近日,Pinterest品趣志的工程团队最近公布了弃用HBase集群的流程规划,理由是该方案基础设施建设与维护成本过高、HBase专业人才难寻以及产品功能不足。而随着Pinterest也转向Druid"/StarRocks"、Goku"、KVStore、TiDB等数据库技术,技术社区开始质疑在Hadoop和HDFS之上运行非关系数据库的作法是否正迅速衰落。
全球最大的HBase部署体系已经逃离HBase
Pinterest曾经拥有全世界规模最大的HBase生产部署体系,其峰值体量涵盖约50个集群、9000个AWS EC2实例并容纳超过6 PB数据。典型的生产部署由一个主集"群加一个备用集群组成,两端通过write-ahead-logs(WAL)实现相互复制,借此实现更高的可用性。在线请求首先会被路由到主集群,而离线工作流和资源密集型集群操作(例如日常备份)则在备用集群上进行。一旦主集群发生故障,系统将执行故障转移以切换主集群与备用集群。
Pinterest公司高级软件工程师Alberto Ordonez Pereira及高级工程经理Lianghong Xu,解释了这家设计灵感分享平台从由HBase支持的多项在线存储服务,过渡至具有新型数据存储"与统一存储服务的全新架构的过程。
于2013年上线的HBase是Pinterest采用的首个NoSQL数据存储方案。随着NoSQL的日益普及,HBase迅速成为Pinterest内部使用最广泛的存储后端之一。自那时起,它也成为Pinterest技术栈中的基础设施构建块,为一系列内部及开源系统提供支持,具体包括公司的图形服务Zen、宽列存储UMS、监控存储OpenTSDB、指标报告 Pinalytics、事务数据库"Omid/Sparrow、索引数据存储Ixia等。这些系统共同支持多种用例,使得Pinterest能够显著扩展自身业务,并在过去10年间不断扩大用户规模并改进产品体验。
具体影响范围涵盖智能反馈、URL爬虫、用户消息、pinner通知、广告索引、购物目录、Statsboard监控、实验指标等等。
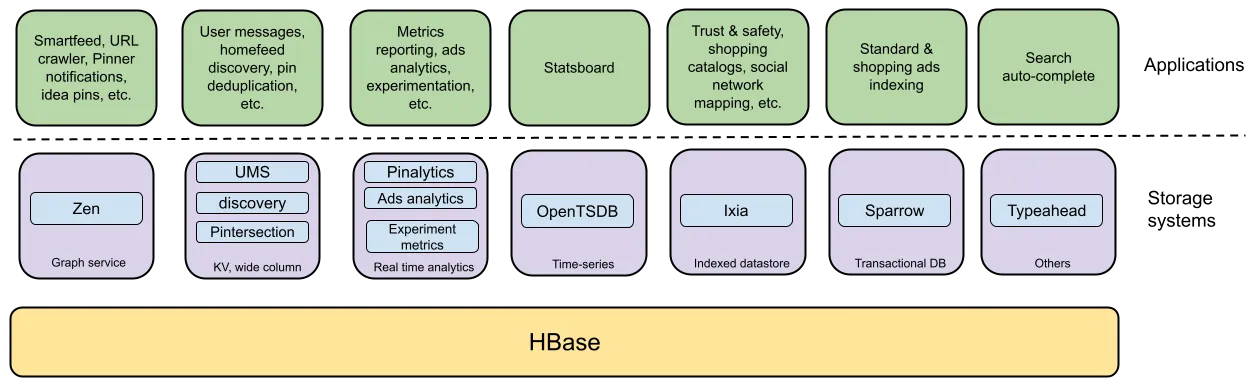
Pinterest的HBase生态系统。HBase为多种服务提供存储后端,也为整个公司内的广泛应用程序提供支持。
为什么弃用HBase?
