重点新闻(0329~0405)
生成式AI Google 效能
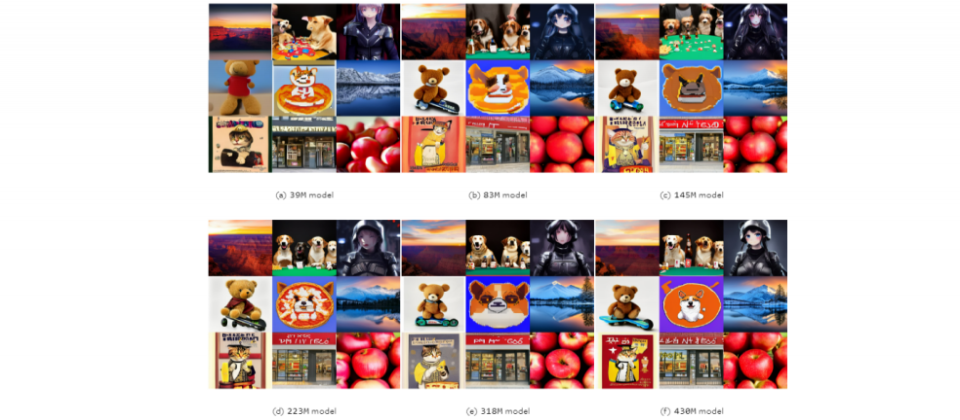
生成模型越大未必越好,Google揭露新研究发现
Google联手约翰霍普金斯大学,针对图像生成模型做了项扩展性和效率的研究,并发现模型并非越大越好。进一步来说,团队锁定潜在扩散模型(LDM)的大小和采样效率,其中,LDM是图像生成的常用模型,擅长根据文字描述,生成高品质图像。
在研究中,团队训练了12个文字转图像的LDM,这些模型大小不一,从3,900万到50亿个参数不等。接著,团队用各种任务来评估模型表现,包括文字生成图像、提高解析度、主题驱动的合成等。他们发现,在给定的有限运算资源下,小模型的表现比大模型要好,能产生更高品质的图像。而且,小模型的采样效率在各种扩散采样器中都是一样的,就算在蒸馏模型中也是。换句话说,小模型的优势,不限于特定的取样技术或模型压缩方法。
不过,研究也发现,当运算资源没特别限制时,大模型依然擅长生成颗粒度更细致的细节。意思是,小模型虽然可能更有效率,但在某些情况下,仍需要大模型。团队认为,该研究影响深远,因为了解LDM扩展性、模型大小和效能的状态后,开发者可在效率和品之间取得平衡,打造所需的AI模型。(详全文)

生成式AI 国科会 选拔赛
国科会发起GenAI Stars生成式AI百工百业应用选拔
为推动生成式AI应用,国科会宣布举办首届GenAI Stars生成式AI百工百业应用选拔,分为创意创客组、创新创业组两大类。其中,创意创客组是针对高中职、大专院校和社会人士,可细分为高中职组和大专社会组两组,参赛者可使用生成式AI工具,来进行创意应用,同时,创意创客组参赛者也能参加企业挑战题目,也就是由多家知名企业提出的题目,详细出题内容、解题资源和奖励预计在4月12日公布。
而创新创业组则针对国内外企业、新创、学研单位、政府机关或自组团队参加,竞赛主题为与生成式AI有关的企业内部解决方案,或是创新产品与服务,评审将优先考量有边缘运算的应用。特别的是,通过复审、进入决审的20组团队,可获得每队10万元辅导金、技术资源(如算力、GenAI工具等)、深度辅导资源,最后决审将筛选出的前三名队伍,可分别获得150万元、100万元和50万元。GenAI Stars生成式AI百工百业应用选拔即日起开放报名,至5月15日下午3点为止。(详全文)
文字嵌入 Google Gecko
Google发表强大的文字嵌入模型Gecko
日前,Google团队发表一款文字嵌入模型Gecko,可将大型语言模型(LLM)提取到检索器中,来实现强大的检索效能。进一步来说,文字嵌入模型目的是将自然语言转换为密集向量,将语义相似的文字放在距离相近的嵌入空间,就像是电脑的翻译机,将文字转为电脑可理解的数字。有了文字嵌入,电脑就能用来执行各种下游任务,如文件检索、分类等。
