
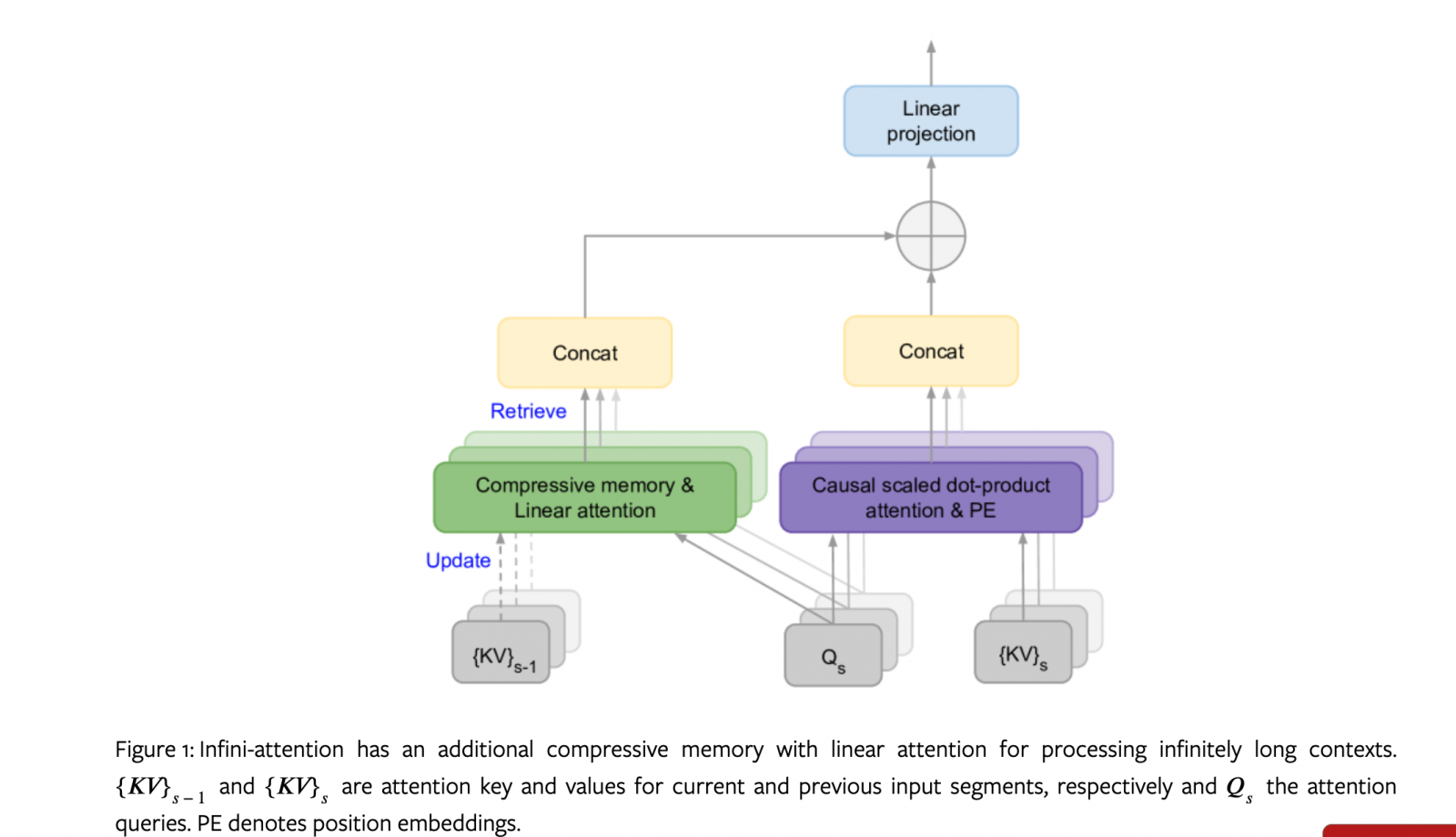
Google团队设计一种无限注意力机制,能将压缩的记忆纳入普通注意力机制中,并将遮罩的局部注意力和长期线性注意力机制,结合在单一个Transformer区块。
萤幕截图
重点新闻(0405~0411)
LLM Google 文长
Google一篇论文揭示LLM如何处理无限长文字输入
Google最近揭露一种Transformer大型语言模型(LLM)的新扩展方法,可利用有限的记忆体和运算资源,来处理无限长的文字输入。Google在《Leave No Context Behind》论文中说明这项新方法,他们设计一种无限注意力(Infini-attention)机制,将压缩的记忆纳入普通注意力机制中,并将遮罩的局部注意力和长期线性注意力机制,结合在单一个Transformer区块,能让模型具备完整的上下文知识。
这个无限注意力机制,可重复使用标准注意力的键、值和查询状态,来进行长期记忆整合与检索。有别于丢弃旧的键值(KV),无限注意力方法将旧键值储存在压缩的记忆体,并用注意力查询状态来检索值,以便处理之后的序列。这个修改Transformer注意力层的作法,能支援模型的连续预训练和微调,进而让LLM可以处理无限长度的文字。
经测试,使用这个方法的模型,在长文语言模型测试基准中,表现都比基准模型要好,甚至可实现114倍的理解率。他们也发现,10亿参数的LLM采用该方法,可将输入值长度扩展至100万个序列,还能实现密钥检索任务。最后,他们实验显示,采用无限注意力机制的80亿参数模型,在文长50万的书籍摘要任务中能达到SOTA表现。(详全文)
LLM 苹果 UI
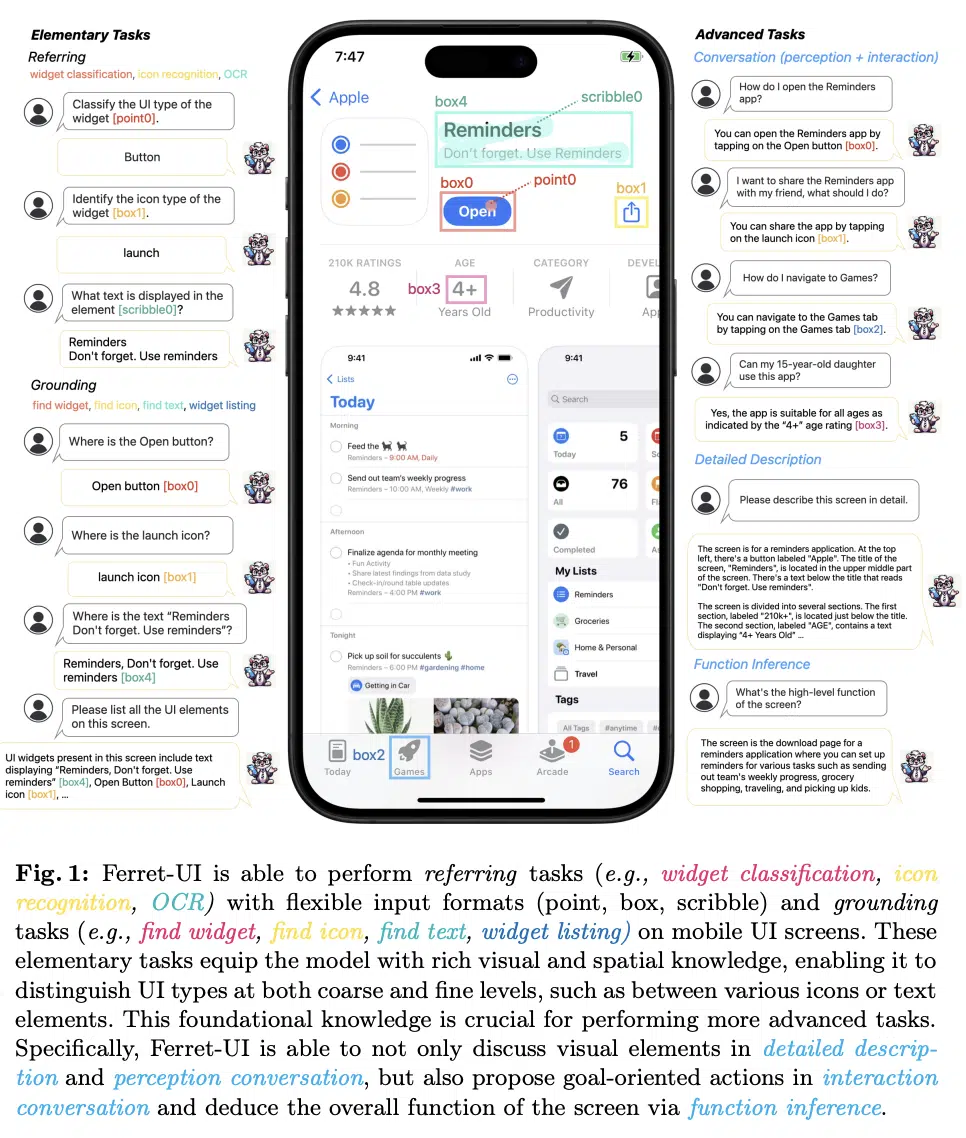
让LLM更懂萤幕内容!苹果揭新模型Ferret-UI
就在6月份的年度技术大会WWDC 2024前,苹果发表一项大型语言模型(LLM)最新研究成果,自建一套Ferret-UI大语言模型,更懂行动装置使用者介面(UI)的互动和细腻需求。苹果团队在论文中表示,虽然GPT-3这类LLM可执行多种任务,但仍难以理解UI互动,特别是行动装置领域。
