大四老狗一枚,今年我又带队参加22年的数学建模国赛了。前年和去年打了10余场比赛,国赛和美赛做的都是A题。去年拿了21国赛国二,今年拿了美赛的F。希望今年也能拿个国奖吧。
关于选题,我推荐大家选A题冲奖,获奖机会大,而且推荐国奖不容易被刷。去年我们赛区A题推荐国奖没有一个被刷,B题刷了将近25%国奖,C题刷了15%以上国奖。很多人觉得A题难,其实A题只是看起来难,其实也有很多套路。下面我就来分享一下我的A题建模经验,码字不易。
文章较长,建议先看目录,点击目录条目可以快速跳转。这篇文章介绍了国赛中优化问题的建模求解套路;常微分方程;偏微分方程;多变量、多约束问题求解的详细方法,并提供了部分代码。最后详细讲解了摘要的写作方法(重要!!!),以及一些小技巧。
本文提到的代码和文件已收录到本人收集的资料库中,下载见主页置顶文章。
国赛违纪行为
首先说一下到时候各路人马提供的各种免费和付费思路,曾经我作为一个小白的时候,我也去买过这种思路,下面说一下它们的套路。那些人提供的思路,
要么是从一些文章里面直接抄过来的,曲线图等等直接截的一些硕博论文的图片,让小白们信以为真;
要么是提供万金油式的代码,从csdn或者github抄抄差不多的代码,拿不是针对具体问题的代码忽悠小白,再配一些好看的图片,让人觉得很牛逼;
要么是废话连篇,我看过某人的思路讲解视频,10句话有9句是空话,说你要这样,然后这样巴拉巴拉说了一堆扯淡的话,问题是这种思路是个人都会,真的是水平不知道低到哪里去了;
要么就提供万金油答案,每次比赛都首先来一个热力图,动不动就神经网络机器学习,给的答案也是错误连篇。这些人一般也只会做数据题,因为A题这种难题他们不会,水平卡在这里了
还有那些声称包国奖的、只卖一份的,你想想可能吗?
下面说一下违纪行为:
违纪行为:论文抄袭、买卖论文、非独立完成
竞赛论文查重检查与违纪论文处理:
以本人所在湖北赛区为例,其他赛区差不多要求:查重率>25%, 不推荐国奖;查重率>30%, 剥夺获奖资格
违纪论文处理:公布学校、参赛队员信息。严重的,剥夺学校一年的参赛资格
论文的重述:切忌长篇幅引用著作内容或他人论文内容
网上查找的或书中程序:正文附录中需要有完整的程序代码,不是自编的程序注明出处
全国通报严重违纪的学校和参赛队(论文相似度>60%,80%)

一些典型的违纪问题
- 抄袭、雷同
- 网购、网上交流
- 加入与数模竞赛相关的贴吧、微信群或QQ群(校外),特别是付费的数模交流群
竞赛期间不得加入或者留在讨论与赛题有关问题的群!无论加入的时间以及本人是否发言!
典型违纪案例:
- 队外成员参与(与室友讨论等被揭发)
- 竞赛期间,教师在校内群帮助理解赛题
- 竞赛期间,教师在校内群发布参考文献
- 竞赛期间,教师要求同学把论文发给教师
- 竞赛期间,“4人”一起交流
- 竞赛期间,教师与同学单独交流
严重违纪(1):
雷同(自建库相似度较高;有些为网购)抄袭或者剽窃(不引用或者引用不规范)过度引用(大段文字或者文献雷同)。公开通报相似度较高的论文,逐步加大通报力度。
•严重违纪(2):竞赛期间与他人讨论,教师参与
竞赛开始后,参赛队员不得以任何方式(包括电话,电子邮件,网上咨询等)与队外的任何人,包括指导老师,研究和讨论任何与赛题相关的问题。”
竞赛期间各参赛队必须独立完成赛题解答,禁止参赛队员以任何方式与队外的任何人(包括指导教师)交流及讨论与赛题有关的问题,参赛队员无论主动参与讨论还是被动接收讨论信息均视为严重违反竞赛纪律
赛期间参赛队员不得加入或留在涉及赛题讨论的互联网交流平台(含“贴吧”、QQ群和微信群等)
国赛各题目分析
A题分析
A题大方向:微分方程、机理分析、动力系统、参数拟合、数据矫正、非线性优化、误差分析、精度分析
国赛前主要看这几个方面的论文
- 热问题(热传递,热扩散,热对流)
- 航海物理问题,流体问题
- 环境方面问题(污染扩散问题)
- 航空航天问题(卫星运行,航天器着陆,导弹问题)
- 几何问题
比赛前可以多看看matlab官方网站里面提供的案例,文档和代码写得很详细,可以作为学习和参考
B题分析
根据往年经验,国赛B题题型变幻莫测,介于A题和C题之间。可能是微分方程题目,主要考察机理建模能力比如2019B 题“同心协力”策略研究;可能是图论题目,主要考察算法编程能力,比如2020B 题穿越沙漠;也可能是数据分析题,比如2021B 题乙醇偶合制备C4烯烃,当然这道题不是机器学习,而是传统的多元统计分析。因此,做B题需要对以上题型有全面的了解。
C题分析
国赛C题不同于美赛,美赛数据题有时候是纯数据题,而国赛不是,国赛C题一定有机理分析和规划问题在里面,因此不可强行套用机器学习和神经网络算法,一定得结合问题,不然就变成算法比赛而不是建模比赛了,第一步就把你pass。
比如2019年国赛C题: 机场的出租车问题,这就是一道典型的机理分析题目,你得首先理清出租车的停车、费用等的逻辑,也就是分析出租车相关机理,再去收集相关数据。再比如2020和2021国赛C题,这两题都是评价+规划的结合。对于评价问题,千万不要做评价算法公式的堆砌,比如topsis评价方法,很多人直接把这个topsis方法公式一堆,烂大街了已经。(遗传算法也是)。不是说不能用,一定要注意结合问题。
国赛做题套路
不管是A题B题C题,优化问题是国赛和美赛中最重要也是最常见的问题,基本上大部分模型都可以建成优化模型,所以,优化问题需要重点关注
不管是国赛还是美赛,优化模型都可以分成外部的优化模型和内部的具体模型
第一问建模方法
分析过去5年的国赛A题,第一问几乎都是参数优化问题,一般会给附件数据,我们把它抽象出来,也就是需要先建立一个模型,通过附件数据拟合模型中的未定参数。
首先,什么是参数优化?举个例子,对于模型y=f(x)=ax+b,附件中会给定x和y的值。当然,模型y=ax+b不会告诉你,这是自己建立的模型。建立了模型之后,通过数据去拟合,求解参数a和b
怎么求a和b,这就是关于算法的问题。对于y=ax+b这样简单的模型,拟合本质上是优化,我们可以使用各种成熟的优化算法,如:单步长(变步长)搜索法、二分搜索法、黄金分割搜索法、最小二乘法、遗传粒子群模拟退火算法
以下是2021国赛训练做的2020国赛A题炉温曲线的第一问的参数拟合求解