HBase 项目起源于 2007 年,是 Apache Hadoop" 的一个子项目,并于 2010 年 2 月发布第一个独立版本。从那时起,它不断发展,每个新版本的稳定性和可扩展性都得到了增强。
HBase的灵感来源于谷歌的Bigtable项目,由Java编写而成,是一套基于HDFS构建并供Apache Hadoop使用的键值存储方案。根据Pereira和Xu的解释,HBase是Pinterest的第一套NoSQL数据存储方案,也是这家图像共享与社交媒体厂商使用最广泛的存储后端之一。
自从在Pinterest上线以来,HBase已经凭借实际表现证明了自身的耐用性、可扩展性以及还算过得去的性能。然而经过全面评估并从利益相关方处收集大量反馈之后,公司于2021年底决定放弃这项技术,具体原因他们写道:
HBase的维护成本已经高得令人望而却步,这主要是受到多年技术债及其可靠性风险的拖累。由于种种历史原因,我们的HBase版本落后上游五年,缺少关键性bug修复与改进内容。而且由于长期遗留的构建/部署/配置管线与兼容性问题,Pinterest内部的HBase版本升级又成为一个缓慢且痛苦的过程。
维护成本高企
到评估时,HBase的维护成本已经高得令人望而却步,而这主要是受到多年技术债及其可靠性风险的拖累。由于种种历史原因,Pinterest的HBase版本落后上游五年,缺少关键性bug修复与改进内容。而且由于长期遗留的构建/部署/配置管线与兼容性问题,Pinterest内部的HBase版本升级又成为一个缓慢且痛苦的过程(上次从0.94升级至1.2版本耗费了近两年时间)。此外,为HBase寻找领域专家变得越来越困难,而新工程师的培养门槛也极不友好。
功能缺失
HBase强调提供相对简单的NoSQL接口。虽然能够满足Pinterest内部的多种用例,但其有限的功能配置也确实难以满足客户们在强一致性、分布式事务、全局二次索引、丰富查询功能等实践方面不断变化的需求。举例来说,HBase缺少分布式事务导致Pinterest的内部图形服务Zen发生多种bug和意外事件,原因是局部更新失败可能导致图形效果无法保持一致。调试此类问题往往既困难又耗时,严重影响到服务管理者及客户的情绪和工作/使用体验。
系统复杂性过高
为了向客户提供更多高级功能,Pinterest过去几年间也尝试在HBase之上构建了几项新服务。例如,Pinterest在HBase和Manas realtime上建立起Ixia,用以支持HBase中的全局二级索引。我们还在Apache Phoenix Omid之上构建起Sparrow,用于支持HBase之上的分布式事务。虽然当时根本没有更好的替代方案能够满足业务需求",但这些系统本身也已经造成了巨大的开发成本并成为维护负担的新源头。
夸张的基础设施成本
生产级HBase集群通常要借助具有6个数据副本的主-备用设置以实现快速灾难恢复。但在Pinterest的业务规模之下,这会带来极高的基础设施成本。如果能够将HBase迁移至数据副本成本较低的数据存储方案,显然有望大大降低基础设施的整体运营开销。举例来说,通过对副本及部署机制的精心设计,TiDB、Rickstore和MySQL都能在保持可用性SLA不受太大影响的前提下,实现三副本灾难恢复。
行业使用率与社区使用率双双下降
过去几年来,Pinterest观察到行业内对于HBase的使用率及其社区活跃度似乎稳步下滑,许多同行企业也都在寻求更好的解决方案以替代生产环境下的HBase实现。这种趋势反过来又造成人才供应萎缩、准入门槛提高,导致新人工程师们越来越不愿意学习并培养自己的HBase业务技能。
弃用HBase之路
在 Pinterest,彻底弃用 HBase 曾被认为是一项不可能完成的任务,因为它深深扎根于Pinterest现有的技术栈中。然而,Pereira和Xu的团队并不是 Pinterest内部唯一一个意识到 HBase 在处理不同类型工作负载时存在各种缺点的团队。例如,Pereira和Xu的团队发现 HBase 的表现比最先进的 OLAP 工作负载解决方案更差。它无法跟上不断增长的时间序列数据量,这给可扩展性、性能和维护负载带来了重大挑战。与KVStore (一种基于 RocksDB 和"Rocksplicator"构建的内部键值存储)相比,它的性能和基础效率也不高。因此,在过去几年中,Pereira和Xu的团队启动了多项计划,用更适合这些用例场景的技术取代 HBase。
具体来说,在线分析工作负载将迁移到Druid" / StarRocks",时间序列数据将迁移到Goku"(一种内部时间序列数据存储),键值用例将迁移到 KVStore。经过一系列尝试,该团队找到了在 Pinterest 彻底弃用 HBase 的可行途径。
为了满足其余的 HBase 使用情况,他们还需要一种新技术,它既能提供像 NoSQL 数据库一样的出色可扩展性,又能支持像传统 RDBMS 一样强大的查询功能和 ACID 语义。因此该团队最终选择了TiDB",算是彻底逃离了HBase了。
HBase是否正走向消亡?
Pinterest弃用HBase的消息在社区中引发了剧烈讨论。在《Pinterest为何弃用HBase?HBase是否正走向消亡》一文中,Shivang Sarawagi强调称过去五年来HBase在谷歌引擎上的搜索量始终稳步下降。文章提到:
虽然HBase仍在行业内占有一席之地,但多年来,随着云原生服务的出现,已经有多种替代性解决方案可用于支撑特定系统用例。
在Hacker News网站上的一条热门帖中,用户dehrmann评论称:
我曾在一家大量采用HBase的企业工作。他们从AWS迁移到GCP就是为了向BigTable靠拢……HBase和HDFS的管理强度很高,而且非常不可靠,迫使大家只能随时设置一套故障转移集群。有趣的是,迁移过程中还出现了单元/表退化,这可能也是造成可靠性问题的部分原因。
Pinterest之前曾分享过他们如何将部分工作负载从HBase迁移至TiDB",且不造成任何停机。Sarawagi补充道:随着现代数据库的出现,业界的关注焦点正逐渐从HBase身上移开。然而,还不能说这项技术已经就此过时。
参考链接:
https://www.infoq.com/news/2024/06/pinterest-deprecates-hbase/"