这是因为,行动装置UI画面和自然图像很不一样,UI画面具有特定长宽比例,画面上的物件也较小,比如icon图示和文字,这些特性在自然图像上很难见到。为解决这些挑战,Ferret-UI采用了任意解析度的机制,能处理不同长宽比的萤幕,还能放大细节、增强提取的视觉特征。Ferret-UI接著对每个子图像分别编码,来避免丢失关键的视觉资讯。
此外,Ferret-UI还采用一种新的资料管理方法,从各种UI任务中收集训练样本,这些任务包括图示辨识、寻找文字和小工具列表。这些任务让Ferret-UI学会认识UI元素的语义和空间定位,因此能进行更广泛的任务。除了基础任务,Ferret-UI也进行特定任务训练,如生成详细描述、感知对话理解和功能推理。为评估Ferret-UI,团队还建立一个涵盖各种UI任务的基准测试,与其他开源LLM和GPT-4V相比,Ferret-UI表现更好,尤其是在基础UI任务和高阶推理能力上。若苹果将Ferret UI整合到智慧助理Siri中,可实现无缝的应用程式整合、推进自然语言导航等。(详全文)
Gemini Google 生成式AI
Google生成式AI助理Gemini for Google Cloud正式亮相
在本周举行的Google Cloud Next '24上,Google正式发表Gemini for Google Cloud,是一款以大型语言模型Gemini驱动的生成式AI助理,按不同功能分为不同助理,包括Gemini Code Assist、Gemini Cloud Assist、Gemini in Security Operations、Gemini in BigQuery、Gemini in Looker和Gemini in Databases等。Google将Gemini打造成统一的AI品牌,不只于今年2月将聊天机器人Bard更名为Gemini,还以Gemini品牌全面取代先前发表的AI助理Duet AI。
其中,Gemini Code Assist是先前的Duet AI for Developers,可协助开发者在VS Code和JetBrains等热门程式编辑器中建置应用程式。Gemini Cloud Assist则是应用程式生命周期管理工具,能提供有关应用程式的设计、部署、管理和排除故障的个人化建议。Gemini in Security Operations则是继承Duet AI in Security Operations,新版已将Gemini整合至Chronicle安全营运平台,能更轻松侦测、调查与回应威胁。
