
摄影/王若朴
今日(7/1),长春集团、和硕联合科技、长庚医院、欣兴电子、科技报橘和专攻法律AI的律果科技,与台大资工系、台大资管系就联手揭露台湾繁中大型语言模型(LLM)计划TAiwan Mixture of Experts(简称Project TAME),以70亿参数的开源模型Llama-3 70B为基础,使用5,000亿个Token和Nvidia开发者计划技术训练而成,具备石化、电子制造、医疗、媒体内容和法律等在地专业知识。Project TAME目前于GitHub上开源,团队希望借此抛砖引玉、吸引更多产业伙伴加入,来形塑台湾产业专用AI应用生态系。
今年初发起计划,3阶段打造这款繁中LLM
早在今年1月,这些参与者就发起Project TAME,要打造繁中LLM。目前坊间虽有不少强大的LLM,如GPT系列、Claude系列、Llama系列模型等,但Project TAME主要开发者台大资工系博士班候选人林彦廷表示,对本土企业和组织而言,仍需要表现稳定的繁中LLM才行。
于是,这些本土企业联手台大,要打造这个繁中优化的模型TAME。该模型经3大阶段训练而成,包括利用台湾本土资料进行连续预训练,再来是生成多轮AI对话资料、进行微调,最后是模型与使用者真实互动,透过使用者回馈来微调模型。
但光是第一阶段,团队就面临2大难题:本土训练资料来源,以及各领域专家确认资料来源与品质。为解决这个问题,他们采用聚集各领域专家、提供相关资料的模式,来因应资料不足的挑战。而这些资料来源,包括了占所有训练资料三分之一的合成资料(如合成教科书内容等),约1,000亿Token左右,以及其他来自媒体、石化、法律、医疗、化工、制造业制程、游戏等资料,包括来自网页、社群平台、资料库、书籍、程式码等。(如下图)

