#articleCont {
font-size: 16px;
line-height: 1.6;
color: #333;
word-wrap: break-word;
}
#articleCont :first-child {
margin-top: 0 !important;
}
#articleCont h1,
#articleCont h2,
#articleCont h3,
#articleCont h4,
#articleCont h5,
#articleCont h6 {
margin: 40px 0 20px;
}
#articleCont h1 {
font-size: 24px;
}
#articleCont h2 {
font-size: 22px;
}
#articleCont h3 {
font-size: 20px;
}
#articleCont h4 {
font-size: 18px;
}
#articleCont h5 {
font-size: 16px;
}
#articleCont i {
font-style: italic;
}
#articleCont p,
#articleCont div {
word-wrap: break-word;
margin: 14px 0;
text-align: justify;
}
#articleCont blockquote {
border-left: 6px solid #ddd;
padding: 5px 0 5px 10px;
}
#articleCont blockquote p:last-child {
margin-bottom: 0;
}
#articleCont .simditor-body blockquote :last-child {
margin-bottom: 0;
}
#articleCont a {
color: #82b64a;
}
#articleCont a:visited {
color: #82b64a;
}
#articleCont a:hover {
color: #74a342;
}
#articleCont img {
max-width: 100%;
height: auto;
}
#articleCont hr {
margin: 19px 0;
border: none;
border-top: solid 1px #ddd;
}
#articleCont ol {
list-style-type: decimal;
}
#articleCont ol li {
list-style-type: decimal;
}
#articleCont ul {
list-style-type: disc;
padding-left: 40px;
}
#articleCont ul li {
list-style-type: disc;
}
#articleCont table {
width: 100%;
font-size: 12px;
border-collapse: collapse;
line-height: 1.7;
}
#articleCont table thead {
background: #f9f9f9;
}
#articleCont table th,
#articleCont table td {
border: solid 1px #ccc;
text-align: left;
vertical-align: top;
padding: 2px 4px;
height: 30px;
min-width: 40px;
box-sizing: border-box;
}
#articleCont pre {
white-space: pre-wrap;
}
- 全文目录如下:

一如“万物皆可百度”、“万物无难事,只要肯百度”所言,搜索在我们生活中早已成为习以为常的事情。毕业季的我们会在每日99+的群聊信息中搜索所需的信息;工作一上午后会点开外卖,找找看今日有没有想吃的午餐;晚上回家路上,打开社交平台,搜索看看今天都有什么头条新闻...
点下搜索的瞬间,结果已出现在屏幕上,快速又便捷。殊不知在小小的屏幕之下,搜索引擎井然有序地在其巨大的数据库中,完成了检索、排序...
一、搜索