Gemini in BigQuery可协助资料工程师和分析师,用自然语言从海量资料中分析或找出有价值的资讯。Gemini in Looker则是商业智慧工具,可以聊天方式与资料库对话,或用来建立图表和报告。Gemini in Databases则让Database Studio具备生成、摘录SQL的能力,也允许使用者从Database Center中管理所有资料库或资料库迁移。(详全文)
生成式AI 外挂 Google Workspace
Google Workspace新添多种生成式AI外挂
Google Workspace是生产力工具,现有30多亿名用户和1,000多万名付费用户。去年Google大举投入AI,也为Workspace的Gmail、Docs、Sheets等应用内建Gemini。这次在今年度Next'24开发者大会上,Google宣布新添更多AI加持的应用,如Google Vids是款商务AI影片制作App,可制作行销、客服或业务训练等影片,还能协助用户配音。Vids预计今年6月提供Workspace Labs更多人测试,之后由Gemini for Google Workspace方案开放订阅。
再来,Google Workspace也加入AI会议与讯息、AI安全等2项付费AI外挂功能。AI会议和讯息外挂可用于Meet用户会议,像是专业摄影棚等级的摄影、打灯、音效、预览版的「会议笔记」、聊天重点摘要和即时翻译字幕功能。AI安全外挂可自动为公司Google Drive上的档案与文件自动分类和加入防护,Google表示,该功能是以企业组织独有资料训练出AI模型后,用这些模型持续侦测和评估Drive的现有与新档案。AI会议和讯息、以及AI安全收费皆为每人每月10美元。(详全文)
LLM 联发科 生成式AI
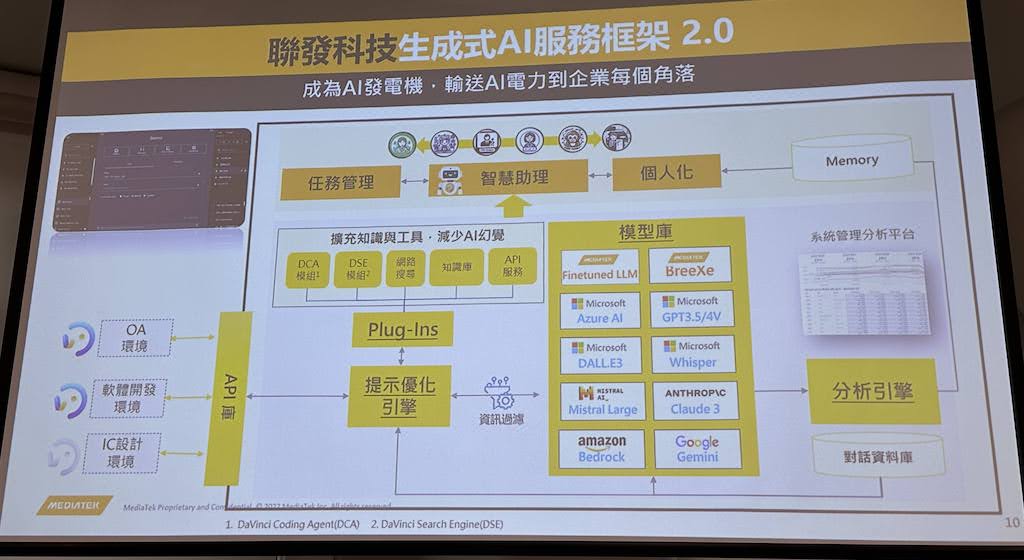
联发科推出生成式AI服务平台、最新繁中LLM
联发科技日前一口气发表生成式AI服务平台MediaTek DaVinci(又称达哥)和繁中大型语言模型MR BreeXe。首先,达哥最初是为集团内部开发,目的是要提高生产力,平台内建API库、提示优化引擎、扩充外挂库、模型库和分析引擎等重要元件。其中,外挂库可用来扩充生成式AI模型知识、减少AI幻觉,模型库则包含常见的大型语言模型(LLM),如Google Gemini、GPT-3.5/4V、Whisper、Claude 3和AWS Bedrock服务等,联发科技自己最新打造的模型BreeXe也纳入其中。