而Gecko是一款通用的文字嵌入模型,有别于以往只为单个下游任务建立各自的嵌入模型,Gecko由LLM加持,单一个模型就能支援多种下游任务。Gecko的运作方式可分为2步骤,首先是用LLM生成一组组多样的资料,再来是精炼这些资料品质,也就是为每个查询,用检索方式找出一系列的候选文章段落,并用同一个LLM,来对文章段落的正负值重新贴标。
也就是说,在一个大型未标注段落的语料库中,团队使用少样本提示,让LLM为每个段落生成相关的任务和查询。接著,他们将预训练嵌入模型,嵌入一连串的任务和查询,来获得最相近的段落,并用LLM对段落重新排序,同时根据LLM评分来得出正负向的段落。这种方法,让Gecko实现强大的检索表现,不过该模型尚未开源。(详全文)

Cloudflare Workers AI Hugging Face
Workers AI正式上线,还支援Hugging Face一键部署模型
最近,CDN服务大厂Cloudflare发布推理平台Workers AI的一系列更新,包括完成公测、正式上线,能提供更高的可靠性和效能,并公开定价,还在目录中新增更多模型。在效能部分,他们升级了Workers AI内建的负载平衡,另也提供更多城市、更多GPU资源来处理请求,还能灵活将请求分派至可用站点。在正式版本中,Cloudflare也提高了模型速度上限,将原本大型语言模型(LLM)每分钟只能接收50个请求,提高至每分钟300个请求,小模型则是每分钟1,500个至3,000个。
此外,Workers AI还与Hugging Face联手,新添了可支援的4个模型,包括 Mistral 7B v0.2、Mistral 7B、Google的Gemma 7B和Starling-LM-7B-beta。而且,使用者可在Hugging Face的模型卡页面,在部署栏位点击Cloudflare Workers AI,就能利用Cloudflare全球GPU网路资源来直接部署模型。目前,Hugging Face支援的模型共有14个,接下来还会有更多模型加入。
另一方面,Workers AI也发布了10个非测试版的计价器,来提供使用者更划算的用法。与之类似的还有新版仪表板,可显示跨模型的使用状况分析,包括神经元计算,可帮助使用者预测价格。Cloudflare也更新了AI试炼场,可让使用者快速测试和比较不同的模型,并设定提示和参数。(详全文)
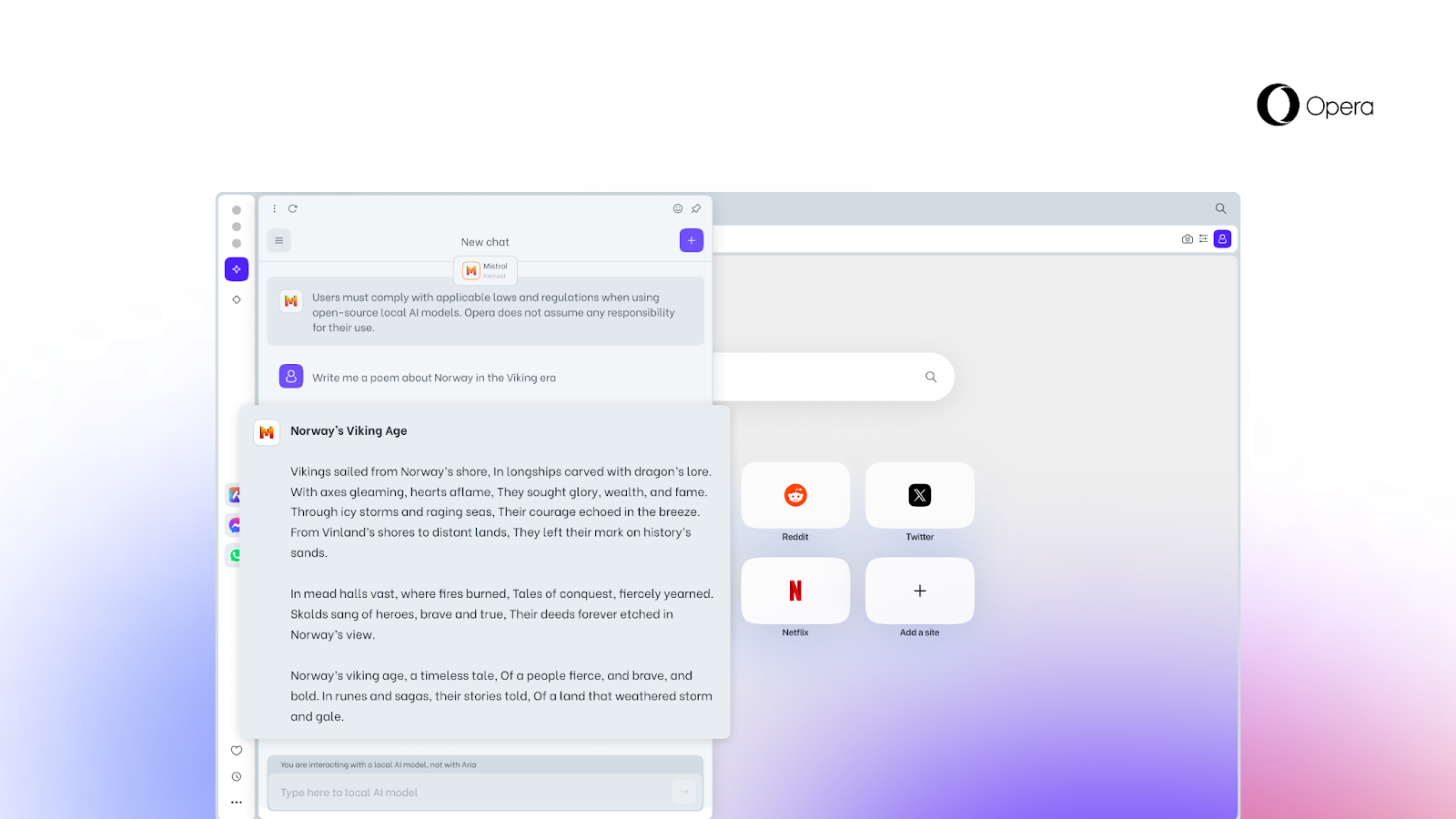
LLM Opera 浏览器
在本机就能执行和测试LLM!Opera浏览器推出新功能