“当你终于将相关的所有信息搜罗到手后,你会做什么?”
作家詹姆斯·格雷克在《信息简史》中所言,信息洪流中,各种应对策略也随之出现。方法多种多样,但归根结底,本质上可归为两类:要么是过滤,要么是搜索。
现时代,我们每个人都能力去自由地生产、消费信息,海量的信息涌入数据库。心理学家斯坦利·米尔格拉姆的一项社会网络实验“六度分隔”中所证,这个星球上的每个人之间最多相隔六个其他人。
信息亦如此,在复杂的网络中,事物与事物之间拥有很高的连通度,但并非所有的连接都是有价值的,这些异乎寻常的连接度使得信息的搜索变得困难重重,搜索似乎变成了一件无边无际的事情。
90年代末,有人预测在如此庞大的信息中完成检索是不可能的,但至今,虽然搜索引擎在某些时候仍不尽人意,但已经具备了基本功能。
搜索介绍
维持生命力的方式就是让“血液”不停的流动,从古至今人类一直寻求更新、更快的连接交互方式。
搜索加速了信息的流通,打通了海量数据之间的自守状态,信息走向了开放。用户可以快速的获取到高价值的信息,企业和平台也可通过搜索推送给用户信息。我们可以更准确的找到结果,同时也可以看到更多相关的内容。
搜索是对互联网上的信息资源进行搜集、整理、检索的一项互联网技术。产品的搜索功能发展至今,提供给用户的已不仅仅是信息输入的搜索框,面对用户主动地推荐,引导用户消费产品中优选高质量的内容。
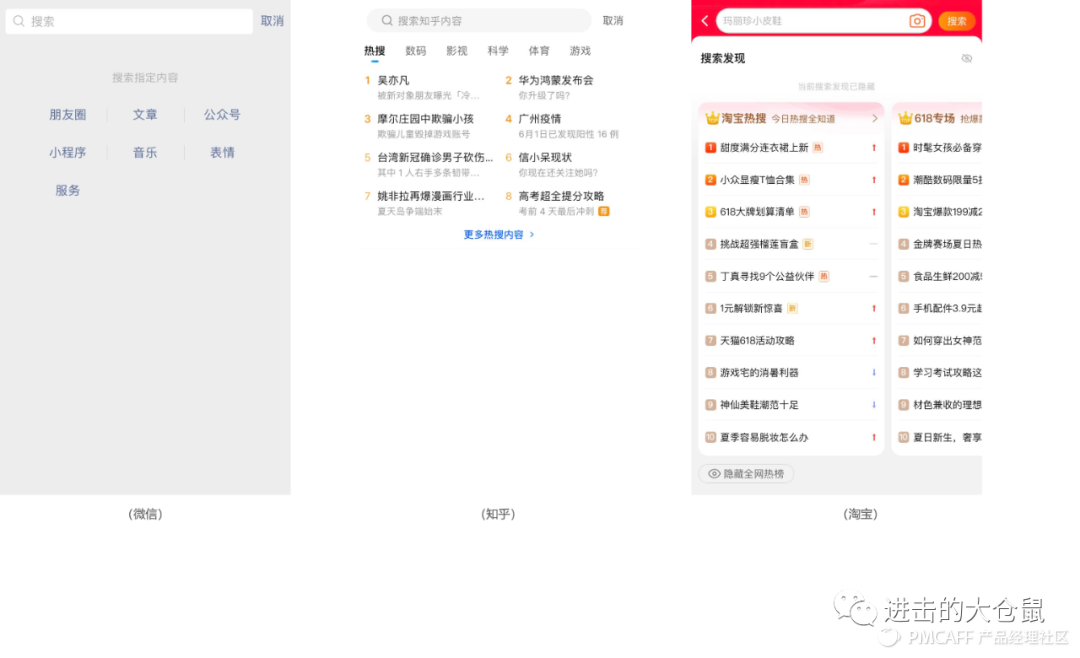
可以说搜索带给了我们全新的数字生活,在不胜其扰的信息中,消费者依赖于各种检索,来区分精华和糟粕。尤其是对于新手用户来说,还可以快速地了解到产品中包含的服务模块,如下图,分别为微信、淘宝、知乎的搜索界面。
- 微信为一款手机通信软件:通过搜索,提供给用户的内容包括有朋友圈、文章、公众号、小程序、音乐、表情、服务;
- 知乎为一款问答社交软件:提供时事热榜、数码、影视、科学、体育等栏目;
- 淘宝为一款线上购物软件:主要解决用户的购物需求,在搜索界面可以看到的功能模块有搜索记录、热搜推荐(商品内容)。
二、搜索引擎
搜索引擎简介
搜索引擎是一门检索技术,其核心模块一般包括爬虫技术、检索排序技术、网页处理技术、大数据处理技术、自然语言处理技术等;根据用户需求、一定算法、特定策略为用户提供高速、高相关性的信息服务。
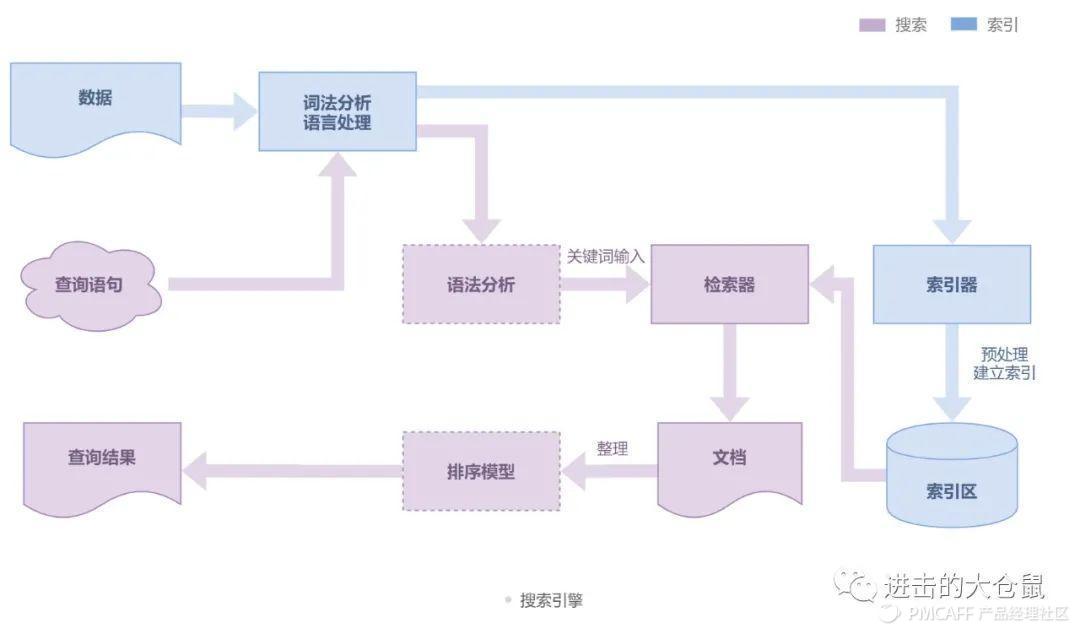
搜索引擎基本结构一般包括:搜索器、索引器、检索器、用户接口等四个功能模块。搜索引擎通过其结构来实现搜索工作,基本原理可分为信息采集模块、查询表模块、检索模块。

搜索引擎流程
我们从APP、网站、小程序等不同载体中看到的搜索框,实际只是搜索引擎系统提供给用户的检索界面,当我们输入关键词,点击查询后,搜索引擎对我们输入文本进行复杂的分析,并从庞大的数据库中获取所有相关的信息,根据一定的排序策略将检索结果呈现至用户界面。
不同搜索引擎有各自的搜索策略,其索引的获取、query的分析、排序的算法不尽相同,因此在不同产品的搜索引擎搜索相同的query会获得不同的结果;当前搜索引擎收集用户行为数据,着力个性化推荐,同一产品不同时期检索某一关键词,也可能会获得不同的结果页。
具体流程如下:
搜索引擎类型
提及搜索,我们脑海中马上浮现的大概有百度、谷歌、淘宝等电商平台搜索框、微博等社交平台搜索框等。这些我们常用的搜索引擎,主要是全文搜索类型以及垂直搜索类型,除此之外,搜索引擎的类型还包括目录搜索、元搜索检索、集合式检索、门户搜索引擎等等。
- 全文搜索:全文搜索从互联网上提取网站信息,对海量的数据进行有效的管理和快速检索,最常用的全文搜索引擎有百度、谷歌等;
- 垂直搜索:垂直搜索引擎是针对某一行业的专业搜索引擎,是搜索引擎的分支和延伸。相较于通用搜索引擎,提供深度、准确性更高的搜索服务。垂直搜索引擎的应用方向很多,比如企业库搜索、供求信息搜索、购物搜索、房产搜索、人才搜索、mp3搜索、图片搜索、工作搜索、交友搜索等,几乎各行各业、各类信息都可以进一步细化成各类垂直搜索引擎。
2.1 分词
分词是我们在搜索功能中较常听到的词汇之一。
分词就是对一段文本,通过规则或者算法分出多个词,每个词作为搜索的最细粒度一个个单字或者单词。分词的目的主要是为了搜索,尤其在数据量大的情况下,分词的实现可以快速、高效的筛选出相关性高的文档内容。