第二、三问建模方法
第二、三问是正问题和反问题的优化求解。通过建立的模型和标定好的参数,将模型中的某些变量作为自变量,再将这些量作为若干个优化目标函数的自变量,求解目标函数对应的解。
这里的目标函数可能是以下几种情况,函数关系式记为F:
- 模型中的参数或者参数的函数关系式,比如a,b,或者F(a;b)
- 模型的自变量或者自变量的函数关系式,比如x,或者F(x)
- 模型的因变量或者因变量的函数关系式,比如y,或者F(y)
- 关于模型中的若干个变量的函数关系式,比如F(a;b;x;y)
注意上面的a,b,x,y可以推广为向量或者矩阵形式,a=[a1,a2,a3...an];b=[b1,b2,b3...bn];x=[x11,x12,x13,...x1n;x21,x22,x23,...x2n;...;xn1,xn2,xn3...,xnn]
同时,参数a,b也可以分为恒定参数和可变参数。例如2020A题中,各温区的温度([T1-5, T6, T7, T8-9])和过炉速度(v)是可变参数,热传导因子( )是恒定参数,(
)已经由第一问拟合得到。
上面第1、2种情况是反问题,第3种情况是正问题,第4种情况是正反问题的结合
以y=ax+b为例,第一问已经建立好了y=ax+b这个模型,并且根据附件数据求解了最优的参数a和b的值。现在,整个模型已经确定。第二问的目标函数的自变量为y;x;a;b,目标函数的因变量(记为y2),y2=f(y,x,a,b),求解使得y2最优的(y、x、a,b)的其中一个或者某几个。
以2020A题为例,问题二给出了各温区温度的设定值,其中小温区1-5 为182ºC,小温区6 为203ºC,小温区7 为237ºC、小温区89为254ºC,需要求解在满足制程界限的前提下,允许的最大传送带过炉速度。对应到上面的y=ax+b的模型,目标函数量是传送带过炉速度v,其中v是模型中的参数,即符合第一种情况
问题3需要求解[T1-5, T6, T7, T8-9, v],使得超过217ºC 到峰值温度所覆盖的面积最小。这里的优化自变量是[T1-5, T6, T7, T8-9, v],这些都是模型中的参数,目标函数面积S是温度曲线的函数,温度曲线可以由参数[T1-5, T6, T7, T8-9, v]和自变量(时间t)等通过模型推导得到。因此这一问的目标函数是第四种情况,即F(a;b;x;y)
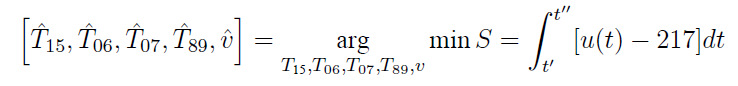
问题4的是多目标函数,面积S最小化和对称性指标D最小化。同第三问,目标函数是第四种情况
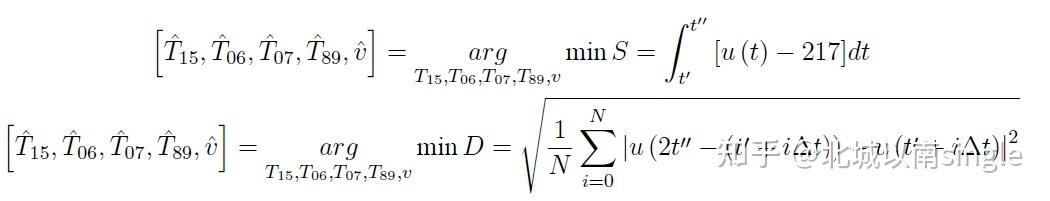
如何判别是否是优化问题
- 凡事关于最小最大相关或者尽量相关的词汇,一般都是优化问题。收益最大,风险最小,尽量对称,尽量小,尽量大等等
- 另外还有一种最后趋于稳定的问题,一般也是优化问题,例如2019A高压油管压力控制,油压最后稳定在100,优化目标是最后一秒的油压曲线与100的偏差最小
优化问题的组成部分
注意优化问题特别是微分方程问题,一般由5个主要部分构成,它们分别是:
- 优化变量(自变量)
- 优化目标(单目标、多目标)(因变量)
- 控制方程(微分方程模型主体及其他附属方程)
- 边界条件
- 初始条件
在论文写作时,我们需要做的是把优化目标、控制方程、约束条件等用数学语言表达出来。需要注意:应该明确写出上面5个部分,如果某些部分没有,应该至少写出优化目标和控制方程
以我们2021国赛暑期训练为例,我们做的是2020国赛A题炉温曲线,各位可以自行阅读题目,此处不赘述题目
模型的建立部分
在写作时,明确写出以xx为优化变量、以xx为控制方程(约束条件)、以xx为优化目标的单目标(多目标)优化模型


上面写完了模型的引入,下面开始写模型的公式:
其中优化变量和优化目标可以写一起,举例如下。其中排第一位的是优化变量的估计,表示求解出来的值只是全局最优的估计;argmin(argmax)下标优化变量,表示使得后面的优化目标方程最小时的优化变量的精确值;最后是优化目标方程
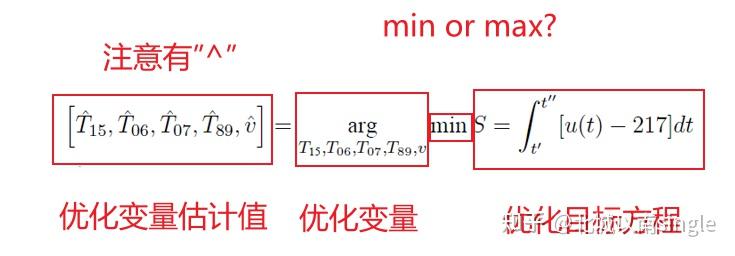
上面的是单目标的写法,对于多目标优化,写法也一样,如下:

下面开始写控制方程以及约束,注意有下面两点。
第一点、使用大括号把控制方程和约束条件、边界条件写一起。
第二点、后面需要有变量符号的解释(其中,a为:,b为:...)
为什么要这么写?原因是这样评委一看就知道所有的东西,一目了然!

