
本文来自微信公众号:腾讯新闻(ID:qqnewstiejun),作者:Leslie Wu(前台积电建厂专家),编辑:苏扬,题图来自:视觉中国
本文介绍了在没有EUV光刻机的情况下,如何通过浸润式光刻机和多重曝光技术来制造5nm芯片,涉及到了光刻工艺、晶体管密度、以及各种技术手段的应用。• 💡 使用浸润式光刻机+多重曝光技术生产5nm芯片完全可行,甚至可以达到3nm
• 🔬 通过调整光刻机的光学参数,如提升sinθ、缩短波长、增加折射率等,可以提高分辨率
• 🛠 利用多重曝光技术、自对准技术等手段,降低k1值,实现更高分辨率的制程节点
你可能不知道,问世超过20年的DUV光刻机,还在发光发热。
使用浸润式DUV光刻机+多重曝光技术生产5nm芯片完全可行,不计代价的情况下甚至能做到3nm。
尽管理论上可行,且在7nm节点上已被部分晶圆厂验证过,但这需要诸多条件同时满足,比如多重曝光中关键的“套刻精度”——多次曝光之间图形对准的精度。
此外,也涉及到许许多多的制程手段,比如相移光罩、模型光学临近效应修正、过蚀刻、反演光刻等,甚至基于最新的定向自组装光刻技术,在不依赖更高分辨率光刻的情况下,也有生产5nm芯片的可能性。
当然,这么做需要付出高昂的成本,一般晶圆厂不会采用这种极端的手段来量产先进工艺芯片,毕竟主流的方案都是经过市场优胜劣汰,筛选出来的最符合商业逻辑的制造方式。
我们先从一个基础知识讲起,但如果你对工艺节点有系统的认知,可跳过第一部分。
5nm是文字游戏?
想要搞清楚浸润式光刻机+多重曝光到底能否做到5nm之前,需要先厘清什么是5nm。正好这两天,也有人把这个话题又拿出来吵,说ASML揭了晶圆厂的老底。
在展开说线宽的话题之前,我们需要知道,晶体管的作用,线宽在这里面扮演的价值。
晶体管通过栅极(Gate)来控制电路的导通和截止,导通代表1,截止代表0,以此来实现二进制计算。栅极长度(Gate length)越小,电流通过晶体管的源极(Source)、漏极(Drain)的速度就越快,即芯片的性能越强。
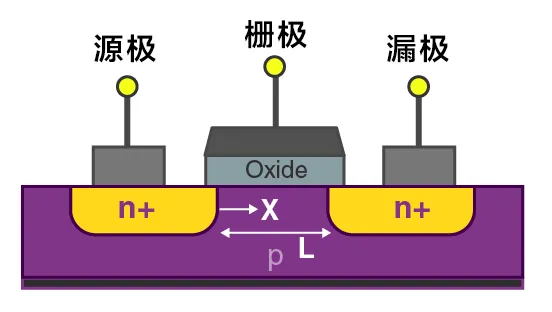
图1:MOSFET场效晶体管平面结构示意图
过去,晶体管的栅极长度被定义为线宽,和工艺节点名保持一致,光刻、沉积、刻蚀、扩散都是缩小线宽的核心制程。
随着FinFET、Nanasheet这些立体的晶体管结构的问世,半导体行业开始突出等效性能的概念——虽然叫14nm,但它的栅极长度远不止14nm。例如,英特尔的14nm工艺,栅极长度是24nm,台积电的7nm工艺,栅极长度是22nm。