搜索过程中,分词由搜索引擎内的分词器,执行完成。分词器作用于用户的输入内容、以及文档索引建立的这两部分。前台文本内容的输入,来源于不同用户的需求;索引数据的来源可通过业务需求决定,自定义设置。
如在垂类电商业务中,我们构建索引的原始数据,便可以是商品的标题、详情、类目信息、品牌信息等,或者是从后台建立新的字段,分词过滤后进入索引区,等待检索。
2.1.1 分词流程
用户在搜索引擎界面输入关键词,点击“搜索”按钮之后,搜索引擎程序开始对搜索词进行以下处理:分词处理,根据情况对整合搜索是否需要启动进行判断、找出错别字和拼写中出现的错误、把停止词去掉。
分词的实现主要依赖分词器。分词器为分析器三大构成部件之一,文档的分词还会涉及到分词前的预处理,以及分词后的过滤操作。分析器的三构件分别为:字符过滤器、分词器、过滤器,文本在三者间流转顺序依次为字符过滤器—分词器—过滤器。
原始文本在分词之前,会流转到字符过滤器,将原始的文本作为字符流接受,通过增、减、改的方式改变字符流。处理后的流进入分词器,按照特定规则、算法执行分词操作,最后通过不同的过滤器进行处理。一个分析器中可以有0个或多个字符过滤器和过滤器,仅有一个分词器。
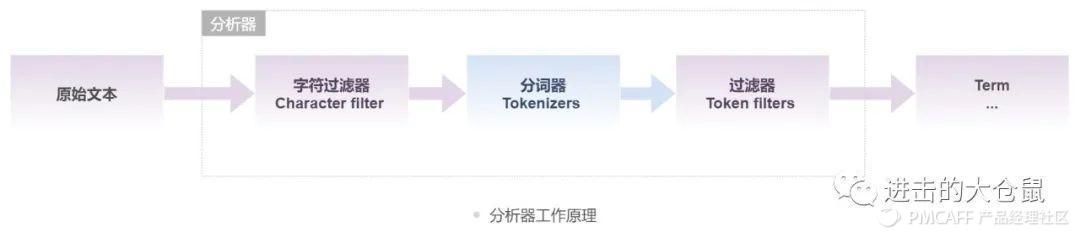
- 字符过滤器:字符过滤器用于字符流传递到分词器之前对它进行预处理,字符过滤器支持数字的转换;将所有指定的字符串替换成特定的字符串;将任意字符转换为置顶字符。
- 分词器:不同语言分词规则有所差异,英文分词、中文分词、拼音分词的分词策略各不相同。英文分词可以根据空格将单词分开,中文分词比较复杂,可以采用机器学习算法来分词。
- 过滤器:将切分的单词进行加工。如大小写转换、去掉停用词(如“最”、“因为”、“和”)等,该过滤器不同于检索时过滤器。

2.1.2 分词的算法
现有的分词包括有英文分词、中文分词、拼音分词。中文分词与英文分词有所区别,中文分词存在更多的难点和歧义点,不同分词策略对文档的召回率和精确率影响较大。
英文单词与单词之间,在输入时就会通过空格、逗号、句号去隔开,较好的去识别。而中文由字和字构成词,由词汇构成句子。如何去合理切分,且可以精确传达用户本意、需求,是中文分词的难点。拼音分词与中文分词的结合,更全面地处理了用户简写、误输入等使用场景。
拼音分词可以用来分析字词的全拼、首字母全拼、字词的完整拼写等,可以进行自定义的设置。拼音分词配合中文分词,完整关键词的过滤流程,达到高效分词的目的。
中文分词算法主要分为三大类,基于词典的分词、基于统计的分词、基于有序标注的分词。

不同的分词策略要适应于各自的业务场景,可能有些业务场景需要分词的精度大于速度,有些场景要求速度大于精度,因此在理解分词原理的基础上,如何去配合业务的需求,高效地实现分词功能,这些都给算法工程师提出了更高的要求。
2.1.3 分词的使用
在搜索过程中,分词器使用于文档的索引流程以及用户输入文本的检索流程中,需注意的是索引流程和检索流程中所使用的分词器需一致。
- 索引使用:原始文本预处理后,使用分词器将文档内容切分为单个字词;
- 检索使用:用户输入文本对象,分词器进行分词处理,分词后建立query对象,执行检索操作。

中文分词相较于英文分词,无空格作为词之间的分隔符,且中文词语组合复杂,歧义较多,一直为自然语言处理中的难点。
2.2 构建索引
索引是对数据库表中一列或多列的值进行排序的一种辅助型数据结构,构建索引有助于对表中数据的查找和排序,检索时数据库系统不必扫描整个表,而是直接定位到符合条件的记录,大大加快了查询速度,达到了以下目的:
- 快速:加快检索数据
- 筛选:尽快找到符合限制条件的记录
构建索引大大缩短查询时间的同时,也带了了一定的成本,创建和维护索引都需要时间成本和空间成本,随着数据量的增加其所占用的物理存储空间也会随之增大。数据量大、经常使用查询功能,且需要排序优化的业务情境下,索引的建立还是很有必要的。
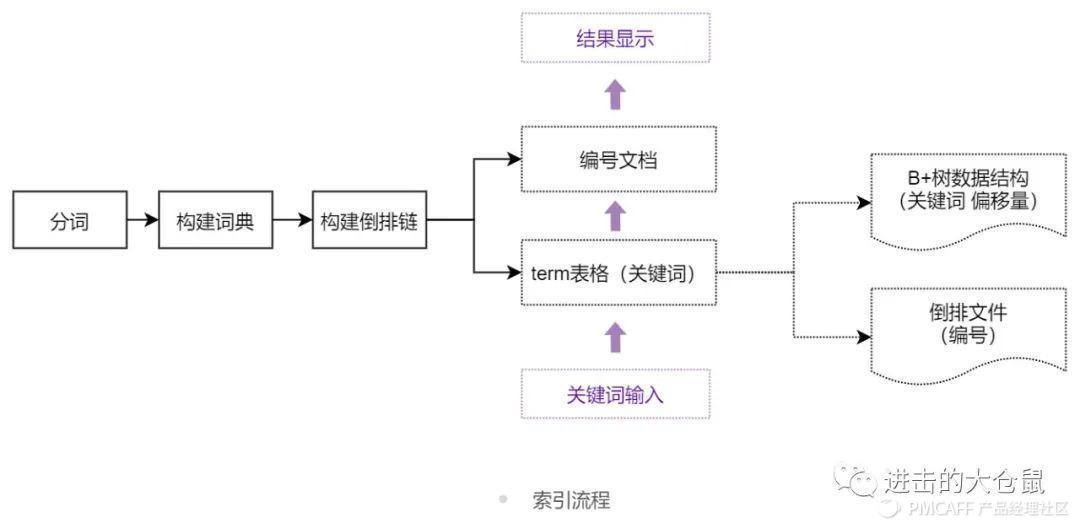
索引的构建,主要有倒排序索引和正排序索引。倒排序索引是对关键词进行索引,以求快速得到匹配文档集;正排序索引对文档进行索引,方便于排序、过滤、汇总。倒排序索引和正排序索引是搜索引擎的重要数据结构,之后检索等的操作都建立在此基础上。
2.2.1 倒排序索引
1)倒排序索引介绍