对应的LaTeX代码如下(这篇论文的完整latex源码和对应的matlab代码全部工程下载见文章开头):
\begin{equation}\label{p3}
\begin{gathered}
\left[\hat{T}_{15}, \hat{T}_{06}, \hat{T}_{07}, \hat{T}_{89}, \hat{v}\right]=\underset{T_{\mathrm{15}}, T_{06}, T_{0 7}, T_{89}, v} \arg \min S = \int_{t^{\prime}}^{t^{\prime \prime}}[u(t)-217] d t
\\
\begin{cases}
t^{\prime}=\min\text{\{}t\mid u\left( t \right) \ge \text{217\}}\\
t^{\prime \prime}=\underset{t}{arg}\,\,\max\text{ }u\left( t \right)\\
\text{制程界限}\begin{cases}
\max \left( \left| \dot{u}\left( t \right) \right| \right) \leqslant 3\\
60\leqslant \left. t \right|\left( 150\leqslant u\left( t \right) \leqslant \text{190\&}\dot{u}\left( t \right) >0 \right) \leqslant 120\\
40\leqslant \left. t \right|\left( 217\leqslant u\left( t \right) \right) \leqslant 90\\
240\leqslant \max \left( u\left( t \right) \right) \leqslant 250\\
65<v<100\\
\end{cases}\\
\text{控制方程}\left\{ \begin{array}{l}
u\left( t \right) =u\left( \frac{d}{2},t \right)\\
\frac{\partial u\left( x,t \right)}{\partial t}=\alpha \frac{\partial ^2u\left( x,t \right)}{\partial x^2}\\
\left. \frac{\partial u}{\partial x} \right|_{x=d}=\beta \left( u_s\left( t \right) -u\left( d,t \right) \right)\\
-\left. \frac{\partial u}{\partial x} \right|_{x=0}=-\beta \left( u_s\left( t \right) -u\left( \text{0,}t \right) \right)\\
\end{array} \right.\\
\text{空气温度:}u_s\left( t \right) =U_s=U_s\left( vt \right)\\
\text{速度界限:}65cm/\min \leqslant v\leqslant 100cm/\min\\
\text{温区温度界限}\begin{cases}
\left| T_{15}-175 \right|\leqslant 10\\
\left| T_{06}-195 \right|\leqslant 10\\
\left| T_{07}-235 \right|\leqslant 10\\
\left| T_{89}-255 \right|\leqslant 10\\
T_{1011}=25\\
\end{cases}\\
\end{cases}\\
\end{gathered}
\end{equation}
当然,你也可以将上面5个部分分开写,我2022美赛A题就是这样写的,如下,也就是每个部分写个小标题并加粗:
第一、决策变量(优化变量))

第二、目标方程(优化目标)

第三、控制方程

第四、约束条件

第五、初始条件

不管是国赛还是美赛,优化模型都可以分成外部的优化模型和内部的具体模型
下面将外部模型的求解和内部模型的求解分开讲述,首先是外部优化模型的求解:
外部优化模型的求解
上面建立完了模型,我们就开始写模型的求解,这部分就是算法了
对于一个优化问题,如何选择算法?当然算法不是乱选的,你得体现你的思考与创新
比如对于一个参数搜索问题,变步长搜索就比单步长搜索要好,为什么?因为变步长搜索在趋于最优解的时候缩小步长,能够减少运算次数,这就是它的优点。
再进一步,二分搜索法比变步长搜索法更好。你用二分,别人用穷举搜索,你的算法就比别人的更优秀。
注意,不是越复杂的算法就越好,而是使用简单的算法在最短的时间内解决问题才是最优的算法。
下面是一些常见优化问题的求解算法
参数拟合或者参数标定问题
利用最小二乘法,优化目标是误差最小,拟合函数一般是复杂的常微分方程(2019A)或者偏微分方程(2020A,2018A),例如2020A题需要拟合带10个未知参数的偏微分方程,这时候就需要用遗传算法等智能算法了
求复杂函数的最小\最大值\零点
- 求解最大最小值一般,先用变范围搜索的方法大致搜索一遍,然后:
- 对于单调函数,用二分法
- 对太复杂的,一般用智能算法
内部具体模型的求解
- 求解常微分方程(组)的方法有欧拉法,改进欧拉法,龙格库塔法,算法最好自己写,尽量不调库。例子:2019A高温油管压力控制
- 求解偏微分方程(组)一般是有限差分法,一般需要自己写算法。例子:2018A高温服装设计、2020A炉温曲线
- 多变量、多约束优化问题求解,使用罚函数法,例子:2021A题FAST反射面节点调节
常微分方程的求解
为了编程时更好的与我们外部优化模型的迭代算法匹配,常微分方程我们一般使用手写的改进欧拉法代码迭代求解。
利用欧拉法求解微分方程 ,将时间等分,区间长度是h,
,则
,精度为O(h)。
利用改进欧拉法求解微分方程 ,将时间等分,区间长度是h,
,则
,精度为O(h2)。
利用改进欧拉法求解混合微分方程 ,将时间等分,区间长度是h,
。则y1的迭代公式为
,y2的迭代公式为
微分方程组求解要点:
- 因变量个数与方程个数相同
- 尽量使用最基础的理论(牛顿第二定理等)
- 只采用一阶微分方程组的形式
- 尽量采用向量方式处理
- 尽量做到可进行数组运算(并行计算, 存贮空间换时间)
- 如无法理论求解,不做化简(只做计算机数值计算)
- 保留混合微分方程的形式
1.建立混合微分方程的函数代码,(对复杂的微分方程组往往比较困难)
2.利用库函数求解(精度满足条件),或用欧拉、改进欧拉自编程求解(时间换精度)
在无法理论求解的情况下,高阶理论往往只有理论上的优势,对数值求解帮助不大,基础理论形式更简洁明了
以2019年A题高压油管控制为例,第一问建立的模型如下:
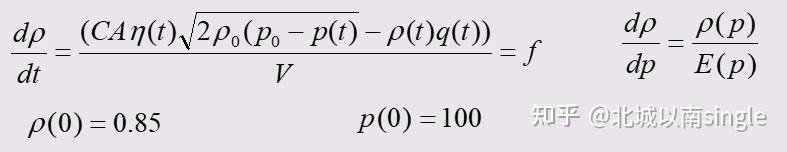
取定参数a, T,将时间等分,区间长度是h,初始化: ,根据改进欧拉法,由
计算
。依次循环计算下去,可得所有时间节点的压力及密度值
编程的代码如下(篇幅有限,完整代码下载见文章开头):
function [p,t]=f(time,T,p1) %time 总时长, T 开阀时间
global p0 A C V
h=0.001; n=floor(time*1000/h)+1; a=0;
t=(0:n-1)*h; %时间列
p=zeros(n,1); %对应的压强
midu=zeros(n,1); %对应的密度
rho0=dens(p0); p(1)=p1; midu(1)=dens(p1);
tmp1=h*C*A*eta(t,a,T)*sqrt(2*rho0)/V;
tmp2=h*q(t)/V;
%改进欧拉法迭代求解
for i=1:n-1
tmp=tmp1(i)*sqrt(p0-p(i))-midu(i)*tmp2(i);
midu(i+1)=midu(i)+tmp;
p(i+1)=p(i)+tmp*sc(p(i))/midu(i);
end
end
第二问建立的模型如下,求解方法同理:

偏微分方程的求解
偏微分方程的求解使用有限差分法,有前向差分、后项差分、CN隐格式差分。使用差分法的时候,需要考虑稳定性和收敛性的问题。Crank-Nicolson 隐格式收敛性与稳定性都优于古典显格式和古典隐格式。
同时,需要明确是第几类边界条件!!选错边界条件类型,直接全盘出错!!!
以热方程的求解为例(2018A题高温服装设计):
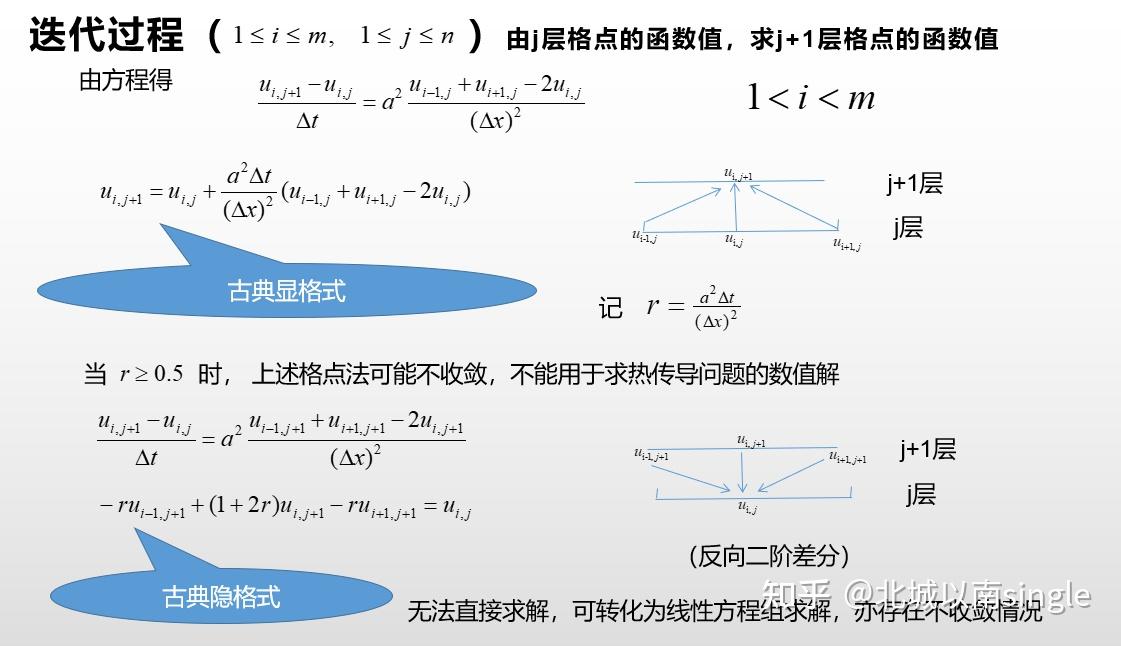