接著,在技术部分,团队训练的基础模型有两种,包括Meta的80亿参数模型Llama-3 8B和700亿参数Llama-3 70B,采用Nvidia NeMo、Nvidia NeMo Megatron两种训练框架,以及3D平行化、DeepSpeed Zero网路通讯优化器和Flash Attention等加速方法与工具,来训练TAME模型。在推论部分,他们采用Nvidia TensorRT-LLM框架执行,另使用Nvidia建置的Taipei-1超级电脑(搭载DGX H100)算力来驱动模型训练与推论。
让模型饱读诗书、具备繁中基础知识后,接下来就进入第二阶段:监督式微调。在这阶段,首先会从资料中取出提示,模型会根据提示来自我对话、生成多轮对话,最后根据这些对话资料来进行监督式微调。这些对话资料涵盖了通用型和知识密集型资料。
完成对话微调后,再来就是最后一阶段,也就是透过模型与真人互动,来根据人类回馈微调模型,确保模型产出与人类偏好一致。为此,团队也繁中LLM竞技场添加TAME,让民众在平台上提问,并根据2个模型给出的回答,来评估模型表现。透过这种方式,就能进一步改善TAME模型的不足之处。
.png)
在地文化理解力、专业知识能力实测皆第一
完成3阶段的训练后,接著,团队利用标准化测试题目,来评估Project TAME模型表现。
首先是包含各种本土考试科目的语义理解基准测试TMLU,不只有国高中文科、数理化等考题,还有教师资格、领队、驾驶等考题。经测试,Project TAME的平均分数为71.3%,与Claude 3的73.6相差无几,还胜过GPT-4、Gemini、Llama 3等模型。(如下图)
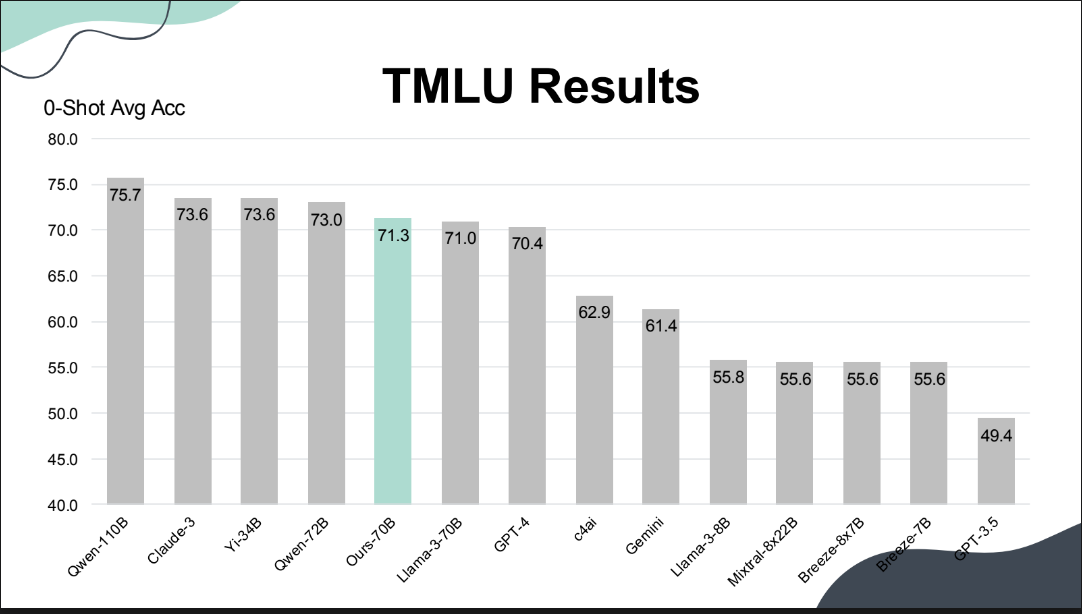