倒排索引(Inverted index),也常被称为反向索引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。
索引是为了更快找到文档的一种数据结构,相当于图书中的目录,用户根据目录可以快速找到所需内容。倒排索引不是根据目录或编号来定位内容,它是通过文档中的某个字、词语而找到文档的索引类型,通过立即的单词标示迅速获取结果。倒排索引的建立和维护较复杂,但查询快速、便捷、高效,是文档检索系统中最常用的数据结构。
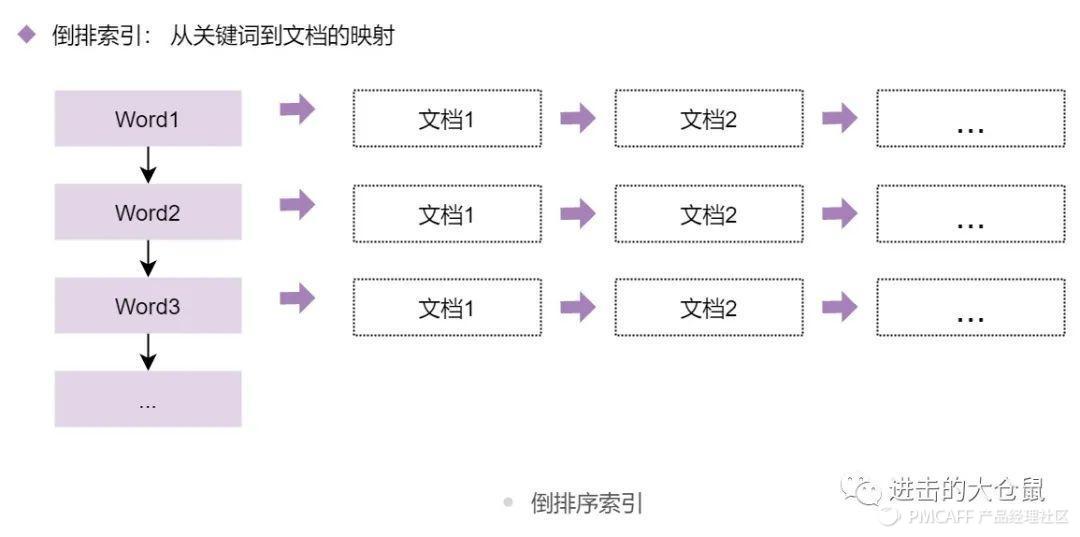
2)倒排索引的构建流程
倒排序索引的构建有两个表格至关重要。表一为文档编号及文档内容,表二为分词后关键词及对应文档编号。数据的存储时,将表二拆分为两个数据结构,用于存储倒排文件以及关键词及其偏移量。
搜索最基础、简单的流程便是外部关键词输入,表二中查询到关键词出现的位置以及文档编号,最终输出结果文档内容。
2.2.2 正排序索引
正排索引(forward index),以文档编号为关键字,表中记录文档中每个字的位置信息,查找时扫描表中每个文档中字的信息直到找出所有包含查询关键字的文档。正排序索引的查询往往满足每个文档有序、频繁的全文查询和每个单词在校验文档中验证这样的查询。
正排索引可以查询汇总到关键字的属性、相关的频次以及位置等,适用于一些过滤操作以及汇总操作。
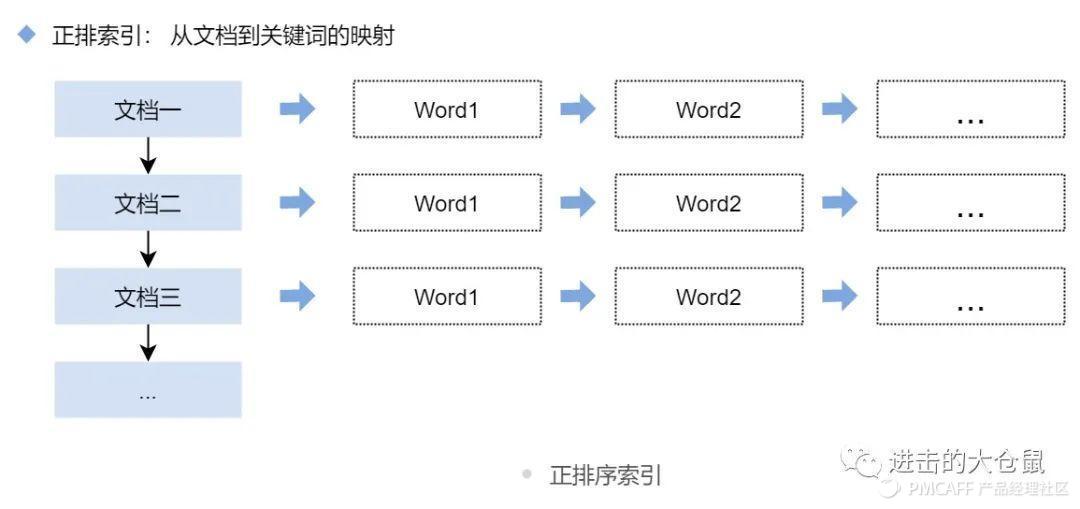
比如说搜索 “干饭”时,可以快速查询出包含“干饭”这个关键字的文档,有利于关键字相关性和权重的计算。正排序索引,搜索“干饭”时,搜索引擎需要检索每一个文档中的每一个关键词,正排索引适合于一些区间的索引。在电商的搜索中,有较多的过滤、筛选的选项,因此同时引入正排索引和倒排索引还是很必要的。
2.3 检索
检索就是将信息按一定的方式组织和存储起来,根据用户的需要、信息属性、特征分,利用检索工具找出有关信息的过程和技术。
在检索之前,搜索引擎会经过大量文本数据的的收集,以及处理。但是对于用户来说,最关键的并不是找到所有结果,将查询到的所有信息展现给用户没有太大的意义,也并非用户的真实意图,过多的信息浏览和筛选反而会给用户带来糟糕的产品体验。
如何恰当的理解用户搜索内容的本意,如何在上千万的页面信息中把最相关、最切合需求的结果排在最前面,推荐给用户选择,才是搜索更好服务用户的关键。
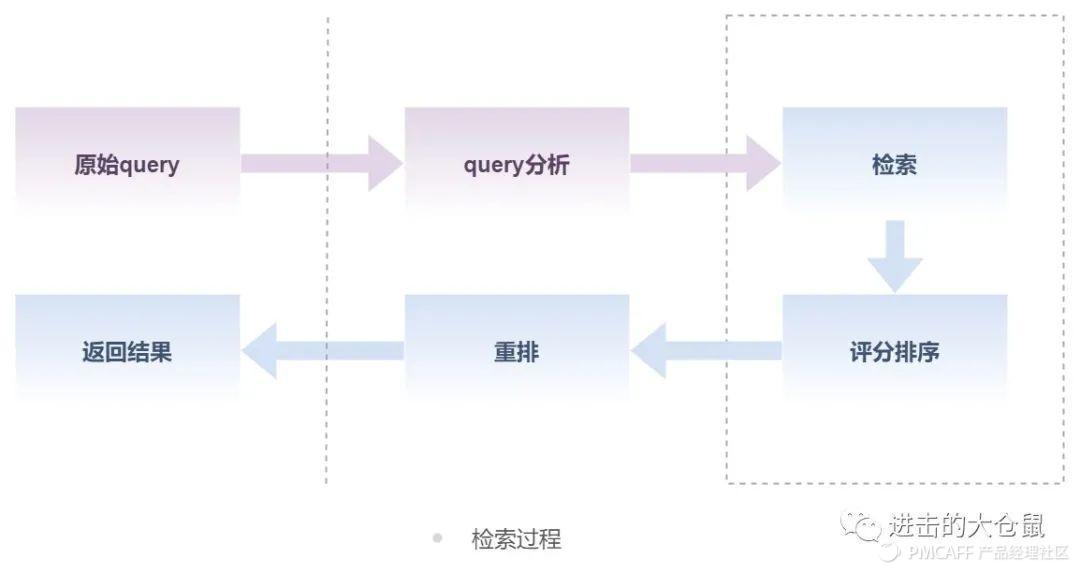
2.3.1 检索流程
检索流程由用户特定的信息需求出发,采用一定的方法、技术手段,根据一定的线索与规则从中找出相关信息,将最终结果返回至用户界面。经过了分词处理、query分析、评分排序、打散重排等流程。在检索过程中需要在意前台用户输入原始文本与返回结果的相关性,以及返回结果的重要程度,并依此排序展示。
相关性是指返回结果和输入query之间的线性关系的强度和方向,重要性是指商品被信赖的程度。如何把相关性强、重要度高的结果返回给用户,如何根据业务需求去权衡现阶段产品带给用户的价值、合理分配评分权重,尤为重要。
其在商品繁杂、用户需求模糊的电商的搜索场景下,商品的评分、排序策略可以减少用户鉴别商品的成本,带来优质的用户体验和转化。
2.3.2 Qurey分析
检索过程中的关键技术有很多,其中最著名的是query分析技术。
Query分析是对用户原始文本分析、理解实际意图的过程,是标准的自然语言处理的任务。用户在表达意图时,原始query的组织会出现各种各样的表达形式,和检索语料语义表达相同,但是文字描述可能会出现相差较大的情形,如:
- 用户地方性语言的表达差异化,原意想要搜索钢琴,拼音输入 “gangqing”;
- 为快速搜索,只输入首字母等,原意搜索天气预报,输入“tqyb”;
- 在中文字符输入的缺字、错词、惯用称呼等情况,原意为王者荣耀,输入为“王者农药”;
- 从其他地方整段文字的摘入,原始文本的不完整和其他字符的代入;
- 陌生词汇的搜索,如想要搜索 “宿摊” ,并不是很清楚想要查询内容的读音,就会有 “宿摊”、“咒术宿” 等有误的输入;
- 搜索信息冗余,带有诸多商品属性,原意搜索为冰箱,输入“冷冻食物大容量冰箱”;
- ..
Query分析可能会涉及到原始文本的分词、音形转换、词语过滤、词性标注、纠错、归一、意图识别等,实际应用和前台显示包括有我们常见的搜索联想词、相关推荐、关键词预测等。处理后的检索词可以快速、准确的查询出值得用户信赖的优质结果。