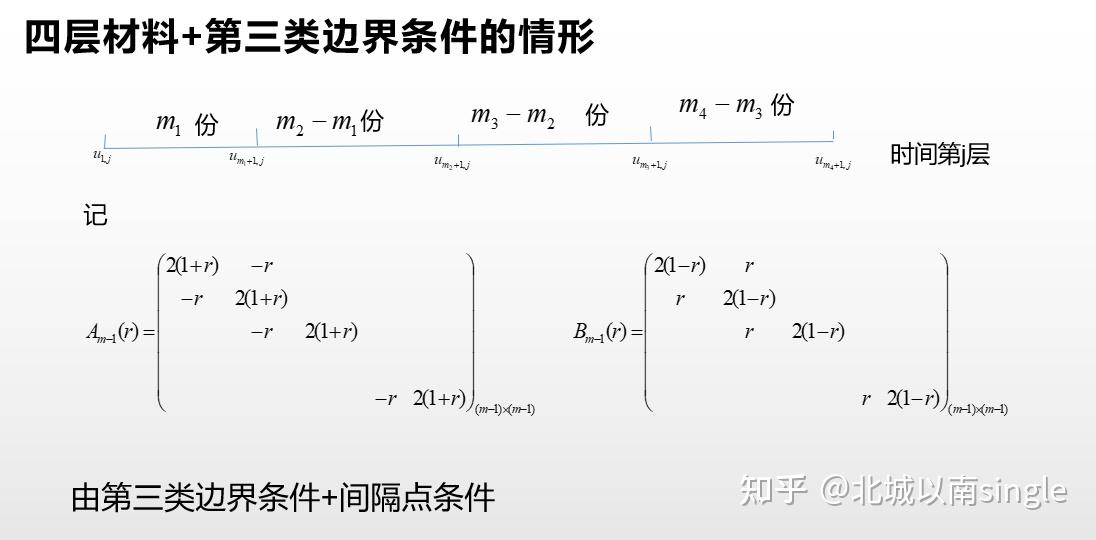

建立好模型之后,编程求解也不是很困难,核心就是3个矩阵:

编程的代码如下(篇幅有限,完整代码下载见文章开头):
function u=heatequation(u0,T,l2,l4)
k=[0.082 0.37 0.045 0.028];c=[1377 2100 1726 1005];density=[300 862 74.2 1.18];
l=[6e-4 l2*1e-3 3.6e-3 l4*1e-3]; u1=37; h0=122.3928; h1=8.37;
x=1e-5;
r=k./(c.*density.*x*x);
n=int16(l/x);m=sum(n)+1;
u=zeros(m,T+1);
u(:,1)=37;
%核心矩阵A、B、C
A=diag([k(1)+h0*x,2*ones(1,n(1)-1)*(1+r(1)),k(1)+k(2),2*ones(1,n(2)-1)*(1+r(2)),k(2)+k(3),2*ones(1,n(3)-1)*(1+r(3)),k(3)+k(4),2*ones(1,n(4)-1)*(1+r(4)),k(4)+h1*x]);
A=A+diag([-k(1),-r(1)*ones(1,n(1)-1),-k(2),-r(2)*ones(1,n(2)-1),-k(3),-r(3)*ones(1,n(3)-1),-k(4),-r(4)*ones(1,n(4)-1)],1);
A=A+diag([-r(1)*ones(1,n(1)-1),-k(1),-r(2)*ones(1,n(2)-1),-k(2),-r(3)*ones(1,n(3)-1),-k(3),-r(4)*ones(1,n(4)-1),-k(4)],-1);
B=diag([0,2*ones(1,n(1)-1)*(1-r(1)),0,2*ones(1,n(2)-1)*(1-r(2)),0,2*ones(1,n(3)-1)*(1-r(3)),0,2*ones(1,n(4)-1)*(1-r(4)),0]);
B=B+diag([0,r(1)*ones(1,n(1)-1),0,r(2)*ones(1,n(2)-1),0,r(3)*ones(1,n(3)-1),0,r(4)*ones(1,n(4)-1)],1);
B=B+diag([r(1)*ones(1,n(1)-1),0,r(2)*ones(1,n(2)-1),0,r(3)*ones(1,n(3)-1),0,r(4)*ones(1,n(4)-1),0],-1);
C=A\B;
c=zeros(m,1); c(1)=h0*u0*x; c(m)=h1*u1*x;
c=A\c;
for j=1:T
u(:,j+1)=C*u(:,j)+c;
end
u=u(m,:)';
end
多变量、多约束优化问题求解 (罚函数法)
对于多变量、多约束优化问题: ,转化为新无约束优化问题,
。
求解步骤如下:
- 令x1=x0,计算
,如果
,跳到3,否则2
- 找
,设最小点为
,令k=k+1,
- 计算等式、不等式平方和及|x0-x1|, 若最大值<esp, 结束,否则 1
其中esp为误差精度; 为初始点,初始取k=1
要点:
- 多变量、无约束优化问题有很多算法,选合适的
- 变量太多,粒子群、遗传、蚁群等算法应该不适应
- 要注意用向量并行计算,避免循环语句
以2021A题FAST节点调节为例,建立以下模型:

部分求解代码如下(篇幅有限,完整代码下载见文章开头)
while tol>eps
x1=x0;
while 1
y0=dfun(x0)+c*(dineq(x0)+deqf(x0));
tmp=norm(y0);
if tmp<eps
break;
end
h=-y0/tmp;
fhandle=@(t) fun(x0+t*h)+c*(ineq(x0+t*h)+eqf(x0+t*h));
range=max(tmp,range);
[t,g0]=funm(fhandle,range);
range=t*50;
g1=fun(x0);
g2=ineq(x0);
g3=eqf(x0);
x0=x0+t*h;
end
if c>1e8
break;
else
c=r*c;
end
tol=max([err1,err2,err3]);
end
function y=dineq(x) %x(n,4) 主索节点坐标及促动器伸缩量
%y 不等式约束在x的梯度值
global side_ind_square index
r=0.0007; % 边长最大容许伸缩比
E=x(:,1:3); % 主索节点坐标
s=x(:,4); %促动器伸长量
y=zeros(size(x));
tmp=E(side_ind_square(:,1),:)-E(side_ind_square(:,2),:);
tmp1=sum(tmp.*tmp,2);
tmp2=tmp1-side_ind_square(:,3)*(1+r)^2;
tmp3=side_ind_square(:,3)*(1-r)^2-tmp1;
tmp2=max(0,tmp2);
tmp3=max(0,tmp3);
tmp4=4*(tmp2-tmp3).*tmp;
tmp5=max(0,s.^2-0.36);
y(:,1:3)=index*tmp4;
y(:,4)=4*s.*tmp5;
end
function g=ineq(x) %x(n,4) 主索节点坐标及促动器伸缩量
%g 不等式约束在x值
global side_ind_square err1 err3
r=0.0007; % 边长最大容许伸缩比
E=x(:,1:3); % 主索节点坐标
s=x(:,4); %促动器伸长量
tmp=E(side_ind_square(:,1),:)-E(side_ind_square(:,2),:);
tmp1=sum(tmp.*tmp,2);
tmp2=tmp1-side_ind_square(:,3)*(1+r)^2;
tmp3=side_ind_square(:,3)*(1-r)^2-tmp1;
tmp2=max(0,tmp2);
tmp3=max(0,tmp3);
tmp4=max(0,s.^2-0.36);
g=sum(tmp2.^2)+sum(tmp3.^2)+sum(tmp4.^2);
err3=max(tmp4/0.72);
err1=max(max(tmp2,tmp3)./side_ind_square(:,3));
end
function g=eqf(x) %x(n,4) 主索节点坐标及促动器伸缩量
%g 等式约束在x值
global L l P e err2
E=x(:,1:3); % 主索节点坐标
s=x(:,4); %促动器伸长量
tmp=P-E+e(:,1:3).*(L+s);
tmp1=sum(tmp.*tmp,2)-l;
t1=tmp1.^2;
g=sum(t1);
err2=max(abs(tmp1)./l)/2;
end
function y=deqf(x) %x(n,4) 主索节点坐标及促动器伸缩量
%y 等式约束在x的梯度值
global L l P e
E=x(:,1:3); % 主索节点坐标
s=x(:,4); %促动器伸长量
y=zeros(size(x));
tmp=P-E+e(:,1:3).*(L+s);
tmp1=sum(tmp.*tmp,2)-l;
tmp2=sum((P-E).*e,2);
y(:,1:3)=4*tmp1.*(E-P-(L+s).*e);
y(:,4)=4*tmp1.*(L+s+tmp2);
end
function g=fun(x) %x(n,4) 主索节点坐标及促动器伸缩量
%g 优化函数在x值
global k R p
f=0.466*R;
s=-0.3361;
F=f-s; %焦距
E=x(k,1:3);
tmp=sum(E.^2,2);
tmp1=E(:,1:3)*p';
tmp2=tmp1.^2;
tmp3=tmp-tmp2-4*F*(tmp1-s+R);
g=tmp3'*tmp3;
end
function y=dfun(x) %x(n,4) 主索节点坐标及促动器伸缩量
%y 优化函数在x的梯度值
global k R p
f=0.466*R;
s=-0.3361;
F=f-s; %焦距
y=zeros(size(x));
E=x(k,1:3);
tmp=sum(E.^2,2);
tmp1=E(:,1:3)*p';
tmp2=tmp1.^2;
tmp3=tmp-tmp2-4*F*(tmp1-s+R);
y(k,1:3)=4*tmp3.*(E-tmp1*p-2*F*ones(length(k),1)*p);
end
论文写作方法
论文标题
欣赏历年国一作品标题如下:
2020年国赛优秀论文的标题
- l 基于一维热传导方程的回焊炉炉温模型
- l 基于一维热传导方程的炉温曲线机理模型研究
- l 基于动态规划、统计分析、静态博弈的穿越沙漠游戏策略设计
- l “穿越沙漠”游戏下玩家的最优策略模型
- l 基于梯度下降的决策树算法与非线性规划的信贷风险评估与信贷策略模型
- l 针对中小微企业最优信贷决策研究
- l 接触式轮廓仪的自动标注数学模型研究
- l 基于接触式轮廓仪测量数据的工件形状自动标注方法
- l 校园供水系统智能管理
2019年国赛优秀论文的标题
- l 基于数值模拟的高压油管压力控制模型
- l 同心鼓“同心协力”策略探究
- l 基于系统模拟的机场出租车决策与安排模型
- l 空气质量数据的校准
- l 基于数据挖掘对“薄利多销”进行分析
参考往年优秀论文,论文的标题一般采用下面两种形式:
- 基于所使用的主要模型或者方法作为标题(推荐)
- 直接使用赛题所给的题目或者要研究的问题作为标题
Ø 基于利润最大化的奥运商业网点分布微观经济模型(04)
Ø 基于回归分析的长江水质预测与控制(05)
Ø 基于Leslie模型的中国人口预测及模特卡罗仿真(07)
Ø 基于蒙特卡洛模拟的眼科病床安排排队模型(09)
Ø 基于0-1规划的交巡警平台设置与调度模型(11)
Ø 基于自适应模拟退火遗传算法的月球软着陆轨道优化(14)
Ø 基于聚类分析的双目标优化定价模型(17)
Ø 基于非稳态导热的高温作业专用服装设计(18)
Ø 基于RFMS 指标的大型百货商场会员画像数据挖掘(18)
对论文题目的要求是:简短精炼、高度概括、准确得体、恰如其分。既要准确表达论文内容,恰当反映所研究的范围和深度;又要尽可能概括、精炼,力求题目的字数少。论文题目的字数一般不要超过20个字。
不过,当希望题目字数少与恰当反映论文内容两者发生矛盾时,宁可多用几个字也要力求表达准确。
摘要(超级重要!!!)
什么是摘要:摘要是对论文内容的一份简短陈述,不能超过一页。
摘要的作用:使读者或评委在不阅读论文全文的情况下就能获得必要的信息。
摘要需要包含的三要素:解决了什么问题;应用了什么方法;得到了什么结果。
摘要书写的特点:摘要需充分概括论文内容,文字必须十分简练,书写时应注意突出论文的新见解、新方法和特色,陈述要客观,不能带有主观性。
摘要的重要性:摘要是数模论文写作中最重要的一部分,因为评阅老师的时间有限(每篇15分钟),拿到一篇论文后不会完整的从头读到尾,所以评阅老师往往会重点阅读摘要部分,并结合官方的评阅要点来对你的论文进行初步评定。因此,大家一定要好好打磨论文的摘要,摘要一般是其他部分都完成后再来书写,写完后需要反复阅读反复修改。