另一方面,线宽并不能作为衡量晶体管密度的特征参数,这是因为即便线宽很小,但如果栅极之间的间距很大,单位面积内容纳的晶体管数量依然无法提升。这个时候,如果要表示元件的微缩程度,就需要引出另一个关键指标——周距(Pitch,也有节距的叫法),如下图。比如,过去1个单位面积下有9个晶体管,通过缩小周距,可容纳10个晶体管。

图2:线宽/栅极长度、周距与半周距的关系
90年代,0.35μm以前,工艺节点、半周距(Half pitch,即周距的一半)与栅极长度均一致,但在这之后,半周距、栅极长度与节点的对应关系出现分歧。从下面的图表我们可以清楚看出节点,半周距与栅极长度的关系与演变。
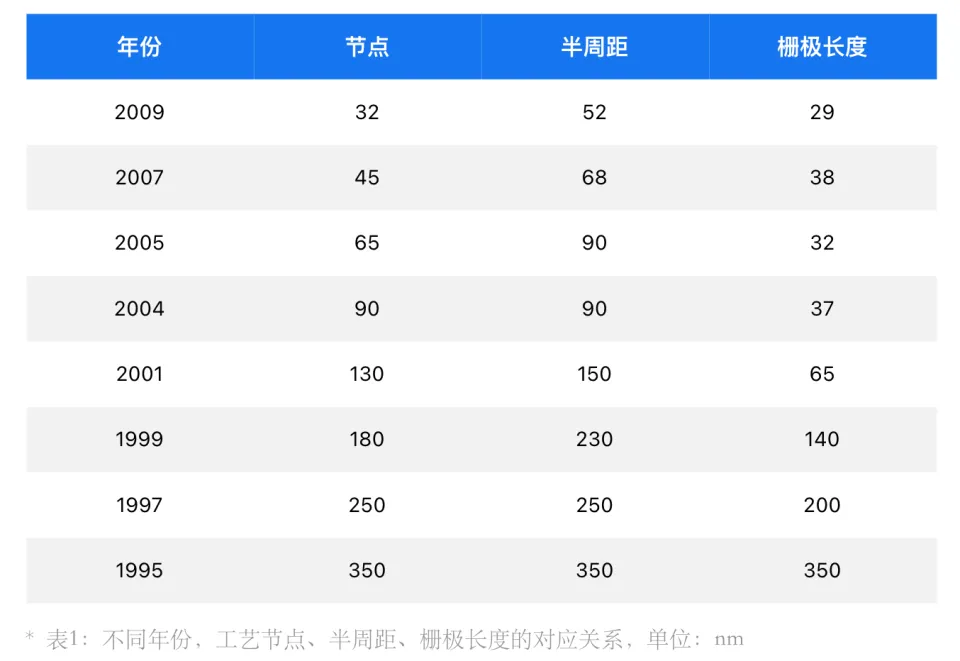
回到最开始的话题,当我们在说5nm的时候,其实只是在说它的制程节点,而并不是实际的线宽。
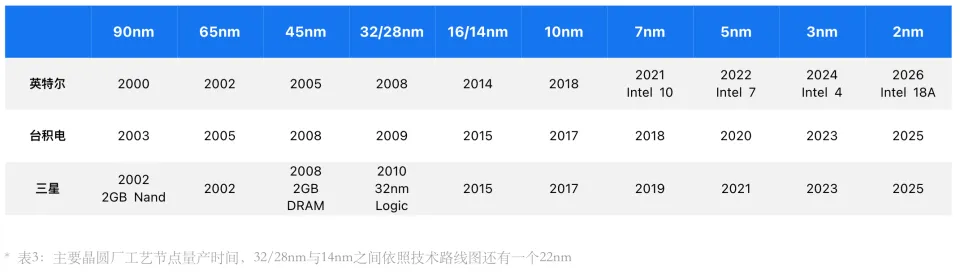
许多朋友喜欢说,现在各家半导体大厂宣称的多少nm工艺都是营销话术,严格意义上,20年前所有工艺节点都是如此。10年前,行业进入14nm的FinFET立体结构时代,则彻底地打破节点、周距、栅极长度与线宽的关联。
没有统一的标准自然会被企业拿来玩文字游戏、模糊概念,三星在其14nm节点上首开先河,台积电为了不落人后马上跟进,但保守的定义为16nm,只有自诩为“摩尔定律”坚定追随者的英特尔,当时还在死磕传统线宽的命名方式,直到2021年才全面修改节点命名,跟随竞争对手的节奏。
但这有问题吗?其实一点问题都没有。
晶体管早就从平面变为立体结构,如果我们把线宽的概念转化为单位晶体管密度(MTr/mm2,即每平方毫米百万晶体管数),会发现摩尔定律并没有消亡,只是以一种不同的形态继续生效——晶体管单位密度仍一直在增加——原本摩尔定律规定的就是“晶体管数量每18个月提升一倍”。
晶体管密度江湖里的搏杀
针对晶体管的各种特征尺寸多而复杂,每个厂商都有不同的定义设计,不同厂商相同制程工艺的产品也不完全具有可比性。
目前直观比较各家制程差异的唯一办法,就是回归摩尔定律的本质,对比晶体管密度,即单位面积内的晶体管数量。
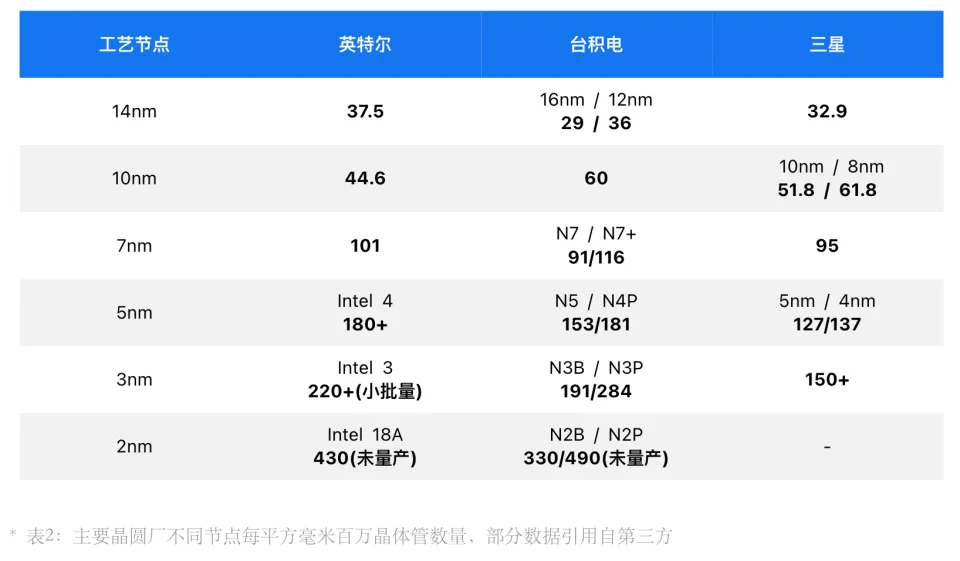
根据上表的数据,在14nm节点英特尔、台积电、三星单位晶体管数量都是每平方毫米0.3亿颗左右。