面对用户形式多样的意图表达,可能会出现查询结果不符合用户意愿、或者是无查询结果的情况,因此对检索字符的分析可谓是关键一步。
2.3.2.1 拼写纠错
用户在输入文本搜索时,内容不一定完全正确,可能会出现别字、纯拼音、模糊音、拼音汉字混合等问题,在这种情境下就需要提供给接错功能,提升用户体验。
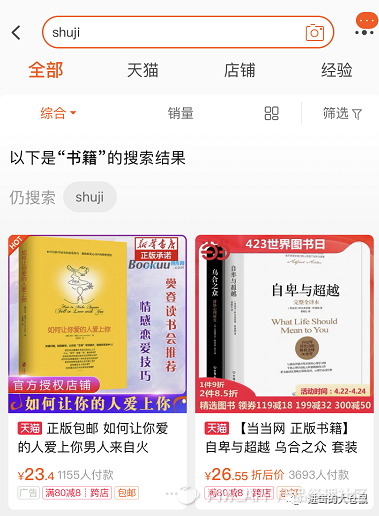
拼写涉及复杂的流程,如下图所示,以淘宝搜索为例,用户在搜索框输入 “shuji” ,原意为“书籍”搜索,判定文本属于全拼输入的问题。点击搜索之后,页面展示为书籍的搜索结果,但仍然提示是否搜索 “shuji” ,点击 “仍搜索shuji”,呈现包含 shuji 关键词的内容。
可见在对query进行纠错时,对于可以产生搜索结果的关键词进行了原query的保留,以及拼写纠错的操作。用户在搜索过程中,提示用户仍按照原query搜索,或者是选择纠错后query进行搜索,在对用户意图把握不准确的情况下,提供给用户自主的选择权。

1)拼写纠错
在英文中,最基本的语义单元是单词,单个英文词的拼写和组合都可能会出现失误,因此在英文拼写纠错流程中,错误类型可以分为两种:Non-word Error 和 Real-word Error , 假词错误和实词错误。
Non-word 为拼写为不存在的单词,如将 “fight” 拼写成 “fght” ;Real-word 为拼写正确但是结合上下文语境,表达意思错误的情况,如 “too much ”,拼写成 “two much”。
在中文中,最基础的语义单元是字,用户通过键盘输入的字符不会出现错字的情况,但是会在输入过程中因为拼写错误,出现错意的情况,因此以拼音作为发音中文,其纠错主要基于拼音纠错。
拼写纠错包括以下步骤,首先对原query的进行相应的拼音扩展变换,得到与原query读音相似的候选集;接下来将优选的纠错query,与原文本进行比对,判断是否进行拼写纠错、纠错文本的优先级等;最终将决策好的结果展示给用户。
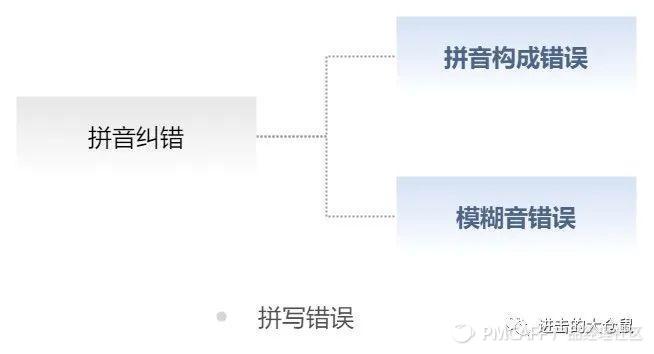
- 拼音构成错误:拼音构成错误,即用户输入无法构字、不存在的拼音形式,多字母、少字母、错误输入字母。类似于英文拼写错误中的Non-word Error;如 “ag — ang” 、“uoi— ui ” 等,都为实际不存在的拼音形式。
- 模糊音错误:模糊音的错误,即用户输入为可构字正确拼音形式,受到地域性语言文化的影响,会出现前后鼻音、平卷舌音不分;对相似读音输入有误等情况。类似于Real-word Error; 如 “ pin—ping ”、“nan—lan”等,都为可构词,表意有误的拼音形式。
2)可信度分析
原query的拼音构成与纠错词越接近,可信度越高;纠错词与原文本对比,原文本被替换的字词越多,该纠错词的可信度越低;原query文本内容越短,出错的几率越小,纠错词可信度相应降低;原query在索引有结果,非不存在词汇,纠错词的可信度相应降低。
可信度高的纠错,会直接用到纠错后的查询词执行本次查询;可信度低的纠错,还是用原查询词执行本次查询。如上文举例 “shuji” 搜索,无法准确判断用户意图时,可将原关键词以及纠错后的关键词,于前台展示,由用户做出选择。
2.3.2.2 词权重分析
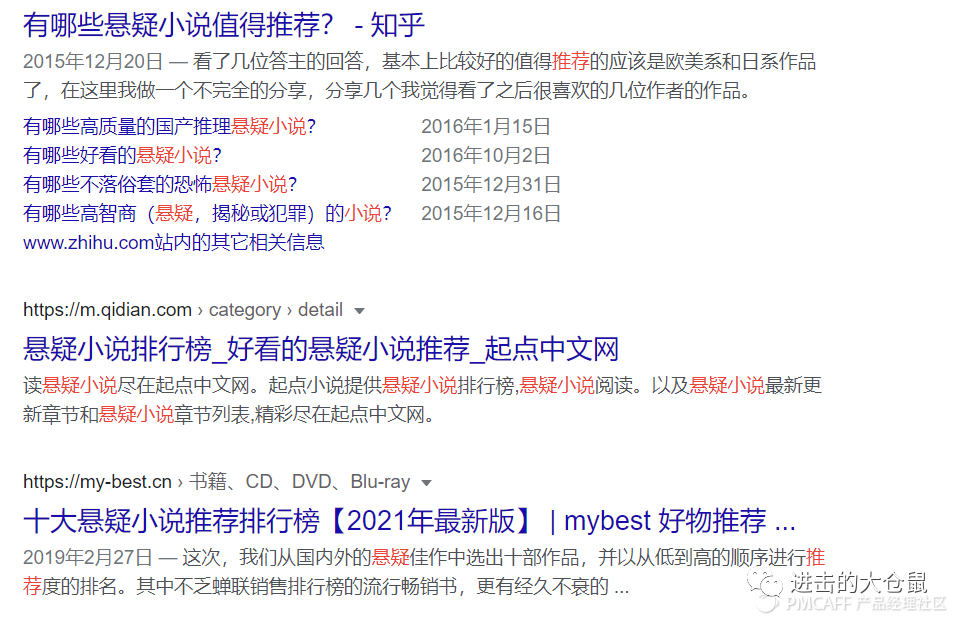
词权重是检索查询中每个词的重要程度,将其量化为权重,权重较低的词可能不会参与召回。
如在google中查询“有什么悬疑小说推荐”;经过词权重的处理,包含“悬疑小说推荐”的文档会被保留召回。如下图,被标红召回的词有 “悬疑小说”、“悬疑”、“小说” 、“推荐”。
2.3.2.3 实体识别
实体识别全称为命名实体识别(Named Entity Recognition),简称NER,识别实体的边界和类型,如文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等,在电商行业中包括材质、款式、尺寸规模、场景、颜色、服务、品质、影视名称、后缀等。
确定实体边界主要和分词相关,发现命名实体首先需要截取部分与定义相关的特征词,如query为 “鬼灭炭之郎同款耳饰”,NER任务从query中提取信息:
- 影视名称:鬼灭之刃
- 人名:炭治郎
- 后缀:同款
- 品类:耳饰
目前在NER表现良好的模型基于规则、深度学习、统计学习,其在查询实践中,主要用于query改写和类目预测中。
1)query改写
Query改写是query分析的一个重要组成部分。query改写可以生成系列相关的query,并将选取重要性、可信度最高的一个query召回。精确召回结果数不够时,选取相关Top querys同原始query一起参与搜索,扩大召回,得到更准确、丰富的匹配结果。
Query改写的召回策略有基于点击的统计、query自身、session、词典同义,主要目的是为了学习字、短语粒度的语义信息,从而扩展到其他query;利用模型解决相关判定的问题;最后选择原query以及重要性高的query召回。如用户搜索 “欧美凉鞋” ,得到可信度高的改写词 “罗马鞋” ,与原query一起参与召回。
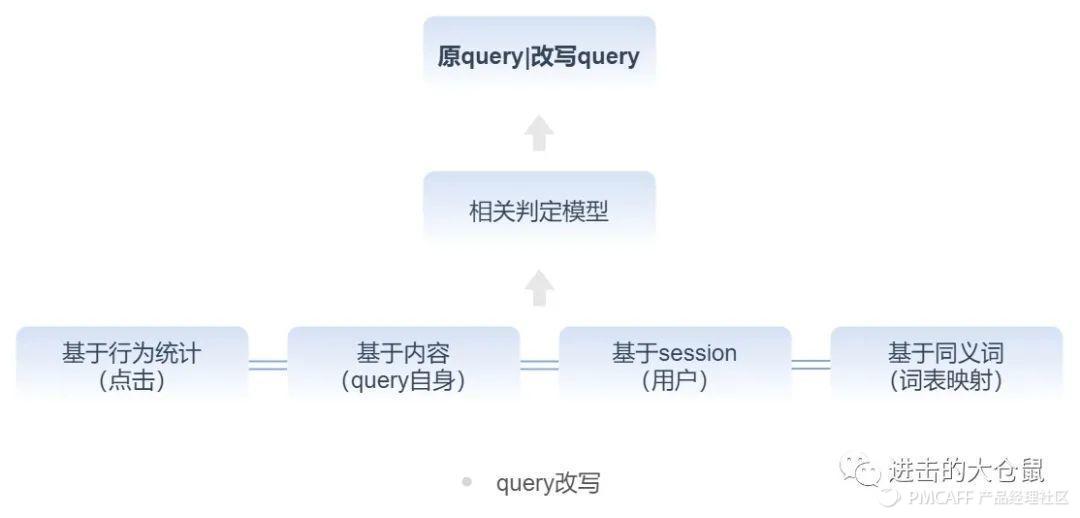
query改写会根据其重要性、优先级去选择实体进行召回。重要性高,重要性中、重要性低的实体,在查询配置中按照相关召回策略,召回匹配结果。
2)类目预测
电商类目中,每一件商品都会挂在某一叶子类目之下,并有多个上级类目;某些活动商品可能会从属于多个前台类目。
电商后台商品的数量、类目复杂繁多,再加上用户在电商平台的搜索时,原query可能会出现无类目预测结果、与多个类目相关、长尾query繁多、类目重叠等情况,如用户输入 “红色” ,对原query进行类目预测,可能预测出服饰、鞋包、配饰等类目。用户输入“男鞋”,会关联到多个类目运动、母婴、服饰鞋包下。
类目预测模型可选取人工方式、统计文本类目相关性、语义相关模型匹配等方式,预测用户意图,类目预测对用户搜索结果可以产生较大影响。
- 人工方式:项目初期可以采用人工的方式配置query,提升用户的搜索体验。在用户数据不是很庞大的情况下,通过统计用户搜索、点击等行为,统计出使用频次高的query相关类目。
- 统计文本相关性:通过统计词和类目,利用一些方法进行相关性得分、彼此关联性的计算;从类目维度求和得出每个词与类目之间的重要性,以及权重值。
2.3.3 排序
搜索结果排序可以说是查询服务中的关键一步,决定了搜索功能的优劣和用户的满意程度。搜索引擎对检索结果的排序,涉及两个排序流程,包括基础排序以及业务排序,即粗排和精排。
在基础排序中主要是对相关、相似文档的抽取排序,以及规划业务逻辑排序所需的top n文档数量。业务排序是更为精细化、个性化的排序策略,针对不同业务下的设计相应的评分策略,完整产品可提供给用户的服务。
- 基础排序:从大量的网页文档中,取出主词对应的TOP N 个结果再进行精排;
- 业务排序:搜索引擎从TOP N中,经过更复杂的排序规则,将最终结果返回给用户。
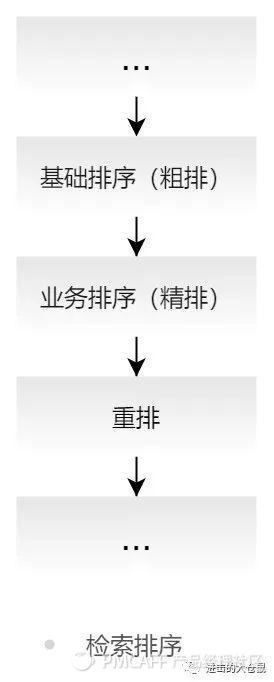
在电商搜索中,基础排序和业务排序中的排序方法可以包括相关性排序、商品属性排序、个性化排序。
2.3.3.1 相关性排序
使用搜索系统时,用户希望获得的,并非是全部的查询结果,大量重复的信息会给用户造成困扰。理想的排序需要使用评分函数,去评估文档和用户查询之间的度量和评级,根据相关度的高低评判合理的分数值,再加上权重控制,成为最终文档排序的依据。被使用的评分函数,包括有TF-IDF、Length Nromdeng 。
TF-IDF相关性排序:TF-IDF(Term frequency / Inverse document frequency)是一种基于信息检索和文本挖掘的常用加权技术。TF/IDF的概念分为TF、DF、IDF介绍。
- Term:Term分词后的最小单位,如“我喜欢吃火锅”,“我”、“喜欢”、“吃”、“火锅”,每一个词为一个term。
- TF (Term frequency):词频,即某一个给定term在该文件中出现的频率,公式为 Nt / N ,给定term次数/总term数。TF对词数的归一化,防止偏向较长的文件,同一个词语在长文件中出现的频率高于在短文件中出现的频率,不管该词的重要程度。如上文中的“火锅”的TF为1/4,TF越高该term在该文件中越重要。
- DF (Document frequency):文档频率,即某一个给定term在总文档中出现的频率,计算公式为 包含给定term的文档数/文档的总数量 Dt/D。
