本文主要介绍微财"在混合云中DevOps 工具方面的研究和探索,介绍了一套自研的自动化性能监控工具Prober 以及在微财内部使用效果,内容包含系统设计、方案成效以及部分代表性的问题解决等。希望通过本文的分享,为相关诉求的团队提供一定的思路参考。
1.何为Prober
Prober服务是好分期构建的企业云原生DevOps"体系,打造研发运维管理一体化平台中的一个节点。
在好分期业务快速发展过程中,各个服务大多采用敏捷开发、快速迭代的方式,而代码可能会被部署在公有云、私有云或者混合云中。在这种场景下,从问题的发现到修改,再到最后部署,需要大量的时间成本。特别是在互联网金融行业,系统的平稳永远是每位技术人员关心的核心指标,但是很难保证服务一定不出问题。在出现问题的时候,如何快速恢复服务并解决问题尤为重要。以下场景也是我们在业务发展中遇到过的场景:
线上服务cpu突然暴增或者有抖动;相同的代码在不同云环境中性能有较大差异;上线代码后内存逐渐增加直到OOM;压测过程中排查系统瓶颈点并优化系统,整体时间周期长。
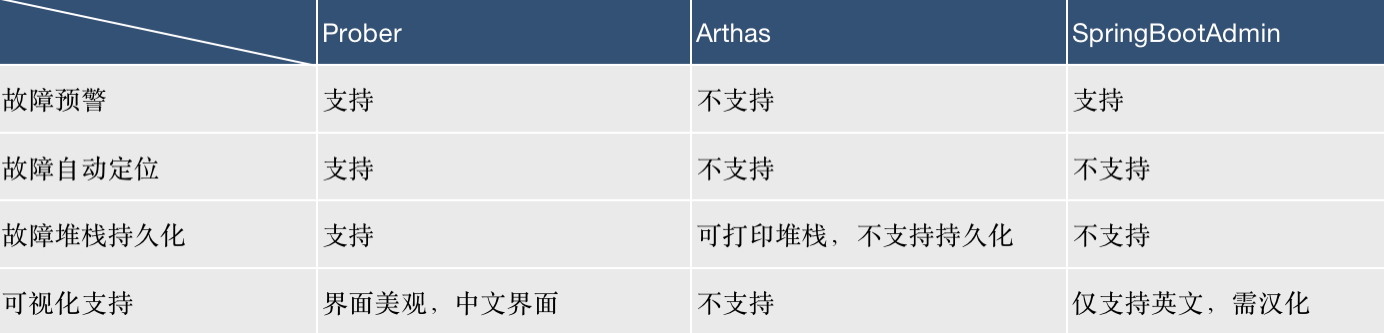
上述场景发生后,需要优先保证业务稳定,马上回滚。从业务角度来看,这是个比较好的解决方案,但是从技术角度来看,回滚后事故现场没有留存,想要排查问题需要逐一排查代码或者想办法复现,在这个流程中会耗费大量的时间成本。虽然通过SpringBootAdmin和Arthas都能够在一定程度上协助排查问题,但还是需要人工介入并进行相关操作,而Arthas的使用则是直接进入到了容器和JVM的内部,相关命令的权限问题不好控制。
那么,是否可以在不通过人为的介入下,对线上的问题进行提前感知,并能够在出现问题的情况下留存线上调用的堆栈信息,供开发人员解决问题使用呢?Prober便是答案。
2.Prober与现有监控服务的对比
在好分期业务快速发展,系统频繁发布,快速迭代过程中,技术人员需要对线上系统的各个指标负责,同时对问题的发生、深入排查、解决有严格时间要求。所以,我们需要一套更精准、更及时、更完善的自动化性能监控服务,提升在代码层面监控、预警、排查、解决这个过程的效率。
