗,八股文,模仿聊斋志异的仙狐故事之类的东西还是不行……
- 观点 8:通义千问用着的确很好
---END---
最后,欢迎扫码下载「开源中国 APP」,阅读海量技术报告、程序员极客分享!