- IDF(Inverse document frequency):逆文档频率,与DF相反,公式为 log(D / Dt),用总文档数除以包含给定term的文档数,再求对数。term出现的文档数量越多,权重越小,IDF越高,信息量越大,就越能体现term的重要性。
- 信息量(Amount of information):在日常生活中,极少发生的事件一旦发生是容易引起人们关注的,而司空见惯的事不会引起注意,也就是说,极少见的事件所带来的信息量多。如果用统计学的术语来描述,就是出现概率小的事件信息量多。因此,事件出现得概率越小,信息量愈大。即信息量的多少是与事件发生频繁成反比,即事件发生的概率为P,那么他的信息量就是 -logP。
TF-IDF将 TF*IDF 两个值相乘,表达该term的相关性。
TF从term出现的次数、频率这一方面,计算给定词的重要性;IDF从信息量的角度出发,去判断term的信息量值,两者的乘积可以去掉一些高频、信息量较低的词,如“的”、“是”、“和”这类词频较高,信息量较少的词。
2.3.3.2 商品属性排序
商品属性通常包括关键属性、销售属性、商品属性、普通属性这四种,平台可以根据自己的需求,为商品附加新的属性描述。
本小节所提及的商品属性包括你能想到所有与商品本身相关的特征属性,如与商品描述相关的商品标题、商品副标题、商品详情等;与品类相关的前后台类目、各级分类,包括一级分类、二级分类等;与用户行为相关的属性,包括曝光率、下单数、浏览次数、用户评论、发货速度等,来作为评分因素影响商品的排序。其中的属性还可以进一步细分,如用户评论中可以细化到评论数、好评率、差评率、评论图片数、追评率等。
用户在搜索时,60%的用户会选择搜索到的前四页推荐商品进行购买,就本人而言,在购买一些生活日消品时,会在综合排序的topN中,筛选销量最好的商品。
而且不同场景下的消费者,消费意图不同,比如第二天需要出差,急需旅行用品,就会挑选距离近、配送快的商品。如何去权衡属性分配的权重,成为搜索的难点,搜索排序排序的优化,还需要工程师们持续的投入。
2.4 搜索引导
2.4.1 联想词
联想词即我们在搜索服务中常见的下拉提示词,主要通过前缀匹配,在用户执行点击搜索行为之前,猜测用户意图。
- 内容获取:可以通过中文前缀、拼音全拼、拼音首字母简拼查询以及汉字加拼音、分词前缀、中文同音别字等查询获取。
- 动态推荐:搜索框输入内容发生变化时,下拉列表中需展示最新输入内容的联想词。
如下图:当我们输入“xia”、“xiaji”,如图从query候选集中选择topN进行展示。query候选集的生成策略与用户热搜记录、历史记录等相关,通过分析用户的海量行为数据,结合人工运营的干预,提高用户的搜索效率,更快帮助用户获得想要的内容。


2.4.2 搜索推荐
电商产品的搜索功能,在商品推荐这方面下了很大的功夫。在下单的每个环节都可以看到推荐运营的模块,搜索框及搜索页面中的搜索发现、热搜、购物车中的满折、满减促销、以及处处可见的商品推荐等。
搜索功能相关的推荐包括搜索发现、热搜精选、搜索框关键词,多数产品会通过智能推荐和人工干预结合的方式,完善搜索模块的内容推荐。
通过人工干预配置搜搜关键词,把搜索框当成的产品的广告资源位管理,增加平台广告的曝光,是一种主动的推荐方式;使用数据分析,个性化展示,可以根据用户特征、兴趣爱好,实时更新改,可以称呈现给用户更多相关内容,相比较而言,为被动的推荐方式。
2.4.3 相关搜索词
相关搜索词区别于搜索前的引导,是用户点击搜索之后,猜测用户想要搜索什么,相比较来说,相关搜索更类似于推荐系统。在网页查询中经常可以见到相关搜索的推荐,当通过某个关键词无法精准获得内容时,可用相关搜索推荐补充和扩展。如下图为在谷歌中搜索“百度”的相关搜索信息示例。
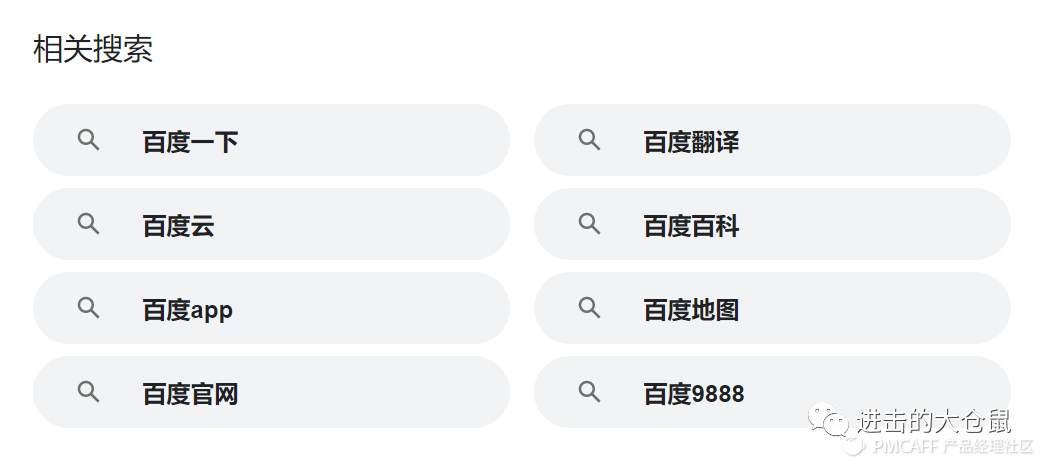
相关搜索从深度、广度两个方面去帮助用户找到所需的内容,可以更加精确地找到商品,以及扩展商品范围,找到更多的商品。从深度出发会应用到相似于搜索排序相关的算法模型,从广度出发,即使用query扩展,从而延伸出更宽范围的、贴合用户意图的词汇。
三、前台页面
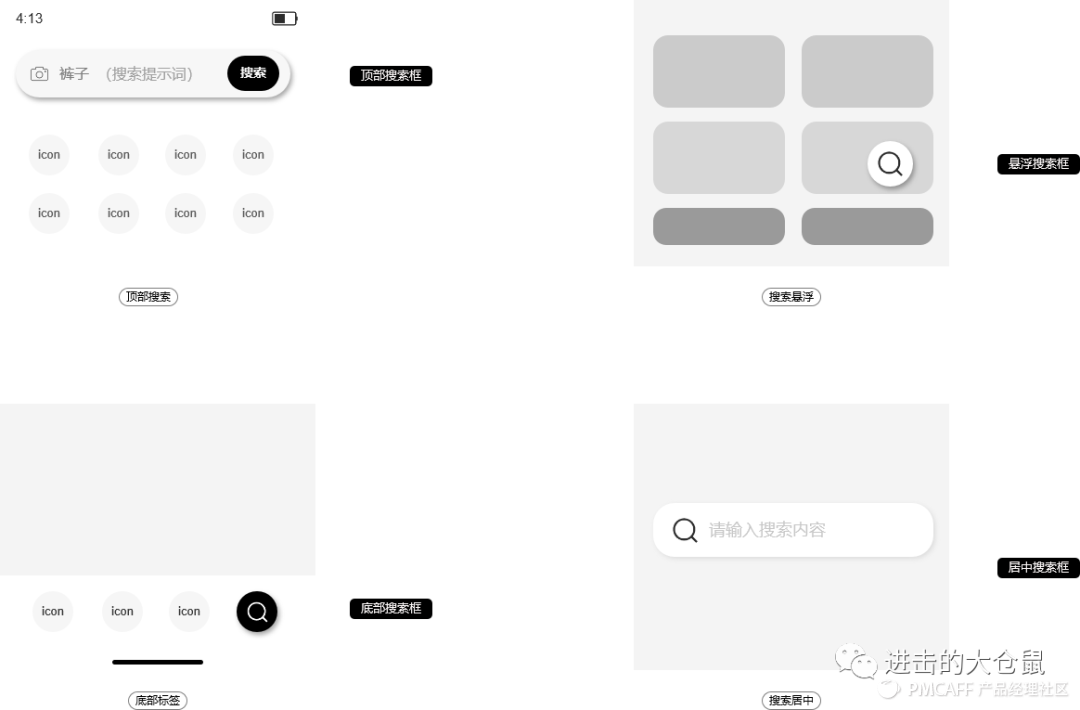
1. 搜索入口类型