网页浏览器Opera最近发布一项新功能,用户可将大型语言模型(LLM)下载到本机端执行或测试,不必再连上伺服器端,意味著资料不须离开电脑。在这项新功能中,Opera支援近50个系列、共150款本机端LLM,包括Meta的Llama、Vicuna、Google的Gemma和Mistral AI的Mixtral等,允许用户透过浏览器下载。
新功能目前以测试版发布给Opera One开发人员。Opera One是去年6月推出的AI浏览器,整合原生AI技术的浏览器,目前也整合Opera自家的AI助理Aria Chat。目前,开发者可下载Opera One开发者版测试,在本机上使用所支援的LLM和Opera实验性AI功能。(详全文)
天气 Google 生成式AI
Google打造生成式AI天气预报模型
最近,Google发表最新天气预报研究,采用机率扩散模型生成式AI,开发出SEEDS天气预报模型,可有效、大规模产生天气预报系集,成本还远低于传统物理预报模型。机率扩散模型是一种机器学习生成式AI技术,实作上可分为2步骤,一是添加杂讯,从原始资料逐步增加随机杂讯,直到资料完全变成随机杂讯。这个过程称为前向扩散,就像是在一张清晰的图片逐渐添加杂讯点,直到图片上满是随机杂讯。再来是移除杂讯,由机率扩散模型反向扩散,将充满杂讯的资料移除杂讯,最终恢复接近原始资料的新资料。
机率扩散模型中的机率性,就是在去杂讯的过程,每一步都考虑多种去杂讯的可能路径,这种作法,能生成多种且高品质的资料样本。这个能力,在天气预报的应用中,能生成一系列可能的天气状况,也就是系集预报,来反应未来天气的不确定性和多样性。最重要的是,与需要超级电脑耗费数小时运算的传统天气预测相比,SEEDS模型的计算成本几乎可忽略,在Google云端TPUv3-32执行个体上,每3分钟就能产生256个系集成员。(详全文)

Azure AI 微软 提示注入
微软推出Azure AI安全工具,防止恶意提示和AI幻觉
为防止Azure AI服务和模型,遭输入恶意指令产出有害内容、泄露个资等问题,微软最近发布多项工具,可侦测和防范恶意提示,也能防范AI幻觉、模型滥用等问题,目前已提供部份功能测试。
进一步来说,这些工具包括提示防护罩及AI模型幻觉侦测、系统范本、越狱评估工具和风险与安全监控。其中,提示防护罩能即时侦测、阻断基础模型接收到的恶意提示,另一个是真实性(Groundedness)侦测工具,能侦测文字结果的不真实内容,防范AI模型幻觉问题。另外,微软也将在Azure AI Studio和Azure OpenAI Service加入安全的系统讯息范本,让AI应用开发者能建立安全的系统讯息,导引模型使用训练资料和正确的行为。