10nm开始,英特尔将14nm+++改为Intel 10,名字是跟上了,但晶体管数量却成了倒数第一,而三星则是在10nm的优化版,即三星的8nm节点,才提升至与台积电大致水平。
2018年台积电利用浸润式光刻机1980Ci,配合四重曝光技术率先量产7nm,三星在隔年以更先进的EUV光刻机应战,但失去了先机。加上对EUV光刻机的熟悉不足,结果良率低下,最后以自家三星手机放弃猎户座芯片,转而搭载高通芯片以及开出比台积电低30%的代工费用,勉强留下大客户高通。英特尔这时候还在挤14nm+++的牙膏,7nm一役台积电大杀四方。
台积电7nm从DUVi的N7、N7P,到EUV的N7+及N6共四个版本,晶体管密度从0.91提升到1.16亿,三星为0.95亿,英特尔2020年才量产1亿晶体管密度,而在这个节点上,台积电已先一步帮华为生产出全球首款5nm手机芯片麒麟9000,晶体管密度达1.5亿+。
2020年,三星宣布量产5nm,但晶体管密度只从7nm的0.95亿小幅提升至1.27亿,改良版4nm也只有1.37亿晶体管,远远不如台积电初代5nm的1.5亿,与台积电1.8亿的5nm改良版N4P差距更大,只能算作7nm的升级版。3nm节点上,三星也存在类似的问题。
2021年英特尔宣布全面改名节点,英特尔10nm改成Intel 7,原本的7nm改成Intel 4,并把后续节点细化成了Intel 3、Intel 20A、 Intel 18A。英特尔CEO帕特·基辛格虽然提出了4年5个节点的路线图,但实际上Intel 7本身就是已量产的10nm,Intel 4与Intel 3是同一节点的细分优化版本,所以这5年真正要攻克的是3个节点。
根据我们的了解,Intel 18A进度大概率要延后,至少得2026年或者更久,而2025年底台积电第一代的2nm可以量产。但目前苹果3nm和2nm的案子都在跑,明年的A19是否采用台积电的2nm,将会在2025年第一季度视2nm产线的良率做最后定案。这也与去年苹果A17抢发第一代3nm,但升级效果不明显有关,毕竟N4P与N3B,晶体管密度分别为1.8亿、1.9亿,提升并不明显。
所以,今年苹果很可能会改变打法,让台积电继续深挖3nm潜能,比如今年苹果A18将采用N3P,虽说跟去年的A17一样都是3nm,但其晶体管密度从1.9亿到2.8亿。对比其他竞品的3nm,目前晶体管密度都还在1.8亿以下,且都是良率很低的小批量生产。