Prober对于部署所需资源较低,自研的故障自动定位和故障堆栈持久化更是可以精准排查系统问题,完善产品质量。针对CPU的监控预警,则可以将各个系统所占用的CPU资源降至最低,极大的提高了CPU的利用率,还有其它指标的监控,如内存,指定方法监控等等进一步为服务稳定保驾护航。
3.Prober服务设计
之前章节介绍了Prober的一些特点以及解决问题的优势,那它又是如何实现的呢?本章节将会通过架构设计、ProxyServer的设计与实现、ProberClient的设计与实现三个方面来概要介绍Prober的系统设计方案。
3.1 架构设计
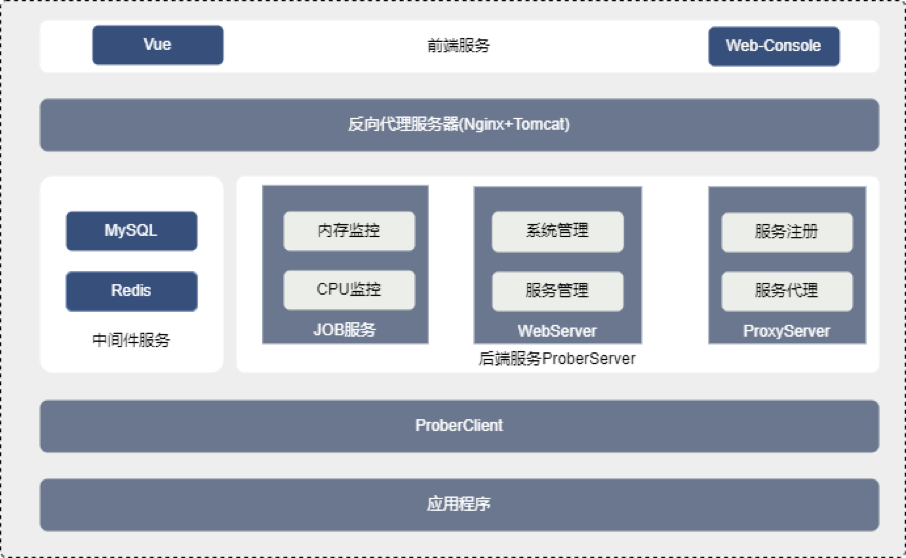
整体采用前后端分离,前端引入VUE和Web-Console,打造出良好的可视化界面。
ProberClient:客户端,供给应用程序以Maven依赖的方式集成,主要负责获取应用程序的CPU、内存以及堆栈信息等。WebServer:前端页面功能对应后端的服务模块。ProxyServer:基于Netty的ebSocketServer,可完成前端与ProberClient的代理工作。我们针对生产项目的重要指标,如CPU、内存、方法进行了自动化监控。
预警模块中保存了每种监控指标的监控方法、阈值、告警方式以及超出阈值后的行为等,目前支持CPU、内存、方法自动化监控。告警方式包括企微预警、短信预警、邮件预警。
那么,CPU、内存的信息获取,以及方法的监控又是如何实现的呢?接下来我们一起一探究竟。
3.2 ProxyServer的设计与实现
ProxyServer由HttpServer和WebSocketServer组成。其中HttpServer负责获取CPU的使用占比等,而WebSocketServer则负责获取堆栈、代码热更新等。
ProxyServer启动流程
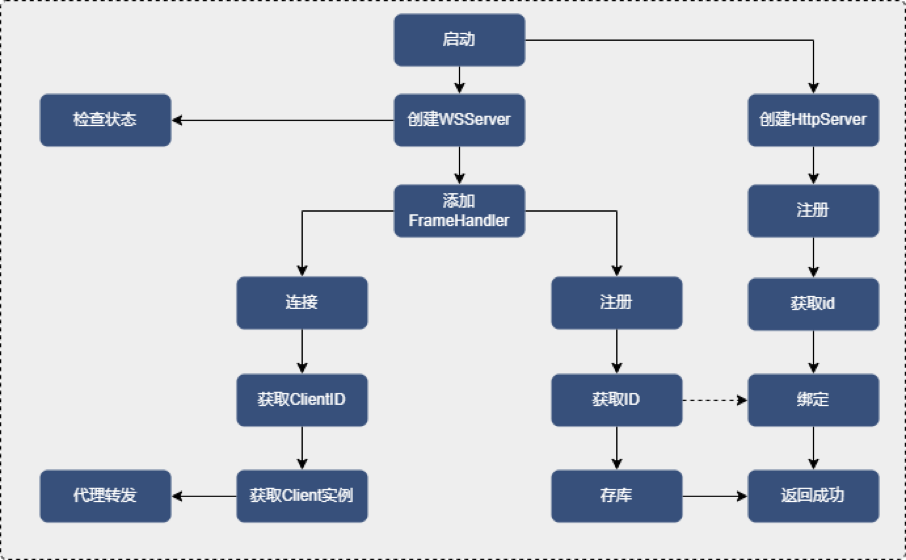
ProberServer集成Netty来创建WebSocetServer,如图所示,在服务启动时会使用ServerBootstrap创建一个服务器,用来监听ProberClint的注册与前端连接client的请求。
Netty 是一个高性能、异步事件驱动的 NIO 框架,基于 JAVA NIO 提供的 API 实现,Netty 的所有 IO 操作都是异步非阻塞。在 IO 编程过程中,当需要同时处理多个客户端接入请求时,可以利用多线程或者 IO 多路复用技术进行处理。