我们所见的页面搜索入口有以下几种类型,最为常见的顶部搜索框、悬浮搜索入口、底部tab搜索入口、居中搜索框。
2. 搜索页面-输入搜索词
输入搜索词时,搜索页面展示模块有搜索提示词、平台热门搜索词、用户历史搜索记录、输入文本后的下拉框联想词等。
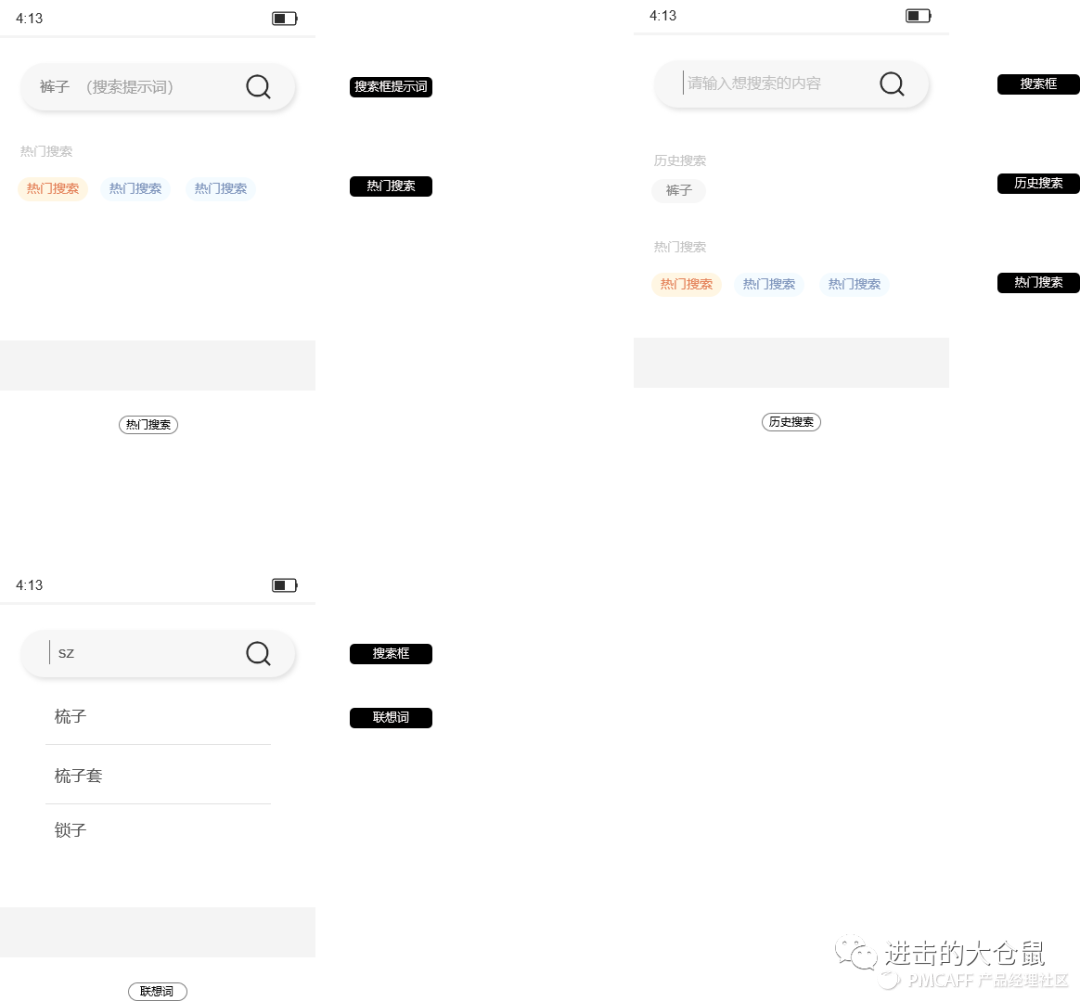
3. 搜索结果页面
点击搜索按钮后,页面返回搜索结果,可在页面设置其他模块包括关键词推荐、搜索过滤tab栏等。

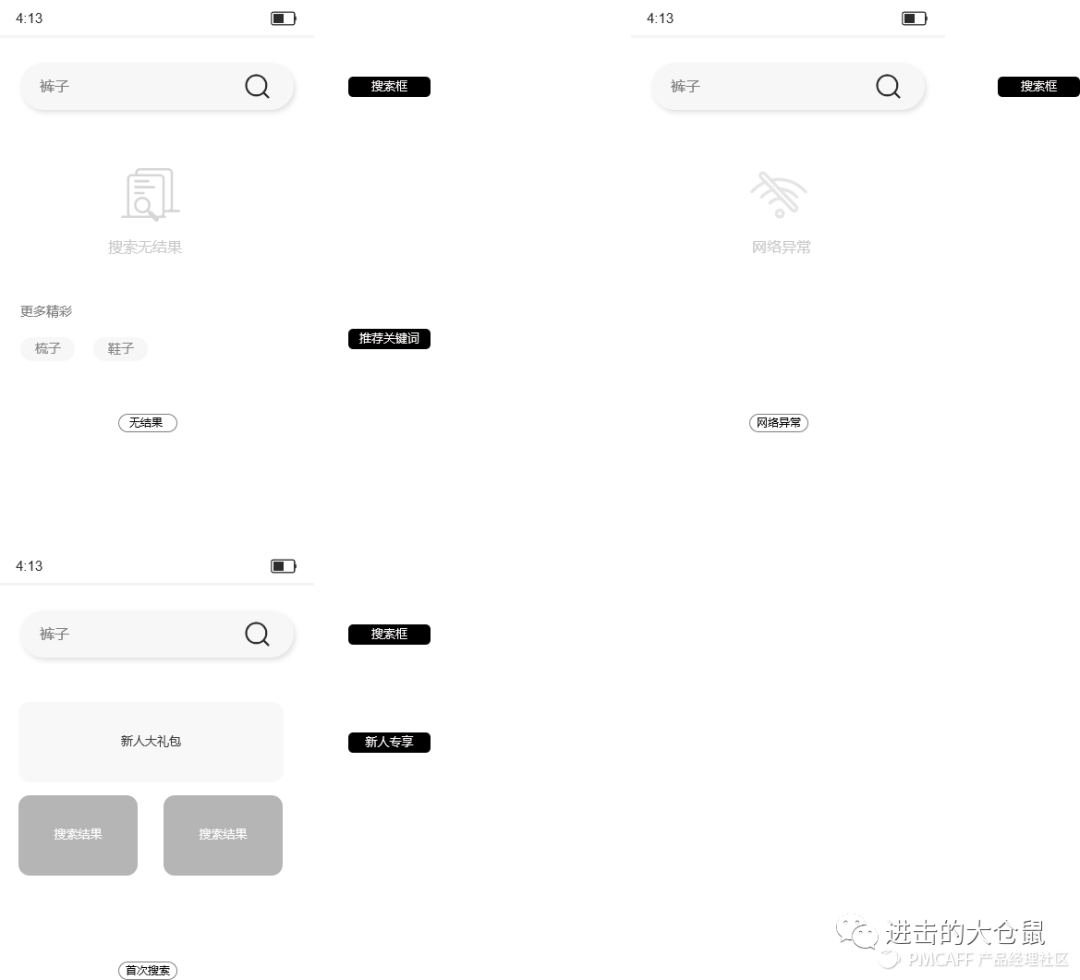
4. 特殊搜索情景
页面特殊搜索情景包括搜索异常、标签用户搜索等,如搜索无结果、网络异常、新用户搜索、会员用户搜索等。
四、后台页面
1. 搜索关键词管理
管理热门关键词、口令关键词、搜索提示词三种类型关键词。热门关键词、搜索提示词可通过系统算法推荐,三种类型的关键词接口由运营人员维护、查看。

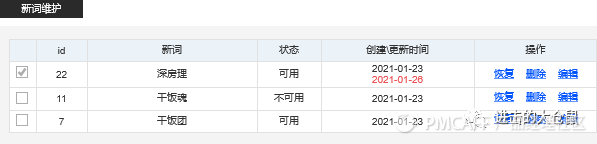
2. 搜索关键词维护
后台需要运营的搜索关键词复杂繁多,包括有错词维护、停用词维护、联想词维护、新词维护等。
1)错词维护

2)停用词维护

3)联想词维护

4)新词维护
五、化茧成蝶
1. 封闭与开放
一方面,互联网的开放性是搜索公司的重要生存基础;另一方面,如果各互联网企业各自建立信息群岛,不管是对于互联网企业本身还是对于用户来说,都毫无疑问利大于弊。但不管是物理世界还是网络世界,开放将是最终诉求。
“每个产品都有面对海量用户的机会”,这样的机会使得各大巨头公司修建自己的护城河,将用户圈守在自己的高墙中,减小用户面对其他产品的机会,建立起互联网时代的“信息群岛”。
不同产品一边深植于自己的专业领域,获取用户信任;一边构建自己的信息壁垒,防止用户的流失。对于用户来说,产品的信息聚合会提供更专业的内容和服务,激烈的市场竞争也催生出不断升级的使用体验。短期利好彼此,却不是长线发展的趋势。
哈佛大学教授凯·R·桑斯坦在《信息乌托邦:众人如何生产知识》中提出信息茧房的概念;意指在信息传播中,公众的信息需求不是全方位的,会将更多的注意力集中于自己的选择以及使自己感到愉悦的领域,久而久之,将自身禁锢于“茧房”之中。即背离多元性的个性化推荐,迎合了用户的偏好,但会使我们越来越沉浸于自己想看、想表达的内容,因而造成信息封闭。
信息封闭带来的消极影响,会使个体走向极端,从而对整个种族和文化产生“退化”式的影响,塔斯马尼亚岛效应我我们提供了现实发生的案例。塔斯马尼亚的岛民在封闭的环境下,逐渐封闭了自己的思维,慢慢地丢失了先进的工具、技能。在此情况下,文明开始走向退化,族群也渐渐回归原始。
信息茧房和塔斯马尼亚岛效应在某些角度讲述的是一个故事。信息茧房聚焦到“用户”特征的个人本身,认为“人的自我”是在与他人、社会的互动中实现的。
当个人兴趣成为探索外界的唯一意向,会失去精神世界的多元化,朝着定向单线发展,最终被“极化”,警示我们,海量推荐信息冲击下的我们,容易走向极端与封闭;而塔斯马尼亚岛效应从种族、文明的角度,讲述了社会交流被封闭后,传承遗失,文明退化的真相,警醒我们,自我封闭的带来的严重后果。
当然, 很少部分的人会将自己置于自我封茧的境地,我们所熟知的文明也不会发生突然的断裂和极端的退化。
在信息洪流的今天,我们也不是全然被动地接受。正如那些年读过的思修所言,我们是能动的个体,随着科技的发展,自身也在主动地去适应时代的改变。
2. 化茧成蝶
信息变得廉价时,注意力就变得昂贵了。
各种信息我们似乎即刻可触及,我们仿佛处于全能全知的境地。这种富足的窘境,无疑再次提醒了我们,信息不是知识,知识不是智慧。
任何答案都触手可得的今天,我们似乎越发无法确认,到底需要什么——每天从清晨到夜晚归家,忙碌的穿梭于不同软件提供的资讯中,工作、购物、娱乐...碎片化的消费内容,将我们的时间分散,同时分散的还有我们的注意力;也常常感慨于 “从前车马慢,一生爱一人”,也曾惊叹于巨匠对文明的贡献。
信息的发展让大众可以平等、自由地获取到信息,却也剥夺了先贤般的定力。
时代的车轮滚滚向前,无论哪个时期,如何辨识且读懂信息,似乎没有其他便捷的方式。至始至终“化茧为蝶” 的关键还在于我们自身。
保持开放的心态,切勿落入自缚的境地;在信息中汲取知识,在知识中获得智慧。
人生不易,珍惜拥有,感谢经历。
“Let's save the future!”