有一个现象是值得注意的:摩尔定律的节点推进时间从原本18个月到24个月,进入7nm以后则是延缓到30个月,2018年量产7nm,2020年量产5nm,2023量产3nm,2025量产2nm,大概为2~3年推进一代。以目前可知技术来看,1.4nm还能保持目前速度,1nm往后节点大概率拉长到40个月以上,但这只是线宽微缩的放缓,并不影响晶体管数量的提升。
在可以确定的20年内,芯片晶体管的总数将持续快速增长,甚至在单芯片功耗上超越原本的摩尔定律,比如3月份台积电的刘德音与黄汉森在IEEE发表的文章,预测未来10年内,人类就可以制造出一万亿颗晶体管的GPU单芯片,而且未来不再是通过单一的制程手段改善来提升晶体管数量,立体结构的优化、2D新材料以及先进封装每一个技术,都能有效并持续提升晶体管数量。
量产与良率成为模糊地带
过去抢先量产,是英特尔、三星、台积电三强竞争的关键,谁先量产谁就能掌握先机。
但现在,各家对节点定义的差距巨大,比如都说自己是5nm,但晶体管密度天差地别,从这个角度来看,对台积电还有一点点威胁的是英特尔,三星已经不在竞争的行列。
三星还有个玩法就是在良率上动手脚,一个新节点多少良率才算是达到量产水平,这是最说不清的。按台积电的做法,有外部客户愿意基于当前良率下单,并顺利产出才称为量产,也就是所谓的商业量产。
三星每个节点的首发客户基本都是内部的三星电子,一般在低良率阶段开启风险试产并同时对外宣称量产。
将研发中个位数良率拿来宣布量产,这么做只是为了宣传,不会有任何实质意义,因为良率不足的坏片,惯例是由客户承担,同等密度情况下,客户肯定是优先下单给良率最高的晶圆厂。在密度跟良率都落后的情况下,只有降低代工费用才能抢到零星客户,还得承担良率不足的坏片成本,但晶圆厂这么干,没有任何赚钱的可能性。
有一点需要注意,相关厂家有时候会透露自己良率已经到60%甚至80%,但这其中也有模糊地带。一般情况下80%的良率,只是对应矿机ASIC这种简单芯片,手机AP(Application Process,手机中的应用处理器CPU)的良率则有可能不到50%,而如果是GPU这类面积大的芯片可能只有20%出头。
同样的7nm工艺,生产不同产品良率截然不同,但厂家可能只告诉你最好的那个,这也是行业的猫腻之一。
晶圆厂的量产时间与良率是一个可以大做文章的模糊地带,这种对比绝非简单制程节点的同比,而要看单位面积的晶体管密度,以及真正可以拿到商业客户订单的量产时间与良率,才叫商业量产。
2020年,三星宣布量产5nm芯片,看似赢了对手,但一比较两者晶体管密度与良率,就会得出完全相反的结论。
没有EUV,怎么做5nm?