摘要的开头段
开头段:需要充分概括论文内容,一般两到三句话即可,长度控制在三至五行。第一句话可以简单交代下题目的背景(可选);第二句话交代你们所做的事情(必须);第三句话可以说下解决这个问题的实际意义(少部分有)。(重要性:第二句话> 第一句话> 第三句话)
例(19b)“同心鼓”游戏是一项团队协作能力拓展项目,队员通过拉绳使鼓抬高,达到使球在鼓面上跳动的目的。本文通过建立三维物理模型,利用数学物理方法,分析了“同心鼓”游戏中的物理过程。该问题的研究能为游戏参与者提供指导性意见,帮助参与者取得更好成绩。
摘要的中间段
中间段:需要对每个问题分别进行叙述,一般需要包含下面三要素:解决了什么问题;应用了什么方法;得到了什么结果。
(1)解决了什么问题?
有三种方式提出:
Ø 直接用一句话概括题目要我们求解的问题。(较少见到)
Ø 不单独提出我们要解决的是什么问题,因为在后面的两个要素中也会提到。(最常见到)
Ø 可以指出题目中问我们的是什么类型的问题,例如常见的有:预测类、评价类、规划优化类(极少见到)
例1 (20c) :针对问题一,主要解决两个问题:一是需要量化各企业的信贷风险,二是需要给出银行的最优信贷决策。(方式一)
例2 (20b):针对问题二,本文利用马尔可夫链,建立马尔可夫链天气预测模型,根据第一关的天气转换情况预测其余关卡的天气情况,再根据问题一的模型得出在不同天气状况下的最佳决策。(方式二)
例3 (20a):针对问题二,在大温区温度已知、制程界限给定的前提下确定元件最大过炉速度,实质上是非线性约束条件下的单目标单变量规划求解问题。(方式三)
(2)应用了什么方法?
这里写出你对于这个问题的求解思路,并说明你应用的模型。这里写作时一定要紧扣题目本身,不能脱离题目本身来描述模型。
例1 (19e) :针对问题三,根据问题一和问题二对商场每天的销售额和利润率与打折力度,利用迭代加权最小二乘法,建立了打折力度为自变量、销售额利润率为因变量的线性回归模型。
例2 (19c) :针对上车点的设置问题,需要我们合理安排上车点数量,使得机场乘车效率最高。于是,我们以乘车效率为优化目标,安全因素为约束条件,上车点数量为决策变量,建立单目标优化模型。其中,我们通过合理制定机场出租车乘车区运行规则,利用计算机模拟的方法,计算得到各方案对应的乘车效率。
例3 (18c) :针对问题二,本题选用K-均值聚类法,以消费金额和消费次数作为衡量会员购买力的特征数据,运用SPSS 软件对提取好的数据(见附录2)对会员进行聚类,K 值以公式(1)进行确定
(3)得到了什么结果?
在介绍完使用的建模方法后,一定要加上通过这个方法或者模型得到的结果。一般有下面两种情况:
(i) 需要计算出数值答案,例如物理题、规划优化类、预测类直接回答该答案即可。(如果模型中有重要参数时,我们可以做灵敏度分析;如果涉及概率统计,可以考虑加上置信区间;如果是预测类或者数值计算类,可以考虑加上误差分析)
(ii) 开放的问题,例如评价类、提建议类、设计方案策略类对于较为开放的问题,我们在摘要中只需要写出主要的结论,在下结论时一定要有明确支持的观点,不要模棱两可。如果有数值描述的结果更好,例如:采取某种建议或者方案后提高了多少、降低了多少。此外,有时候问题的完整答案很长,这时候只需要在摘要中说出最主要的一部分结果,然后加一句话来引导读者在正文或者附录中查看完整的结果。
例1 (20a) :利用模拟退火算法迭代20000次进行求解,得到的最优方案为184.2181°C(小温区1~5)、189.8133°C(小温区6)、227.5226°C(小温区7)、264.0700°C(小温区8~9),传送带过炉速度为90.0982cm/min.
例2 (20b) :使用Matlab和C++编程求解,最终得到:在最佳策略下,第一关、第二关的剩余资金分别为10470、12730元,并将相应结果填入了Result.xlsx文件;随后,我们对该模型进行了灵敏度分析。
例3(20c):最终获得基于新冠肺炎突发事件下的信贷调整政策,并将其与第二问的结果进行对比,文章发现新冠疫情的爆发导致银行的信贷策略更加倾向于高新技术产业,这可能和此类产业在疫情间的快速发展有关。
例4(16b):求解得到小区开放后,周边一级主路的通行力得分提高了为11.32%,二级主路的通行力得分提高了为12.89%,三级主路的通行力得分提高了为0.26%。调整指标之间的直接影响矩阵,发现道路通行力对各指标间相互影响关系的强弱变化比较敏感。
摘要的结尾段(可选)
结尾段:可以总结下全文,也可以介绍下你的论文的亮点,也可以对类似的问题进行适当的推广。(如果写不出来的话可以不写,我统计发现只有30%的优秀论文有最后这段)
例1 (19d):文中所建立的模型简便易行,便于推广,可利用国控点的数据对近邻自建点的数据进行校准。
例2 (18b) :本文的亮点在于:首先,利用一般化的公式对系统调度进行了较为细致的机理分析,使得模型具有普适性;其次,给出了多个调度原则相互比较,从而有利于结果更优;最后,将蒙特卡洛模拟与机器学习的思想相结合,对上述调度原则的有效性进行验证,增强了模型的说服力。
例3 (20c) :最后,本文对模型进行了优、缺点评价与模型推广,得出该模型还可以向银行面对的其他对象和生活的其它方面进行推广的结论。
例4 (20b) :综上所述,本文依据各题所给的条件较全面地分析了相关因素对玩家决策的影响,并给出了不同条件下玩家的最佳策略,实现了在终点的最大收益。经过分析验证,本文的模型具有合理性和一定的现实意义。
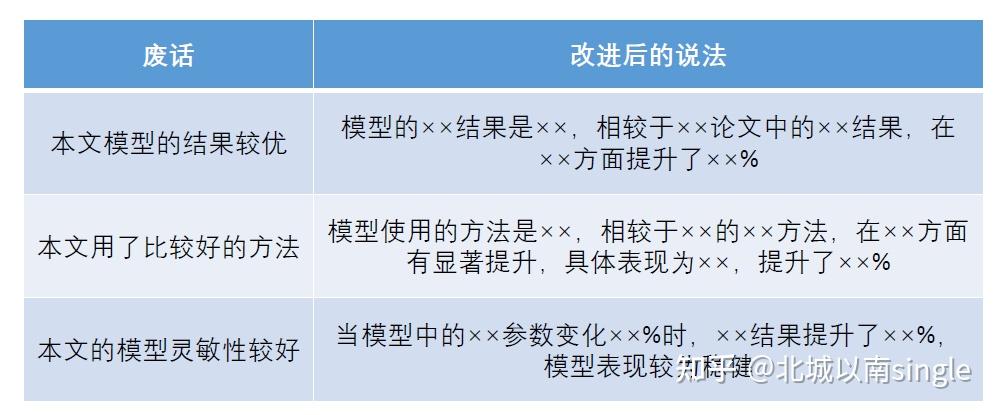
摘要中常见的废话
避免空洞、一定要紧密结合题目本身论述
编程与写作小技巧
三线表和文章同宽
表格先在excel中编辑好,再使用excel2latex插件导出,然后我们需要再修改一些代码使得三线表和文章同宽会,使得论文更加美观,代码如下:
% Table generated by Excel2LaTeX from sheet 'Sheet1'
\begin{table}[htbp]
\centering
\caption{问题3最佳参数}
\begin{tabularx}{\textwidth}{@{}c *4{>{\centering\arraybackslash}X}@{}}
\toprule[1.5pt]
$T_{15} (^\circ C)$ & $T_{06} (^\circ C)$ & $T_{07} (^\circ C)$ & $T_{89 }(^\circ C)$ & $v (cm/min)$ \\
\midrule
182.1140 & 189.8592 & 230.2581 & 264.9846 & 91.5834 \\
\bottomrule[1.5pt]
\end{tabularx}%
\label{tab:addlabel}%
\end{table}%
关键是下面这一句,其中的"4"为表格的列数减1
\begin{tabularx}{\textwidth}{@{}c *4{>{\centering\arraybackslash}X}@{}}
代码翻译阅读小技巧
在阅读一些英文网页的时候,如果我们不想直接看英文,一般可以利用谷歌翻译,不过翻译的时候会把代码或者数学公式给翻译了,给阅读带来了极大的麻烦。如何使谷歌翻译不翻译代码或者数学公式?
我们打开开发者工具,定位到不需要翻译的地方,在class里面添加 notranslate ,就能告诉翻译器不翻译这个元素。