再来,Project TAME模型还具备在地文化知识,能根据在地文化提示(如网友戏称哪一项早餐店的产品有通肠效果)给出正确回答,正确率是所有评测模型中的最高的,达79.4。
特别的是,Project TAME还在台湾律师考试的选择题部分拿下好成绩,总共209题中拿下60.8分,一样是所有测试模型中的最高分(如下图),意味著TAME具备台湾法律知识,比Claude-3(60.3)、GPT-4o(53.6)、TAIDE 8B(37.8)等模型还要厉害。

Project TAME正式对外开源,不少领域已有初步应用
目前,Project TAME已正式开源,企业可免费下载使用,民众也能至模型聊天页面测试。另有亚太智能机器(APMIC)整合Project TAME,提供聊天机器人测试页供使用者测试。
林彦廷表示,为降低企业部署门槛,未来Project TAME可能朝混合专家模型(MoE)形式发展。因为,MoE由好几个专家模型组成,可想像为各有各的擅长领域,因此相较于同参数量的传统LLM,MoE可以其中一个或多个专家来回答问题,以较经济的方式使用运算资源,进而降低模型推论成本。
另一方面,根据团队说明,Project TAME 700亿参数模型符合企业导入的低成本需求,估算只需1,600万台币、短短3.5小时(模型迭代一次)就能利用企业内部资料训练模型,大幅降低导入成本和时间,可优化企业在运营管理、人员训练、产品服务、客服等AI应用。
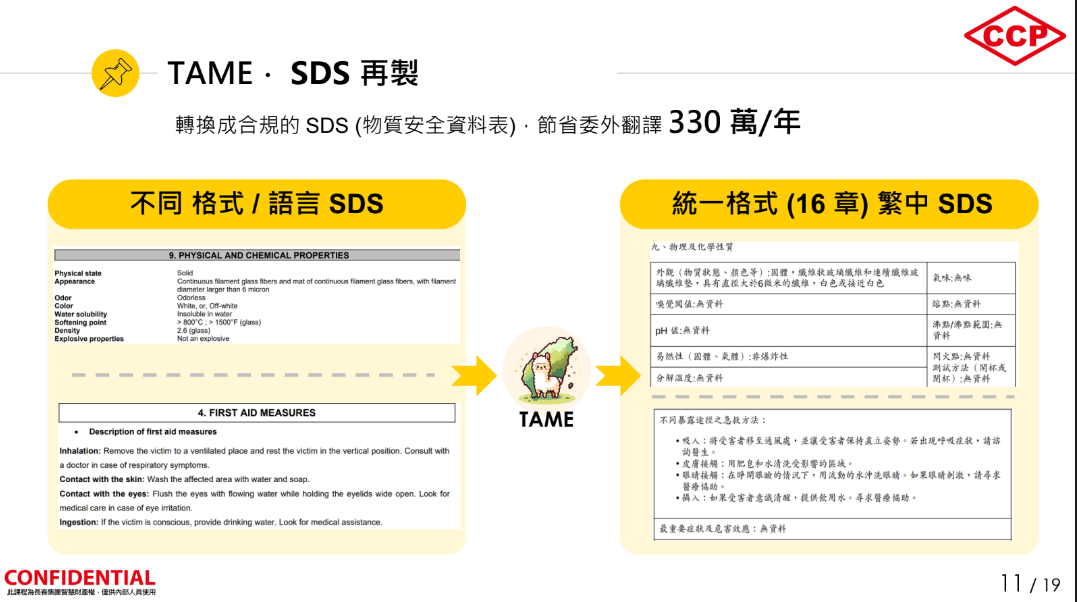
在实际应用上,则涵盖了电子制造、石化、医疗、法律和媒体等领域。以长春集团为例,他们就应用TAME于自家助理iGenie,搭配RAG资料库,可正确使用繁体字回答公安问题,还能将不同语言、格式的物质安全资料表(SDS),正确转换为中文版本,预计每年可节省330万元的委外翻译费用。(如下图)