前面的几个部分,给大家讲了过去的5nm、现在的5nm对应的概念。简单总结:20年前如果说5nm,对应的就是线宽,晶体管的栅极长度,但是今天再说5nm,实际上就是一个工艺节点的符号,比起这个符号,单位面积下的晶体管密度才能判断出是否真的是5nm。
接下来,我们将通过一系列的讲解,来告诉大家,在没有EUV光刻机的情况下,通过哪些手段,来实现所谓的“5nm”“3nm”,这部分内容在林本坚博士的《光学微影缩IC百万倍》讲座中也做了非常详细的介绍,我们做了一些简要摘录,先从一个核心的光学分辨率公式开始(提示:这不需要太多数学基础,往下看即能看懂):
半周距Half Pitch = k1λ/sinθ。
Half Pitch:参照文章图2,线宽/栅极长度+线与线的间距即Pitch,再乘以1/2即Half Pitch。
k1:与工艺有关的系数,缩小Half Pitch的关键,是所有晶圆厂光刻工艺工程师致力缩小的目标,也是我们要讨论的核心。
λ:光刻中使用光源的波长,从g-line的436nm,降到EUV的13.5nm,是光刻机制造商努力的目标。
sinθ:与镜头聚光至成像面的角度有关,基本由镜头决定,也是光刻机制造商努力的目标。
不过由于光在不同介质中,波长会改变,在考虑如何增加分辨率时,需要将透镜与晶圆之间的介质(折射率n)一并纳入考量,公式则变成了Half Pitch = k1λ/nsinθ(注:nsinθ即光刻机的数值孔径NA)。
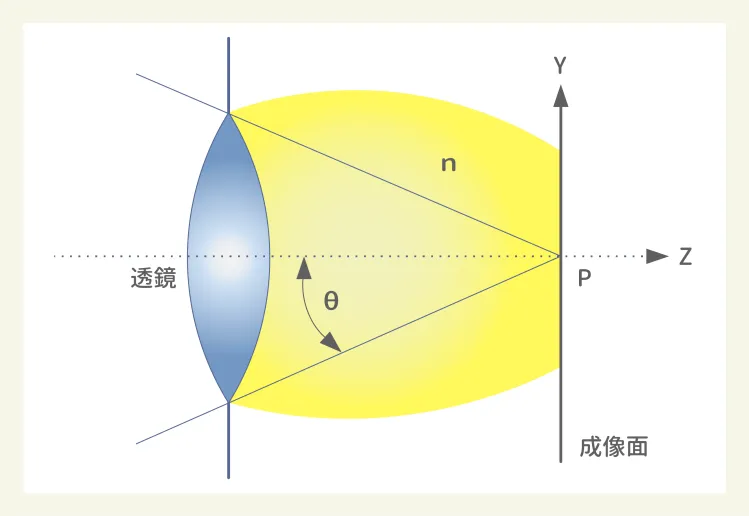
图3:光线通过透镜系统聚焦成像示意图,n为介质折射率,θ为镜头的聚光角度
以193nm光源的浸润式光刻机为例,其k1为0.28,水的折射率n为1.44,sinθ为0.93,其Half Pitch=(0.28×193)/(1.44×0.93)=54.04/1.3392≈40nm,即分辨率为40nm。
所以,如果要提高光刻机的分辨率,可以调整公式中的变量,扩大分母或者缩小分子,对应有四种可能性:即增加聚光角度,提升sinθ、提高介质的折射率n、降低k1系数、采用波长更λ更短的光源。其中,降低k1系数是目前晶圆厂层面最大的突破口之一,可重点关注。
1)提升sinθ:研发巨大复杂的镜头
sinθ与镜头聚光角度有关,数值由镜头决定,sinθ越大,分辨率越高。光刻机所使用的镜头由非常多大大小小、不同厚薄及曲率的透镜,经过精确计算后,仔细堆叠组成的,需要靠起重机来吊装,目前光刻机的镜头系统接近6000万美元,EUV镜头系统甚至超过一亿美元。