以matlab的文档网站为例,学matlab虽然官方有很多中文文档,但很多工具箱是没有中文文档的,这时候不可避免需要阅读英文。
随便打开一个英文文档,找到一段代码,翻译一下,如图:
翻译前:

翻译后:

再来看数学公式的情况,翻译前:
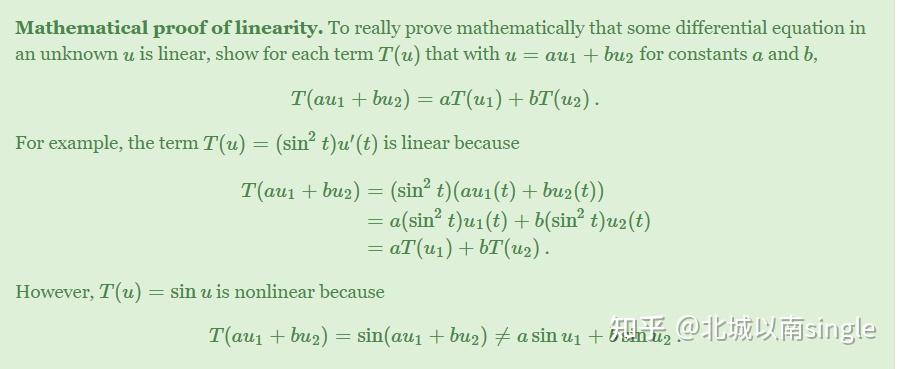
翻译后:

想必这时候大家阅读代码就非常不方便了。为此,我们利用自动化脚本,实现加载网页时自动为每一个代码\数学元素添加 notranslate。
首先需要安装油猴插件或者暴力猴插件
然后添加如下脚本:
// ==UserScript==
// @name 谷歌翻译绕过代码块(适配github,mathworks等)
// @description 让谷歌翻译插件翻译网页的时候,绕过代码块和一些无需翻译的元素
// @match http*://*/*
// @match localhost:*
// @match 127.0.0.1:*
// @match *
// @license MIT
// @grant none
// ==/UserScript==
/*jshint esversion: 6 */
(function () {
'use strict'
function noTranslate (array) {
array.forEach((name) => {
[...document.querySelectorAll(name)].forEach(node => {
if (node.className.indexOf('notranslate') === -1) {
node.classList.add('notranslate')
}
})
})
}
const bypassSelectorArray = [
'pre',
'code',
'.prism-code',
'.codeinput',
'.CodeMirror-sizer',
'.CodeMirror-lines',
'.CodeMirror-scroll',
'.CodeMirror-line'
]
if (window.location.hostname.indexOf("github") !== -1) {
// 如果是github 还需要处理一些别的元素
const githubSelector = [
'.bg-gray-light.pt-3.hide-full-screen.mb-5',
'summary.btn.css-truncate',
'.commit-author',
'.js-navigation-open.link-gray-dark',
'.Box-title',
'.BorderGrid-cell > div.mt-3 > a.muted-link',
'.BorderGrid-cell > ul.list-style-none'
]
bypassSelectorArray.push.apply(bypassSelectorArray, githubSelector)
//如果还有github的插件 还需要延迟追加一些
setTimeout(function () {
const githubPluginSelector = [
'.github-repo-size-div',
'.octotree-tree-view'
]
noTranslate(githubPluginSelector)
}, 3000)
}
if (window.location.hostname.indexOf("mathworks") !== -1) {
// 如果是mathworks
const mathworksSelector = [
'.codeinput',
'.code_responsive',
'.inlineequation',
'inline'
]
bypassSelectorArray.push.apply(bypassSelectorArray, mathworksSelector)
}
noTranslate(bypassSelectorArray)
// mathjax延迟加载
setTimeout(function () {
const Selector = ['.math','.MathJax','.MathJax_Display','.MathRow','.MathEquation','.CodeBlock']
noTranslate(Selector)
}, 4000)
})()
要是发现其他的不想翻译的被翻译了,添加相关元素进脚本即可。翻译效果如下: