本文整理自美团技术沙龙第80期《美团内容智能分发的算法实践》,分享内容主要包括三部分。第一部分介绍了大众点评内容搜索的场景特点以及面临的挑战;第二部分介绍了为应对这些困难和挑战,技术团队在链路各环节上做的实践优化,包括内容消费和搜索满意度的优化等等;第三部分是总结和对未来的展望。希望能对大家有所帮助或启发。
现状与挑战
美团在本地生活服务领域深耕多年,在帮助用户完成交易的同时,积累了丰富的图文视频内容供给。依托于这些内容供给,我们可以满足用户更丰富的需求类型,从交易环节扩展到交易前的种草、交易后的体验分享环节,将大众点评建设成为本地吃喝玩乐的社区。
在大众点评的用户中,有相当高比例会通过搜索来查找本地信息,而内容搜索是辅助用户决策、促进社区氛围的重要工具。例如当用户搜索“火锅”时,除了能看到火锅相关的商户和团单,还可以看到图文、视频、评价、笔记等多种形态和类型供给呈现;搜索“圣诞节活动”时,直接以双列内容形式呈现搜索结果,可以更加生动形象。

通过持续优化内容搜索体验,可以带来更多内容消费流量,进而吸引更多的用户转化为作者,激励创作出更多的内容,而有了更多的内容之后,又可以进一步带动体验提升,最终形成一个良性循环。
从实际效果来看,内容搜索的价值也得到了用户的认可,如下图是用户访谈原声,可以看到通过内容搜索结果逐步拓展了用户对搜索功能的认知。

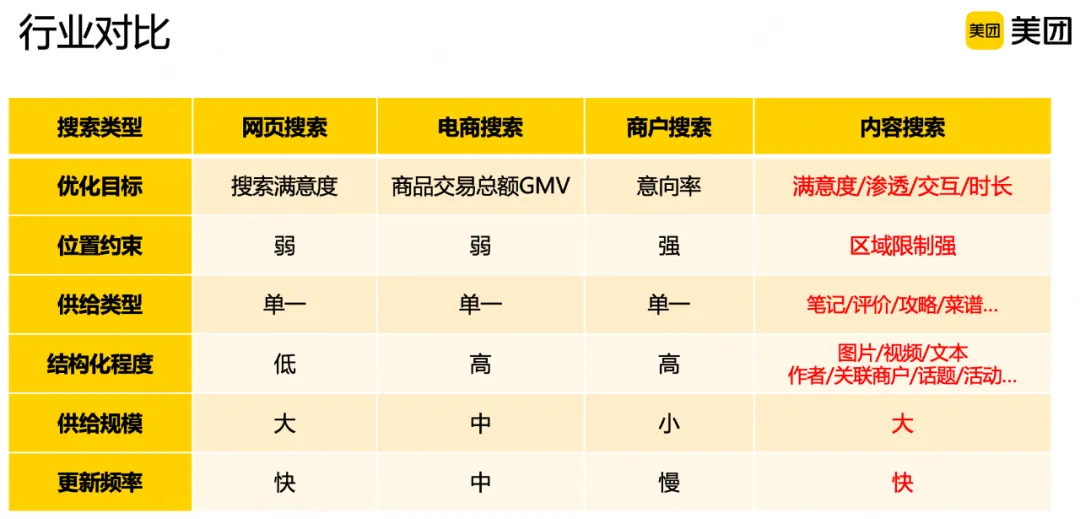
内容搜索与典型类型的搜索如网页搜索、电商搜索、商户搜索等相比,有如下差异点:
在优化目标上,网页搜索更强调搜索满意度,电商搜索更看重商品交易总额,商户搜索更关注用户到店消费意向率,而内容搜索既要考虑搜索满意度,又要考虑点击和点击内容后的停留时长、点赞/收藏/转发/评论等交互行为。在地域约束上,网页搜索和电商搜索没有特别强的地域限制,而商户搜索和内容搜索却有非常强的LBS区域限制,因为用户在美团点评的搜索场景下更希望查找附近的商户和内容。在供给类型上,网页搜索、电商搜索、商户搜索结果类型较为单一,而内容搜索有非常多的类型,比如笔记、评价、旅游攻略、菜谱等。在结构化程度上,电商搜索和商户搜索相对较高,因为有商家和销售维护相应信息;网页搜索一般结构化程度比较低,可被检索的网页大部分信息是非结构化的;内容搜索的供给中既包括图片、视频、文本等非结构化信息,也有内容关联的作者、商户、关联话题等结构化信息,整体呈现半结构化的特点。在供给规模上,电商搜索和商户搜索供给量级相对可控,因为商品、商户的生产维护成本较高;而网页搜索和内容搜索的供给生产成本低,规模会相对更大一些。在更新频率上,一个商品从上线到下架、一家店从开业到关停,需要相当长的时间周期,而内容和网页生产和更新频率都更快一些。
从以上对比来看,内容搜索在各个维度上与典型的搜索类型存在很大区别,这就需要结合自身特点,进行相应的技术选型和方案设计。
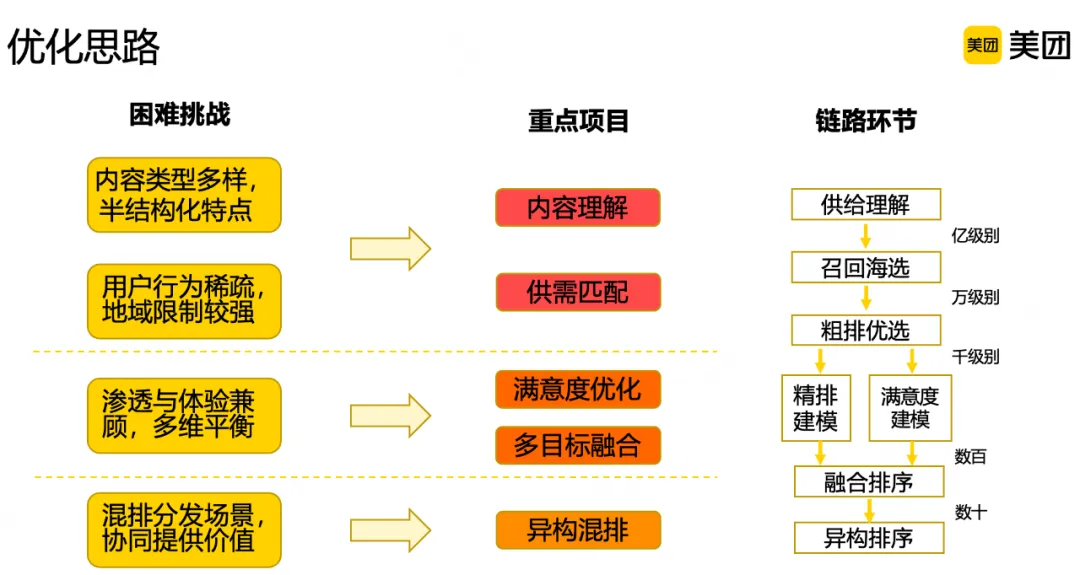
我们对面临的困难挑战进行总结,主要包括以下四个方面:
多种类型供给并存,且供给中既有结构化的信息,又有非结构化的信息。内容供给量级大且更新频繁,导致用户行为分散,单篇内容较难获取到足够的用户行为数据;在分发过程中又有较强地域限制,形成类似蜂窝状的消费规律,进一步加剧了用户行为稀疏的问题。在优化过程中既要拉动内容消费指标,也要兼顾搜索满意度,在推进中需要综合平衡多个维度。在最终搜索结果中,内容与商户、团单等以混排形式呈现,需要与其他类型搜索结果协同发挥价值,共同满足用户需求。

内容搜索优化实践
下面我们会从面临的问题和挑战出发,分享如何通过链路各环节,持续优化内容搜索的体验。
供给理解
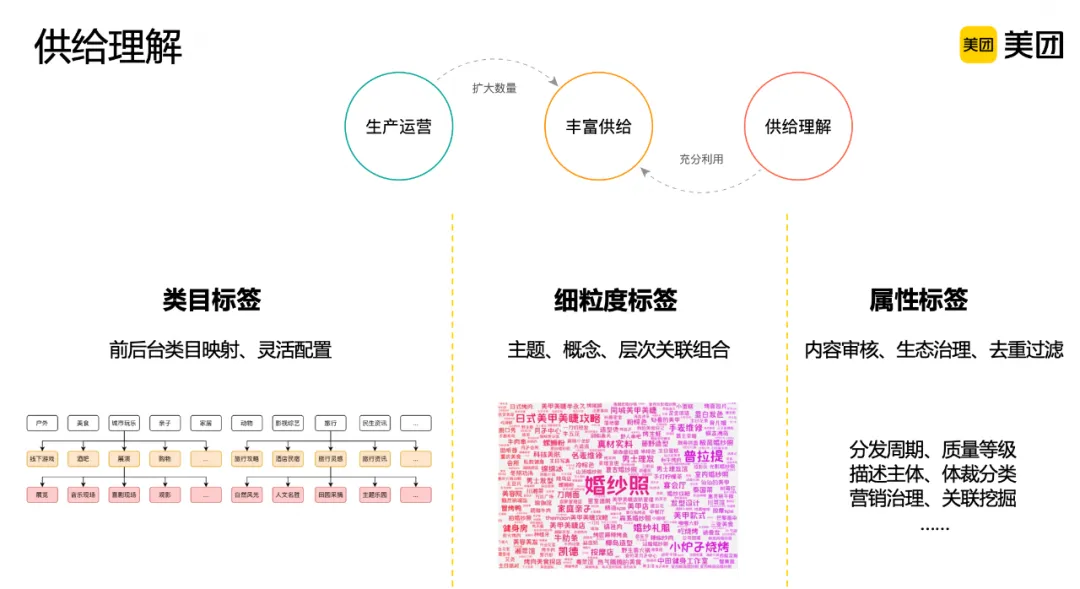
面对用户持续创作生产的海量内容,我们需要对其进行充分理解,包括显式标签和隐式表征两部分工作。显式标签体系主要包括:
类目标签:通过构建分发前台后台两套标签,可以实现前后台类目灵活映射。当需要进行前台类目体系调整时,可以通过调整映射层快速支持,减少对后台打标任务的影响。细粒度标签:类目标签个数有限,在推荐搜索等分发场景还需要更细粒度的刻画,为此构建主题标签、概念标签等,相互之间有一定的关联和组合关系。属性标签:前两类标签更多关注内容在讲什么,而属性标签更侧重于刻画内容本身是什么,比如是否涉政涉黄、是否重复、是否命中生态治理等。
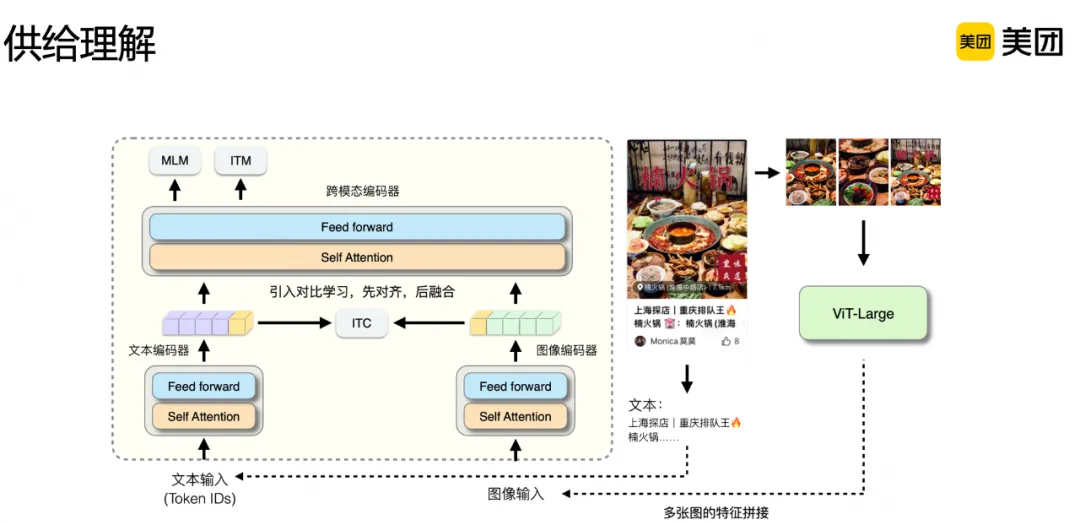
除了显式标签,分发链路很多环节还需要更加泛化的隐式表征。结合实际场景特点,我们自研了多模态预训练模型,通过引入对比损失把图文表征对齐到统一特征空间,并结合自监督对比学习训练范式、掩码学习、图文匹配等优化,提升了跨模态交互效果。
召回环节
作为最前置环节,召回决定了一次搜索查询所能拿到的候选总集合,直接影响到后续环节的效果天花板。搜索场景的召回主要包括:
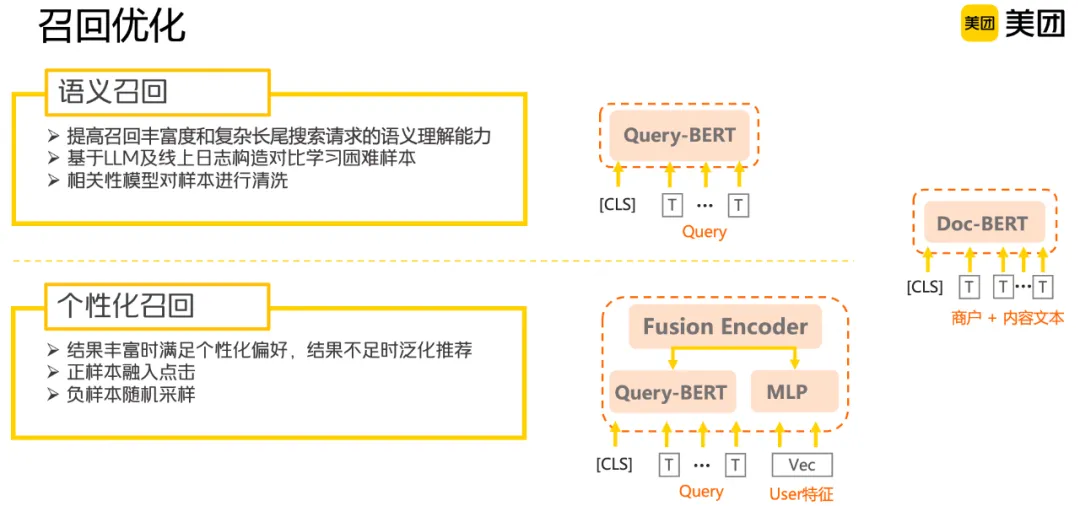
语义召回:搜索召回需要首要保证结果相关,为此对语义召回进行了多维度的设计,包括不同颗粒度的语义单元召回、对用户需求进行细化和泛化处理。个性化召回:结合用户地理偏好、特定区域偏好与用户历史消费内容相似度等,设计召回通路满足个性化需求。策略召回:基于用户不同场景的实际需求设计对应策略,包括最新最热内容的召回、更符合种草需求的高价值攻略召回、定向搜索作者内容或特定类型如菜谱的召回等。
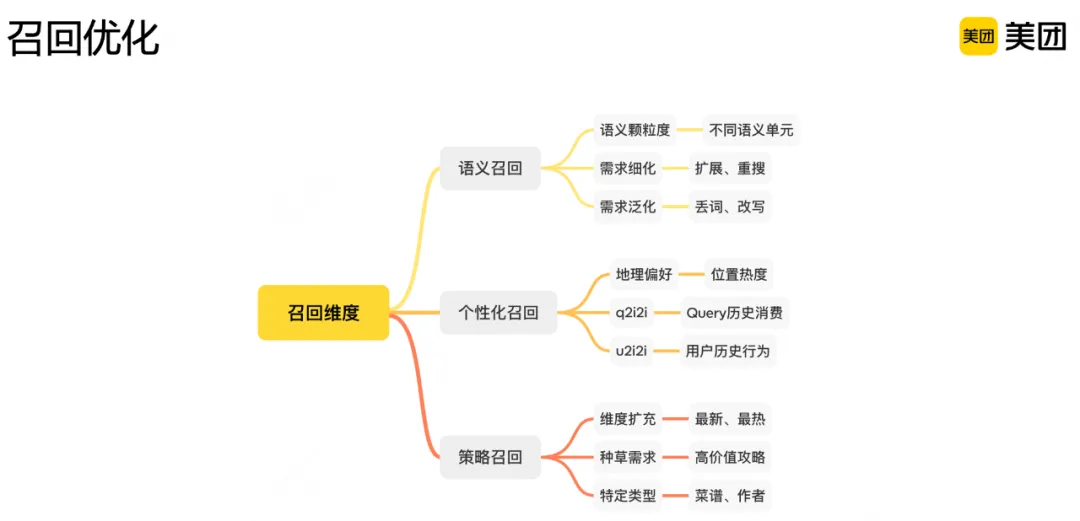
其中语义和个性化召回有很大部分通过隐式实现,语义召回更侧重搜索词自身信息的刻画,而个性化召回还融入了用户偏好、上下文等很多信息。
排序环节
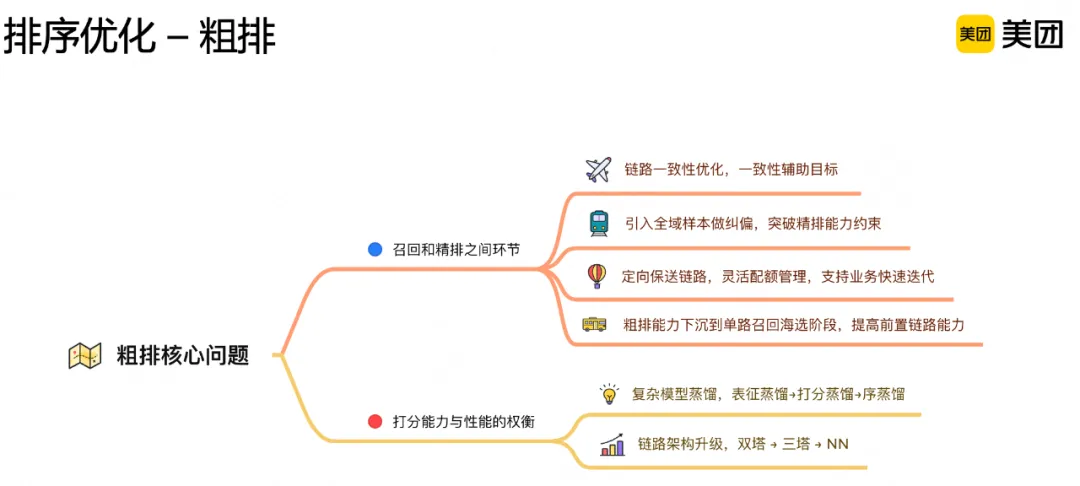
排序包括粗排、精排、多目标融合排序、异构混排等多个环节,随着逐层筛选,打分量级依次减小,可以使用结构更复杂、规模更大的模型。
介于召回和精排之间的粗排环节,需要兼顾准确性和全面性、权衡打分能力和时延性能,发挥承上启下的作用。为此引入用户在全域的行为样本,达到系统层面的纠偏作用;我们通过表征蒸馏、分数蒸馏和顺序蒸馏等方法,提升模型表达能力;在常见Query-Doc双塔结构基础上,引入交叉塔(如交叉点击率、时长等),提高特征交互能力。
精排环节着重介绍在输入表征层、多目标建模层和输出层的相关工作。
首先是模型输入表征层,为了准确刻画Query、用户、Doc、上下文等多种维度、各种粒度、各种来源的输入信息,我们从以下几个方面进行表征。
Query语义表征:搜索场景下Query是用户需求的直接表达,借鉴向量检索的工作,对Query进行了不同粒度的刻画,通过多粒度语义网络进行搜索词表征。用户序列表征:引入用户全站行为序列,捕捉用户长短期个性化偏好。搜索场景需要兼顾个性化和相关性,但用户历史行为和当前搜索词不一定存在关联,为此在主流建模方案DIN基础上,引入零向量注意力机制来权衡个性化和相关性。具体来说,引入了Query语义表征,对长尾低频Item做过滤,帮助模型决策哪些历史行为和当次搜索词相关,且在历史行为和搜索词无关时不引入额外的噪声。多模态表征:图像、摘要等创意维度信息,对于用户决策至关重要,也是内容高效分发的基石。为此引入高维的多模态预训练向量,并结合场景进行端到端降维,既引入了丰富的多模态语义信息,又能够兼顾线上时延,对于刻画用户的多模偏好、提升新内容高效分发至关重要。特征重要度建模:通过动态权重的建模范式,捕捉样本粒度的动态表征,可以有效增强模型的表达能力。通过在EPNet、MaskNet等模型结构基础上,结合场景特点设计域感知的多门控网络、并联结构,实现了特征重要度的动态建模。
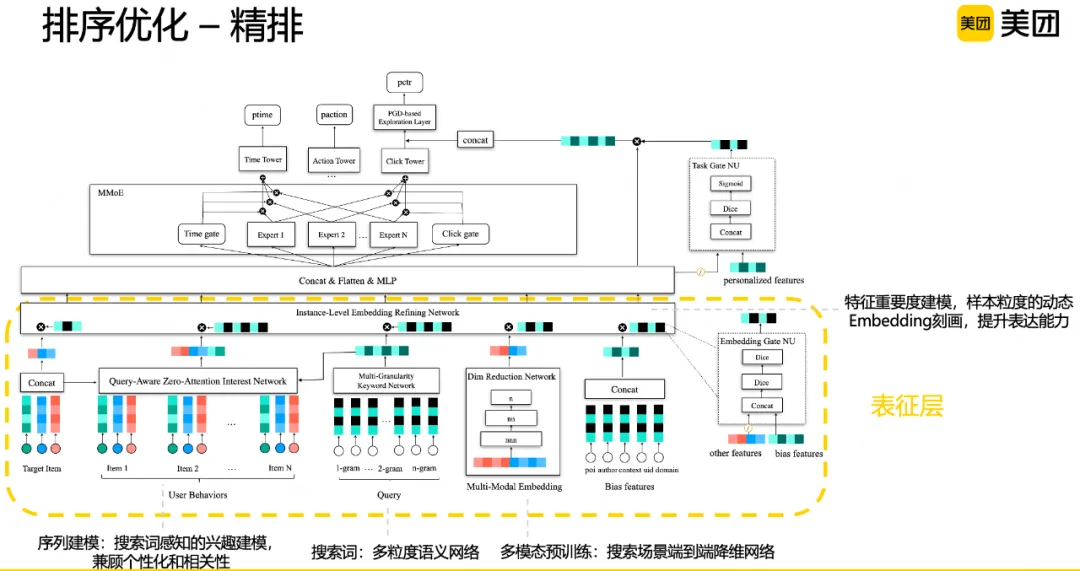
接下来是多目标建模层,由于点击、时长、交互等各个目标行为量级不同,导致优化过程中很容易出现跷跷板问题,为此在模型结构、优化方式等方面进行相关探索。
模型结构:我们采用MMoE和PPNet融合的方案,为了防止Gate极化现象,对门控网络结构上进行dropout、设计skip connection等;在各个任务上会引入个性化因子,通过个性化网络PPNet建模,MMoE和PPNet的输出会拼接后传到预估输出层。优化方式:底层稀疏Embedding很容易受到各个多目标梯度反传的影响,造成梯度冲突,从而引起指标跷跷板问题。为此针对重要的表征增加参数量或新增任务特定表征,并对重要表征控制梯度反传,时长或交互目标不更新底层部分Embedding或更新时设置较小学习率。
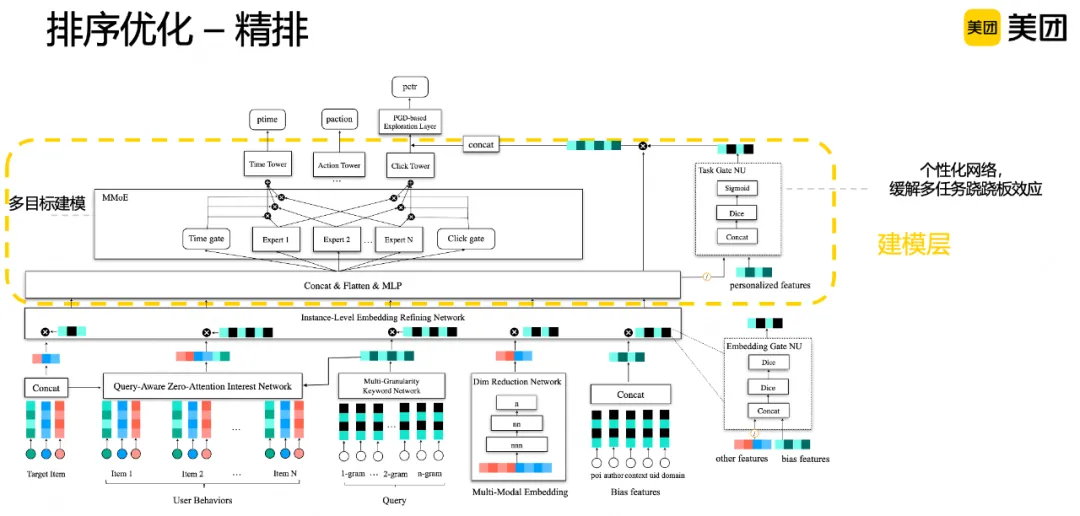
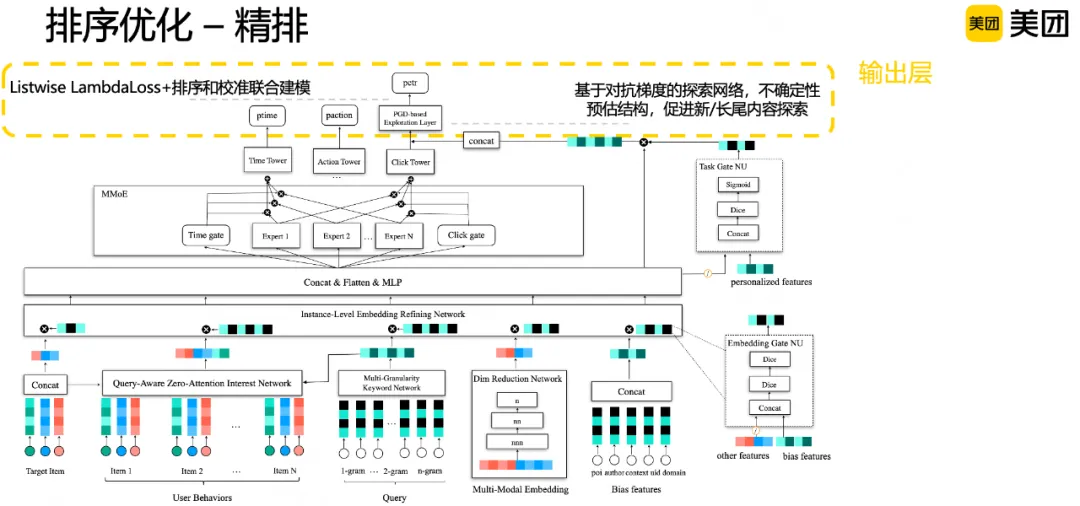
最后是模型输出层,为促进新内容、长尾内容分发,并保证模型输出的预估分的稳定性和准确性,我们从探索结构和学习目标上进行了对应优化。
探索结构:搜索场景消费内容个数比推荐少,马太效应问题也更加严重,对行为积累不够充足的新内容或长尾内容,预估不够准确。为此设计全链路冷启和探索通道,并基于不确定性预估范式,在模型中引入基于对抗梯度的探索网络,基于CTR预估的不确定性和对抗梯度在输入侧做扰动和探索。学习目标:之前搜索场景采用的学习目标是Listwise的Lambdaloss,在排序能力上优于Pointwise,但预估准确性上不足,会造成后续链路无法使用预估分。业界有不少研究关于Listwise损失如何做预估校准,例如KDD 2023中阿里巴巴校准工作JRC、CIKM2023中Google校准工作等。参考相关工作并结合场景特点,在原有的LambdaLoss基础上增加用于校准的Logloss,在梯度更新上控制校准Loss不影响底层的Embedding更新,只更新多目标建模层和输出塔的参数,提高预估分数的稳定性和准确性,方便后续融合、混排等环节使用。
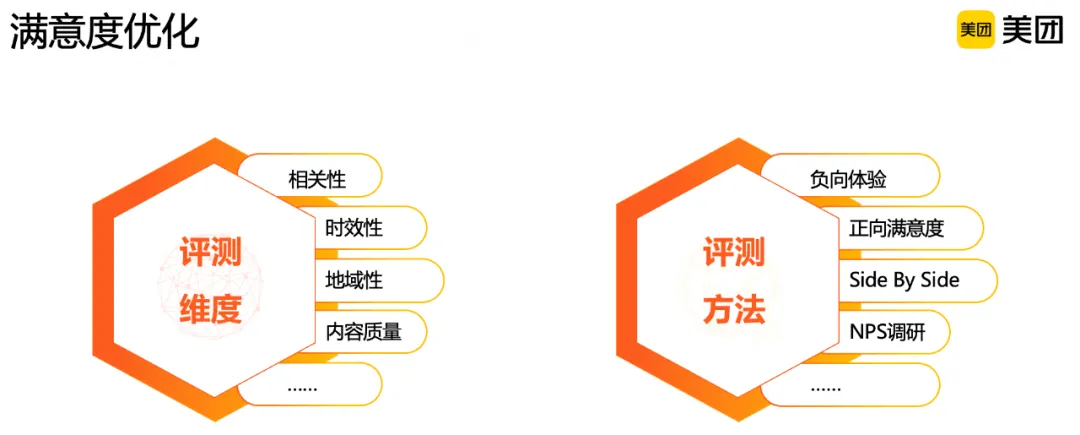
满意度优化
除了优化内容消费指标如点击、交互、时长等,搜索场景还很重视满意度优化。用户对搜索结果是否满意,可以从结果是否相关、是否足够新鲜、是否是对应地域、内容质量高低等显式维度进行刻画。
相关性是搜索满意度中最基本、最重要的维度。大众点评的很多内容有关联商户,可以比较方便地获取很多明确的结构化信息,比如商户类目、区域等,可用于辅助判断相关性。但也可能由于内容误关联商户带来噪音,为此需要综合从图片、文本、商户信息进行关键信息抽取,作为相关性模型的输入。

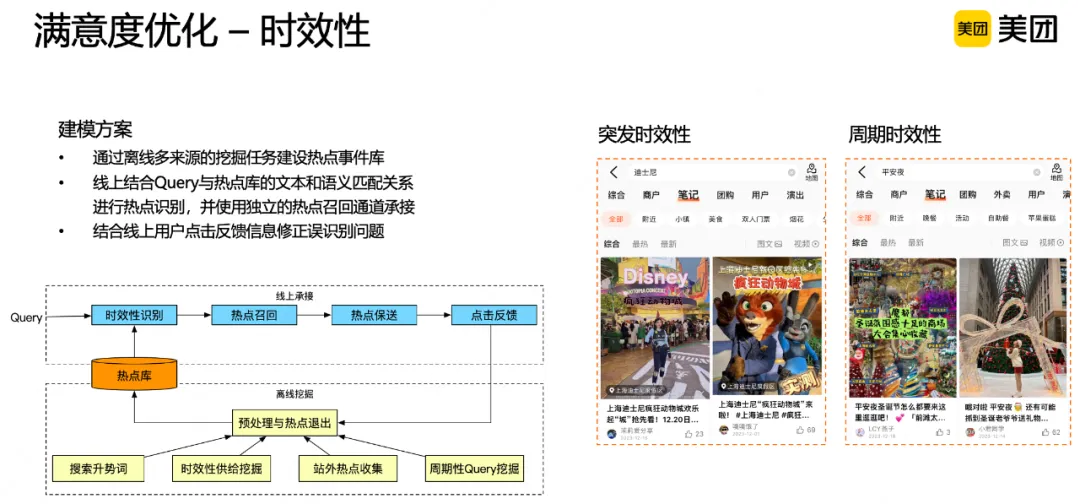
除了相关性,搜索结果的时效性也很影响用户体感。比如迪士尼疯狂动物城园区开始对外开放,属于突发性热点,通过敏锐捕获到突发热点,在搜索“迪士尼”时优先呈现对应的结果,可以带给用户惊喜。另一类查询词如“平安夜”属于周期性时效性热点,每年到这个时间段都会有这样的热点。为了更好地对时效性进行建模,从多个来源挖掘建立了热点事件库,接入商家自己提报的新鲜事,建立独立召回通道进行承接,并结合线上点击反馈进行误识别纠正。
以上满意度的评测通常较为依赖人工标注,近期开始探索自动化标注,对比分析如下:
在成本和效率上,人工标注需要准确理解搜索诉求,并对结果进行精确评判,从相关性、地域性、时效性、内容质量等维度进行刻画,成本非常高,通过自动化标注可以极大降低成本。在标注准确率上,虽然还没有完全达到人工标注的水平,但自动化标注也达到了可用标准。在标注维度上,自动化标注可以比较方便地对原有标注维度进行扩充,成本变化可控,比如在Prompt中提供用户的历史行为和偏好,就可以综合判断个性化需求是否得到了满足。在标注稳定性上,人工标注质量可能会受标注人员主观判断甚至心情影响,但自动化标注不会有这样的问题。
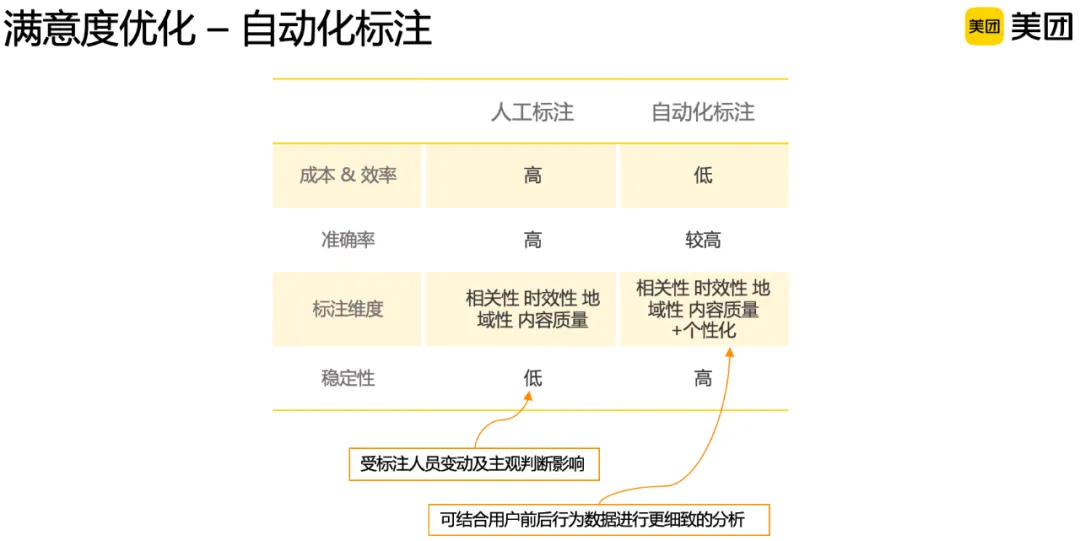
在具体实现上,我们通过分步推理来实现自动化标注,首先分析用户当前意图,再结合当次搜索Query、搜索意图、搜索结果等信息,从几个维度对搜索结果进行分析,最终综合判定当前搜索结果对需求的满足程度。

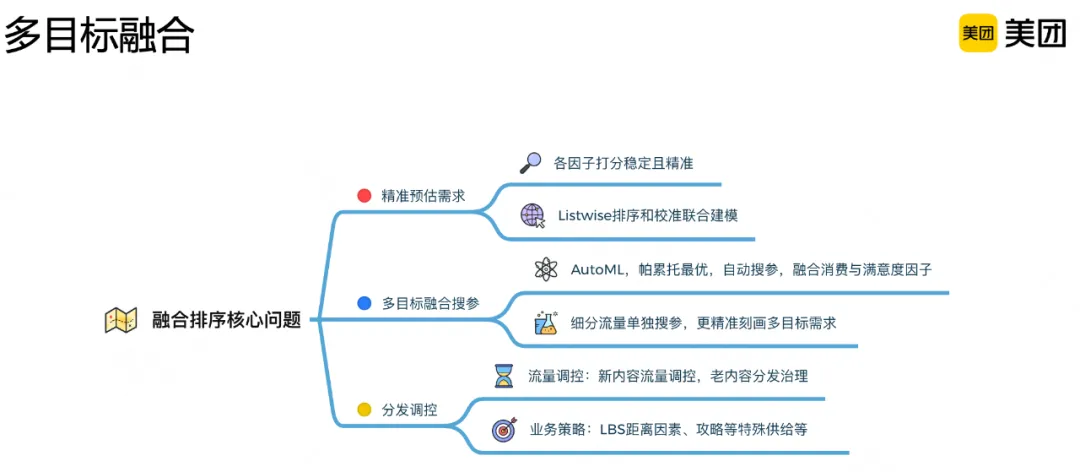
多目标融合
在得到内容点击、交互、时长、满意度等多维度的预估分数后,多目标融合层负责融合各个维度分数并排序。
精准预估:多目标融合的前提是保证各个因子的打分稳定性和精准性,这也是前文提到做排序和校准联合建模的原因。融合搜参:通过AutoML方式进行自动搜参,寻找帕累托最优解,针对细分流量进行单独搜参,更加精准地刻画不同场景下对于各个目标之间的不同需求。分发调控:将生态或调控导向的因子引入融合公式,进行分发调控,比如对于新内容的扶持、更老内容的分发治理、近距离和特殊供给扶持等。
异构混排
前面各环节动作集中在内容搜索自身链路上,而最终内容是作为搜索结果的一部分和商户、团单等不同类型结果混排,追求整体搜索收益的最大化,为此需要进行多元异构混排。业界常见的混排建模方式包括端到端建模、价值融合公式、序列生成和评估等。

此外,本地生活领域流量分布有独有特点,在用户快决策和慢决策的场景下,对内容的需求存在差异,午餐和晚餐流量高峰期对内容的点击偏低,下午茶和夜宵等时段内容消费意愿更强。结合内容和商户峰谷差异,依托工程能力如流量价值预估、模型算力和服务稳定性监控等,进行算力动态适配,从而保证整体搜索结果更能满足用户需求。
总结与展望
综上所述,大众点评内容搜索通过优化用户体验持续提升渗透率,进入快速增长阶段。在商户体系之外构建了基于内容的搜索分发能力,同时针对站内需求和供给特点进行了专项建设。

在后续工作中,希望建立体验问题的自动发现机制,帮助产运促进供给生产,并推动大模型在各个环节扎实落地、提升全链路的时效与性能,让内容得到高效准确及时的分发,进而在本地生活信息领域形成体验优势,助力建设本地吃喝玩乐社区。

本文作者
一帆、陶然、涛锋、圣昱,均来自大众点评事业部 。
参考文献
[1] Li S, Lv F, Jin T, et al. Embedding-based product retrieval in taobao search[C]. Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. 2021: 3181-3189.
[2] Ai Q, Hill D N, Vishwanathan S V N, et al. A zero attention model for personalized product search[C]. Proceedings of the 28th ACM International Conference on Information and Knowledge Management. 2019: 379-388.
[3]Chang J, Zhang C, Hui Y, et al. Pepnet: Parameter and embedding personalized network for infusing with personalized prior information[C]. Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2023: 3795-3804.
[4] Wang Z, She Q, Zhang J. MaskNet: Introducing feature-wise multiplication to CTR ranking models by instance-guided mask[J]. arXiv:2102.07619, 2021.
[5] Chang J, Zhang C, Hui Y, et al. Pepnet: Parameter and embedding personalized network for infusing with personalized prior information[C]. Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2023: 3795-3804.
[6] Burges C J C. From RankNet to LambdaRank to LambdaMART: An Overview; 2010[R]. MSR-TR-2010-82. Available from: https://www.microsoft.com/en-us/research/publication/from-ranknet-to-lambdarank-to-lambdamart-an-overview, 2010.
[7] Sheng X R, Gao J, Cheng Y, et al. Joint optimization of ranking and calibration with contextualized hybrid model[C]. Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2023: 4813-4822.
[8] Bai A, Jagerman R, Qin Z, et al. Regression Compatible Listwise Objectives for Calibrated Ranking with Binary Relevance[C]. Proceedings of the 32nd ACM International Conference on Information and Knowledge Management. 2023: 4502-4508.