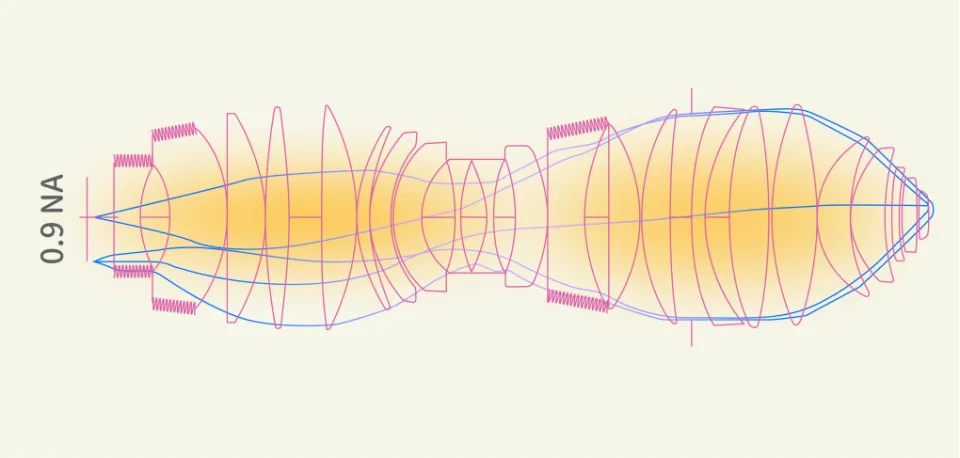
图4:0.9NA光刻机镜头系统,NA(数值孔径)= n × sin θ
做得这样复杂,也是为了尽可能将sinθ逼近理论极值1。
目前ArF光刻机的镜头可将 sinθ值做到0.93,EUV光刻机目前只能达到0.33,Hyper-NA EUV的目标值是0.75,也是ASML的终极项目。如果未来没有新技术发明出来,这很可能是芯片物理光刻技术的终结。
2)缩短波长:材料与镜头的精准搭配
缩短波长主要依靠光源的改变,比如g-Line,i-Line的UV(紫外光),KrF,ArF的DUV(深紫外光)再到目前13.5nm波长的EUV(极紫外光),如果波长再短就是X-ray。
改变光源可以获得想要的波长,但镜头的材料也必须相应改变,材料可选项也会越少。
另一种解决方案是在镜头组中加入反射镜(下图黄色部分),这样的镜头组合称为反射折射式光学系统。不管什么波长的光,遇到镜面的入射角和反射角都相等,以反射镜取代透镜,就可以增加对光波带宽的容忍度。
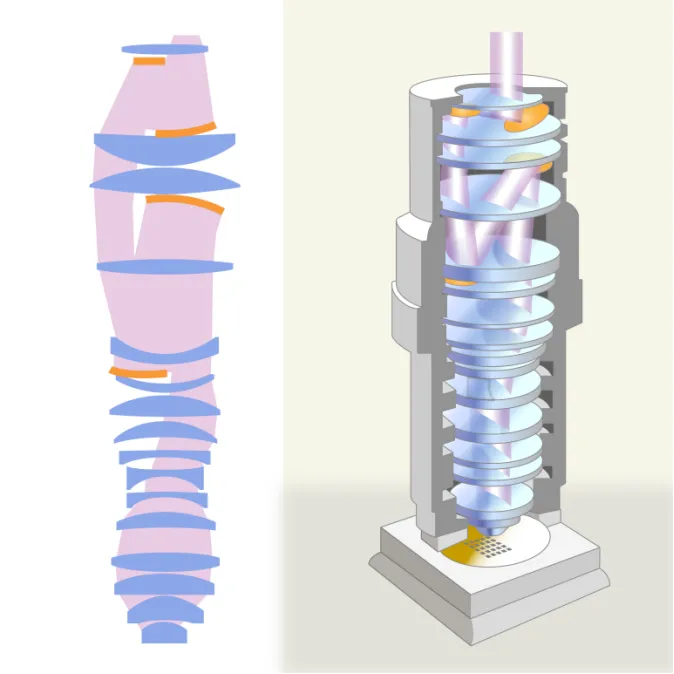
图5:193nm的ArF光刻机所使用的镜头系统,从图中可看到在透镜组合之间加入了反射镜。
到了EUV的13.5nm波长时,整组镜头都采用反射镜,称为全反射式光学系统,这种系统必须设计得让光束相互避开,使镜片不挡光线。此外,相较于透镜穿透的角度,镜面反射的角度对误差的容忍度更低,必须非常精准。
光源改变不仅会影响镜头材料,也牵涉到光刻胶的材料,涵盖化学性质、透光度、感光度等特性,这也是个浩大的工程,需要无数的材料及配方去应对不同制程的layer。其中,感光速度是节省制造成本的关键,每次曝光多几秒,那对芯片制造来说都是不可承受的成本。
3)提高折射率n值:浸润式光刻技术
在增加分辨率的路上,还可以调整镜头与晶圆之间的介质。由前台积电研发副总林本坚提出的浸润式技术中,将介质从折射率接近1的空气,改成折射率1.44的水,形同193nm波长等效缩小1.44倍至134nm。
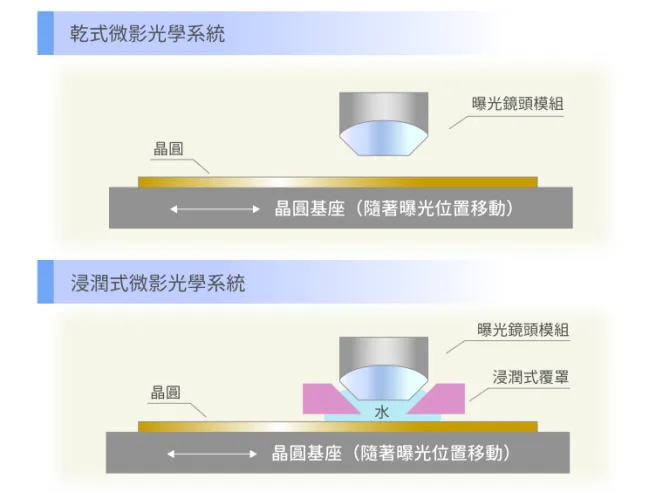
图6:干式光刻系统与浸润式光刻系统的差异