此外,长春集团也将TAME用于自家Email服务,如新建摘要、内容提示等,也用于会议逐字稿与摘要生成。
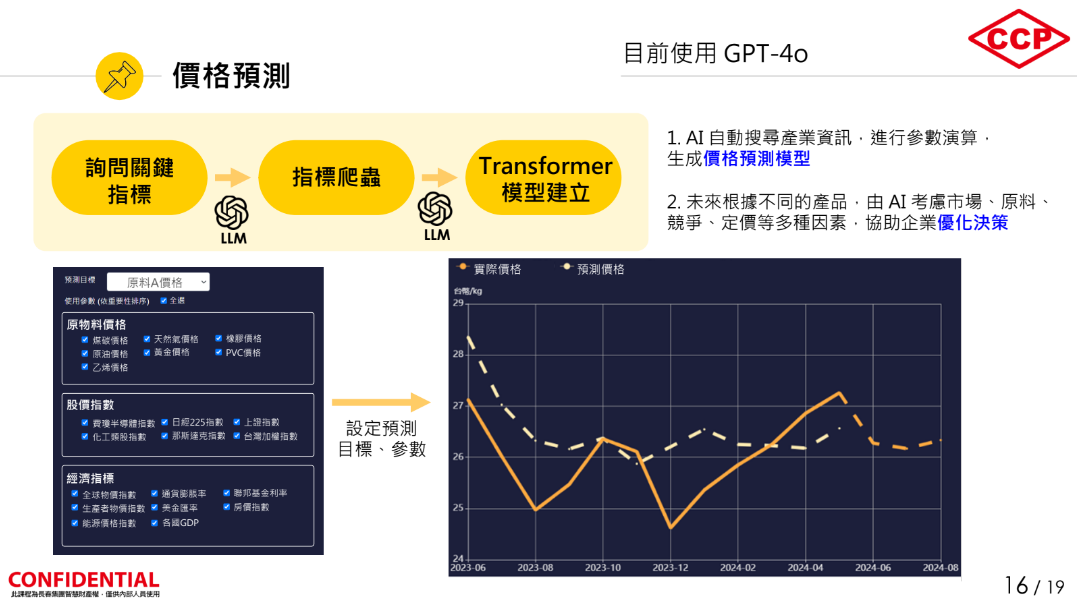
长春集团资讯中心资深协理黄至善表示,希望TAME更精进,未来可用于原物料价格预测、企业战情中心资讯分析和机器人大脑等3大领域。进一步来说,就价格预测而言,长春集团起初以回归或时间序列模型测试,发现效果不好。
后来ChatGPT这类LLM兴起,他们开始投入研究,其做法是先向LLM(使用GPT-4o)询问价格预测的指标,接著再询问LLM,这些指标出现在哪些网页、能否写支爬虫程式,来协助抓取指标资料。有了资料,最后再询问LLM可用哪种模型来执行预测并写一支预测程式,在得到LLM给出的Transformer程式后,团队将指标资料输入模型,得出的价格预测准确度可达7成,比过往方法有效。不过,他们也分析预测不准确之处,考虑多添加重要新闻,来强化模型表现。(如下图)
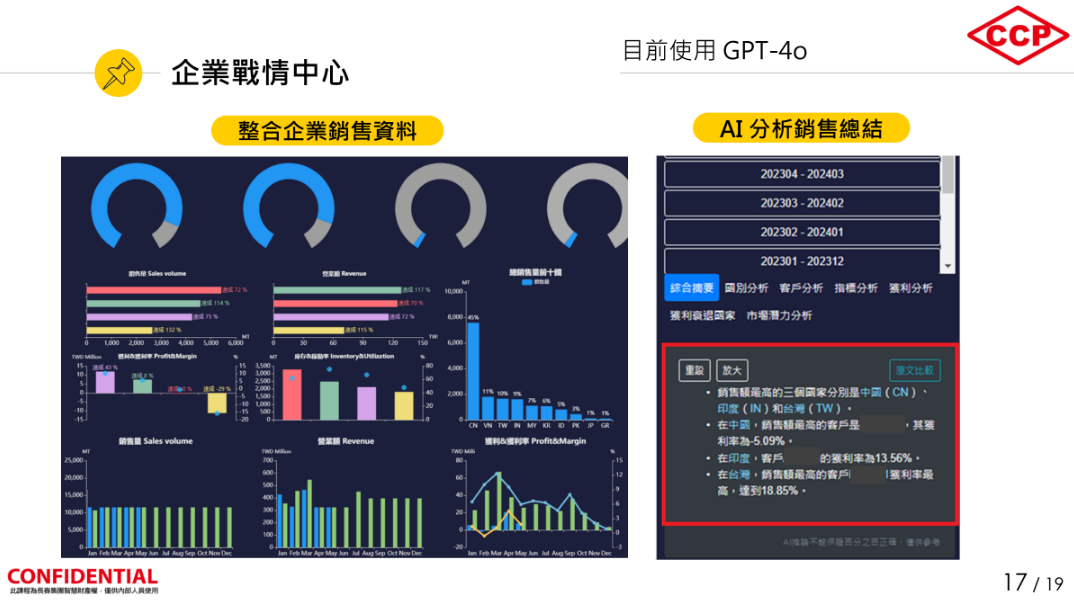
就战情中心来说,长春集团资讯中心将过去2年、去识别化的内部销售资料与财务资料,再加上外部的关键经济指标,来让ChatGPT分析。他们很惊讶地发现,LLM可给出人类分析师没注意的洞见,因此可呈现在战情中心仪表板,结合其他资讯和互动式设计,来提供另一种资讯分析服务。(如下图)
在机器人部分,长春集团希望打造通用的实体机器人,可在石化业危险场域代替真人作业。他们也与台大合作,以LLM作为机器人大脑,透过自然语言指令来执行任务,如巡检、仓储物流等,预计明年会有进一步成果。