IO 多路复用技术通过把多个 IO 的阻塞复用到同一个 select 的阻塞上,从而使得系统在单线程的情况下,可以同时处理多个客户端请求。与传统的多线程/多进程模型比,I/O 多路复用的最大优势是系统开销小,系统不需要创建新的额外进程或者线程,也不需要维护这些进程和线程,因此选用了这个技术。
ProxyServer与前端、ProxyClient的连接交互方式
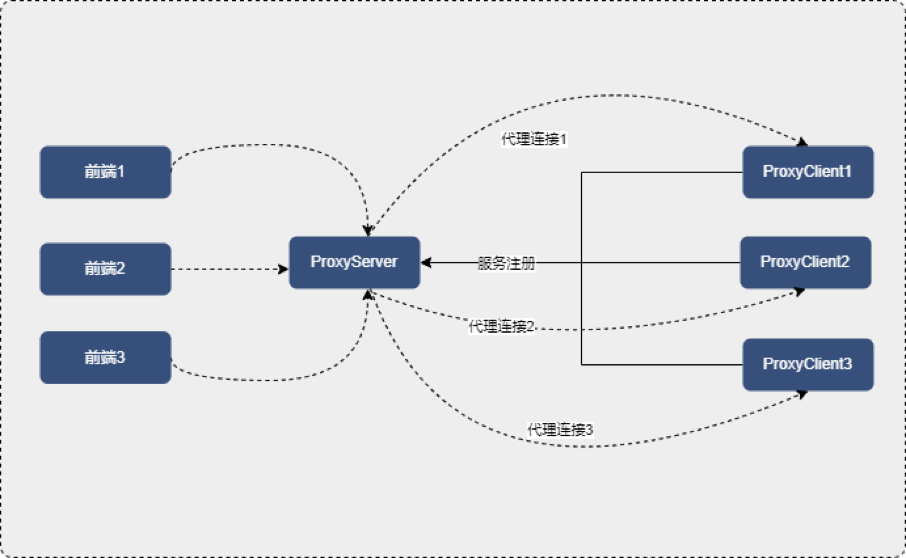
使用ServerBootstrap创建一个服务器,用来监听ProberClint的注册。自定义handler,创建一个client,用来连接前端。并将自定义handler传入初始化容器。client建立好连接之后,就可以从inboundChannel中读取数据并且转发给outboundChannel。对于client的outboundChannel来说,也有一个handler,在这个handler中,我们需要将outboundChannel读取到的数据反写到 inboundChannel中。ProberClient的设计与实现。

ProberClient分为prober-init、prober-core、prober-advice、prober-agent、prober-client五个模块。
prober-init为启动模块,负责ProberClient的启动。prober-core负责核心流程处理,包括执行ProberServer的指令、存储连接信息、抽象对象等。prober-client负责注册到ProberServer并维护连接。prober-agent负责attach到应用程序,获取应用程序的JVM运行状况等。prober-advice负责增强目标类。那么,我们的ProberClient又是如何完成获取CPU、获取堆栈信息以及实现方法监控的呢?
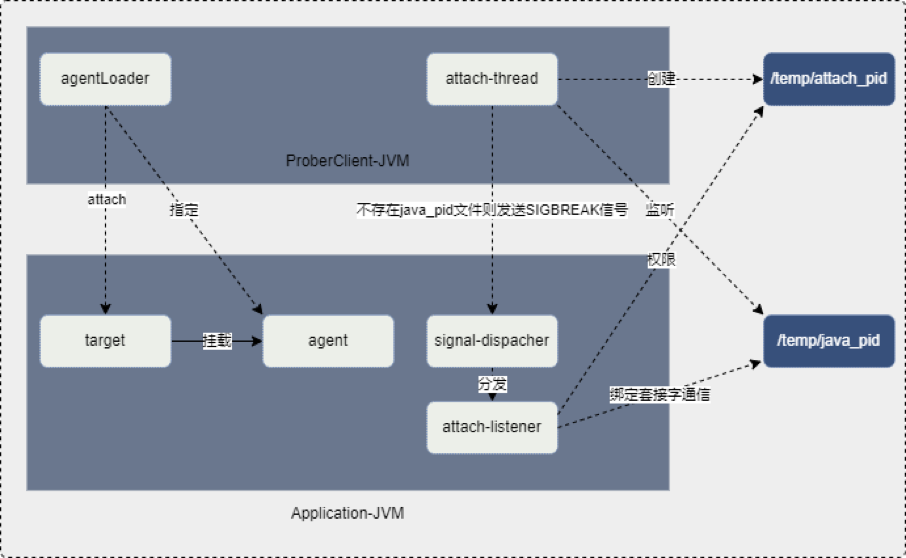
Instrument提供了对JVM底层组件的访问能力。ProberClient在main函数执行之后再启动自己的Instrument,通过addTransformer、retransformClasses、redefineClasses等实现代码热更新。正是基于此,ProberClient完成了对代码热更新的封装,可以方便的对代码进行热更新。
ASM是一个Java字节码操作框架,用来动态生成class或者增强class,cglib的底层就是它,ProberClient也是通过它实现对class的增强的。Arthas增强功能的核心是Enhancer和AdviceWeaver,对方法进行AOP织入,达到watch,trace等效果。ProberClient利用此实现了指定方法的监控。
AttachAPI可以让外部进程在目标JVM(运行被监控、被控制程序的JVM)中启动一个线程,该线程会加载运行Agent,然后线程会把本JVM的状态返回给外部进程。ProberClient利用这个机制可以获取JVM运行消耗的CPU、获取线程堆栈信息等。
JMX即Java Management Extensions是一个为应用程序植入管理功能的框架。ProberClient利用OperatingSystemMXBean、ThreadMXBean等扩展点来获取服务的CPU使用率、线程数等信息。
4.方案效果
目前,Prober服务已经开始逐步推广到技术部使用,服务对接Prober仅需要集成prober-client的jar包依赖,对接的服务,线上排查定位解决问题的时间成本缩短了90%以上,而在压测场景中,系统瓶颈分析并优化系统性能的时间周期是接入前的1/5,同时Prober服务也解决了在不同云环境中同步监控的问题,不论代码在何种云环境部署,均能自动监控对应的服务。
下面以还款相关服务接入并解决CPU耗费异常问题为例:
划扣模块是用户还款中的一个重要模块,但是随着业务量的快速增长,进入到还款队列的用户也快速增长,现阶段每天划扣的量级在千万级,随着划扣场景和划扣策略场景的多样化的推进,在整个划扣中从数据拉取、标签过滤、资金方过滤、债权情况、停催情况等20余种用于精细化划扣的节点中,Prober准确的分析并推送出了耗费cpu高的代码位置,以下是预警的截图
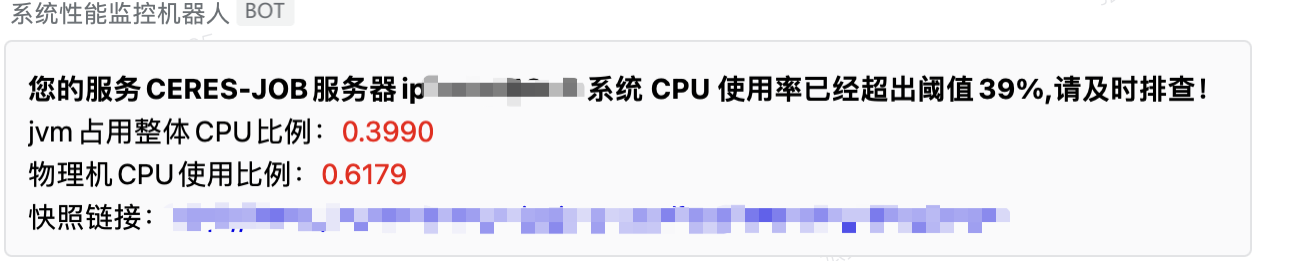
服务名称是每个服务的唯一标识,服务器ip则为docker中的服务的ip,jvm占用比例为当前服务jvm消耗物理机cpu占用比例,物理机cpu则展示当前物理机cpu使用情况,快照连接则为具体的堆栈信息,点击快照链接会进入页面如下:
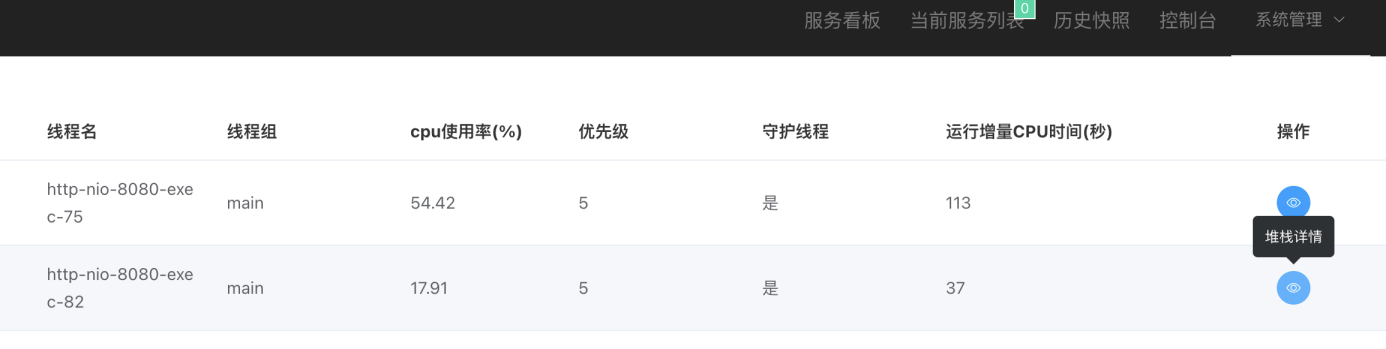
进入到这个页面后就会展示cpu飙高的时间点top2(可配置)的两个线程的堆栈信息,在堆栈详情中就可看具体到行的堆栈信息,经过了问题预警、堆栈的获取、数据的留存、消息的及时触达即可快速的定位和发现问题。
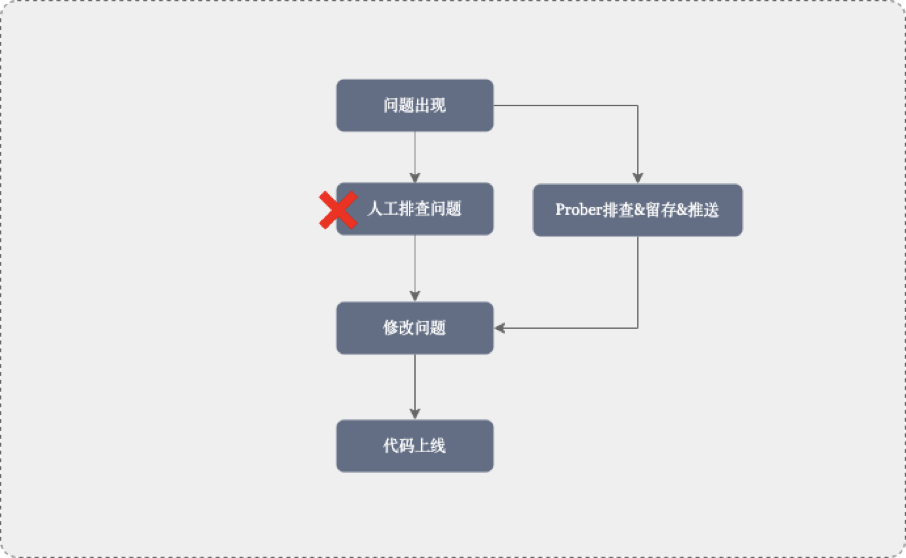
整个流程中将人工排查问题最耗时的步骤解决通过Prober服务进行替代,解决问题更准、更快,同时也解决了快速恢复业务事故现场无法留存,排查问题还影响线上业务的尴尬场景。
5.未来思考和下一步规划
从云原生Devops到云原生容器化修复
在云原生"的思想下,各个组织在公有云、私有云和混合云等新型动态环境中,构建和运行可弹性扩展的应用。通过云原生来帮助快速构建和运行应用程序,而云原生中的云的四要素是:微服务、容器化、DevOps、持续交付能力,针对于容器化这一点,每次发布服务都需要进行容器+环境+项目的构建,而整体的处理时间大部分会花费在容器构建和项目构建中。
所以在以下一个场景的问题作为思考和规划的决策点:线上出现代码层面的紧急问题,修改代码+项目构建+发布时间会很久,在发生问题情况下如何快速解决,特别是金融行业的服务,造成的损失甚至可以按照w/s(万/秒)来计算。在极短的发布周期,全面自动化的感知修复问题,是下一个阶段需要深入思考的问题。
未来Prober服务将通过问题预判、发现&留存故现场堆栈、问题的快速解决3个重心进行深入设计和开发,快速解决问题则是技术人员修改完代码后,在通过Prober服务快速进行所有虚拟节点的秒级的代码热更新进行问题的快速修复,这样就可以在已经构建好的容器中进行问题的快速修复,将几分钟甚至十几分钟的发布流程缩短至秒级,指数级的降低解决紧急事故的时间周期,当然版本维护、相关修改代码依赖性发布还需要进一步思考。
未来已来,只是分布不均。
作者简介:
张兆强,微财数科高级工程师
陈宽,微财数科工程师
吴迪,微财数科产品技术负责人
李军,微财数科技术总监
周正杭,微财数科资深工程师