浸润式技术让半导体制程可以继续使用同样的波长和光罩,只要把水放到镜头底部和晶圆之间就好。理论很简单但难点在于,例如浸液系统中的DI Water(去离子水)中的空气会产生气泡,必须完全清除,且要让水快速流动使之分布均匀,保证成像效果。
我们了解过,ASML浸润式光刻机的Alpha机,仅浸液系统,在台积电南科专门跟林本坚团队一起修改了7-8回,耗时两年多。Alpha机完成后的Beta版还得组织庞大的人力在晶圆厂消耗无数晶圆,把原本上千个缺陷,降到几百个、几十个,最后降到零,这是一个艰苦的过程。
4)降低 k1:分辨率增益技术(RET)
提高分辨率的最后一条路,就是降低k1值,这是晶圆厂里光刻工艺工程师工作的重中之重,也是离我们最近的一条路线。将k1降下来,是DUV光刻机制作5nm芯片的关键。
首先要解决的问题是“防振动”,就像拍照防抖一样,在曝光时设法减少晶圆和光罩的相对振动,使曝光图形更加精准,恢复因振动损失的分辨率;其次是“减少无用反射”,设法消除曝光时晶圆表面所产生的不必要的反射。改良上述两项参数,实测的数据显示,基本可以将k1控制在0.65的水平。
进一步提高分辨率还需要使用到双光束成像,分别有偏轴式曝光及相移光罩两种。偏轴式曝光是调整光源入射角度,让光线斜射进入光罩。透过角度调整,这两道光相互干涉来成像,使分辨率增加并增加景深。相移光罩则是在光罩上进行处理,让穿过相邻透光区的光,有180度相位差。这两种做法都可以让k1减少一半,但都属于双光束成像的概念,不能叠加使用。到这里,基本可以使k1控制在0.28。
再进一步降低k1,杀手锏是用两个以上的光罩,也就是大家耳熟能详的多重曝光。最通俗的解释就是将密集的图案分工给两个以上图案较宽松的光罩,轮流曝光在晶圆上(如下图7)。
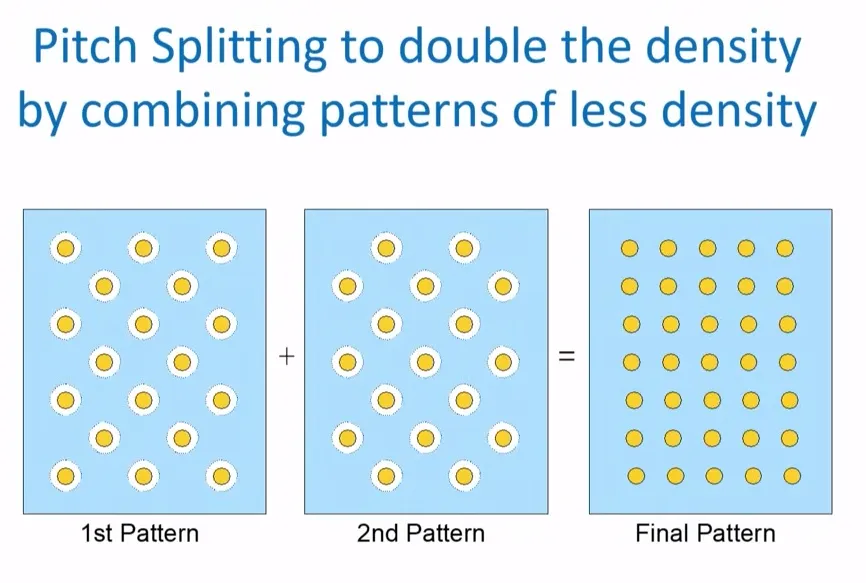
图7:28nm光刻机使用的光罩示意图,光透过白色孔照射在晶圆的光刻胶上呈现黄色圆点,借助2个光罩分两次曝光,以实现分辨率的提升
不过,因为曝光次数加倍,在WPH(晶圆片数/小时)不变的情况下,晶圆产出效率降低了一半,多次曝光也将导致良率的降低,更低的产出加上更低的良率,这对“成本即一切”的半导体行业来说是不可承受之重,而曝光次数增加导致的低产出无可避免,工程师们唯一可以挽救的唯有良率。
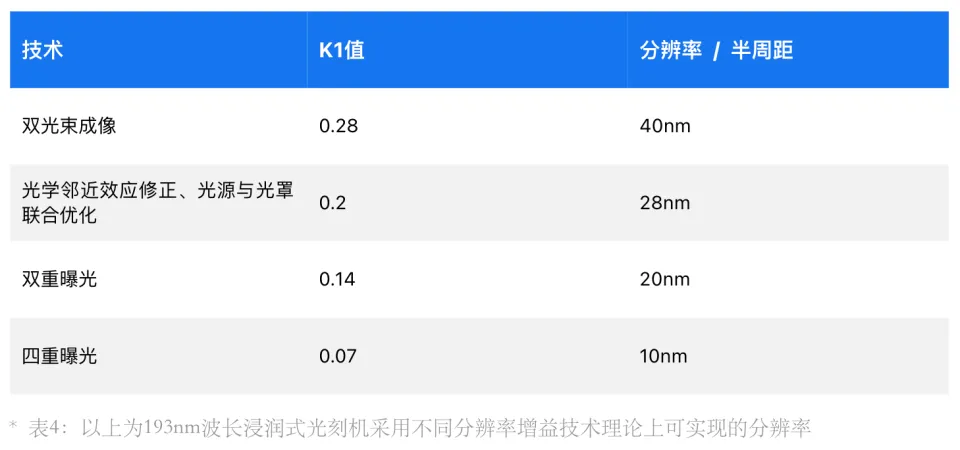
在浸润式光刻机上,叠加使用光学邻近效应修正、光源与光罩联合优化等技术,可以让k1值下探到0.2,分辨率可达28nm。采用双重曝光,k1可以从初始的0.28降至0.14,分辨率则达到20nm。采用四重曝光则可以将k1降到0.07,分辨率达到10nm左右,甚至比EUV光刻机的11.5nm的分辨率更高,这就是浸润式光刻机多重曝光做7nm、 5nm甚至3nm的理论依据。
虽然理论简单,但实践起来就没那么容易,这其中自对准多曝光技术最为重要,借助这项技术可以让k1值成倍缩小,而这项技术最关键的就是光刻机的套刻精度(Overlay),它决定了芯片上下层的对准精度,进而决定了多重曝光的良率。
提高套刻精度的办法之一,就是拿到更高精度的设备,比如2100i DUV光刻机。另外,每家晶圆厂掌握的技术也不尽相同,目前能把多台套刻精度(MMO)做到无限接近单台套刻精度(DCO),全世界仅台积电一家。这是基于光刻机性能以外的know how,有两个数据可供参考:台积电用MMO:2.5nm的1980ci光刻机+四重曝光良率超过80%,而我们大陆工厂用MMO:1.5nm的2050i+四重曝光下,经过2年的不断努力,良率接近50%。
去年,比利时微电子研究中心(IMEC)去年发布了浸润式光刻机借助八重曝光做5nm的技术方案。
其他技术路线上,IMEC和Mentor还共同创建不需添加任何冗余金属,没有额外的电容SALELE(自对准-光刻-刻蚀)技术,以及跳脱了传统使用光罩的光刻,以材料研发为方向,先合成聚合物再加热处理产生特殊的化学交互作用,就会自动对齐成为比原来小四分之一结构的“定向自组装技术”(Directed Self-Assembly,DSA)。
另外,由于EUV太容易被吸收,无法像DUV一样用水折射增加折射率n值,ASML通过High-NA,Hyper-NA提高sinθ这种路径最终会走到尽头,所以晶圆厂制程端,可以大幅度降低k1的多重曝光就成了不论DUV,还是EUV都绕不开的技术。这也意味着沉积与刻蚀设备更加重要,AMAT、LAM、TEL三巨头无不卯足了劲发展相关技术,包括更复杂的脉冲,更精细地控制,更大功率的工具,尤其是原子层沉积与刻蚀技术,都将改变原来的工艺路线。
再回到文章第二部分的晶体管密度表,未来不论节点名称叫“3nm”还是“N+4”,这些都不是重点,重点是芯片晶体管密度是否能够大幅度提升。
本文来自微信公众号:腾讯新闻(ID:qqnewstiejun),作者:Leslie Wu(前台积电建厂专家),编辑:苏扬