另一个新工具则是自动化越狱评估,可侦测AI应用被越狱攻击、产出暴力、自残、色情、仇恨、歧视内容的可能性,也会以自然语言解释评估结果。最后,微软也提供AI应用风险与安全监控工具,能针对黑名单所封锁的产出内容,提供数量、严重性和内容类别,也能分析被标示为有害的用户输入讯息,并根据上下文讯号判断用户是否滥用。(详全文)
xAI Grok-1.5 X
xAI发表Grok-1.5
继于3月17日开源大型语言模型Grok-1后,xAI再于3月28日发表Grok-1.5,新版本将支援16倍的脉络长度,预计近期释出,并成为X上Grok聊天机器人的底层模型。xAI说明,Grok-1.5是在基于JAX、Rust和Kubernetes的客制化分散式训练框架上建置,能让团队轻松测试原型,同时大规模训练新架。这款客制化的训练协调器,可自动侦测有问题的节点,并从训练任务中剔除。为降低故障时的停机事件,团队也优化了检查点、资料载入和训练任务的重新启动机制。
与第一代相比,Grok-1.5有不少进展,在许多基准测试上直追或超越Claude 3 Sonnet和Claude 2,比如Grok-1.5在MMLU(大规模多工语言理解)基准测试的成绩为81.3%,超越Claude 2的75%与Claude 3 Sonnet的79%。此外,Grok-1.5也支援128K个Token的脉络,记忆能力为第一版的16倍,更擅长处理长文件。(详全文)
Nvidia MLPerf 生成式AI
Nvidia在MLPerf基准测试拿下2个最快
日前,MLCommons发布MLPerf Inference v4基准测试套件的最新结果,Nvidia一次拿下2个模型最快的冠军,包括资料中心类别的文生图模型Stable Diffusion XL和开源语言模型Llama 2 70B。这两个模型,都是这次测试新纳入的模型。
MLPerf Inference基准测试套件可分为资料中心和边缘系统两个类别,目的是要衡量硬体系统,在各种场景中执行AI模型的速度。就这次新添的模型来说,Llama 2 70B比MLPerf Inference v3.1所纳入的GPT-J模型,大了一个量级,是测试高阶系统的良好基准。而Stable Diffusion XL则有26亿参数,透过生成大量图像,能透过计算硬体系统的延迟和吞吐量等指标,来了解整体效能。而在边缘系统类别中,新增的Stable Diffusion XL模型测试则由Wiwynn系统拿下冠军。(详全文)
图片来源/Google、国科会、Opera
AI近期新闻
1. 微软研究团队发表AllHands,一种LLM大规模回馈分析框架
2. OpenAI将在东京开设新分部
资料来源:iThome整理,2024年4月