今年,联发科技优化该平台,新添智慧助理架构,能让使用者不必写任何程式码,就能打造自己的智能秘书。这个版本的平台就是达哥2.0,还具备4个主要商店,包括AI模型、扩充外挂、提示范本、知识库(DVCs)等,另也配备许多功能,包括DocChat、VideoChat、WebChat和Plug-ins。另一方面,这次揭露的繁中模型MR BreeXe是以Mixtral 8x7B模型为基础,以大量繁中资料预训练而成,在繁体中文基准测试TMMLU+和MT Bench TW上超越GPT-3.5。该模型也对台湾常见的地端应用特别优化,要提高产业界使用生成式AI和检索增强生成(RAG)的体验。使用者可透过达哥平台使用MR BreeXe,它还支援全地端与部分地端场景,也能依需求进行少样本学习和微调客制化。(详全文)
LLM Mistral AI Mixtral 8x22B
Mistral AI开源1,760亿参数模型Mixtral 8x22B
去年4月才成立的AI业者Mistral AI最近就释出新版的开源模型Mixtral 8x22B,采稀疏混合专家(SMoE)架构、支援1,760亿个参数和6.5万个Token的脉络长度,已由Mistral AI的官方X帐号、Together API和Hugging Face发布,成为目前最大的开源模型之一。
迄今Mistral AI已释出3款开源模型,包括去年9月发表的Mistral 7B(Mistral-tiny),去年12月发表的Mixtral 8x7B(Mistral-small)和这次推出的Mixtral 8x22B,它们皆采Apache 2.0授权,允许开发者免费下载,并在自己的设备或伺服器上执行。Mixtral 8x22B的基准测试表现不错,在大规模多工语言理解MMLU的成绩为77.3,胜过前一代Mixtral 8x7B的71.88,也超越GPT-3.5、Claude 3低阶版Haiku、Gemini 1.0 Pro,但仍不及GPT-4和Claude 3 Sonet/Opus。在基础常识推论HellaSwag测试中,Mixtral 8x22B得分为88.9,仅不及GPT-4、Claude 3 Sonet/Opus和Gemini 1.5 Pro;但它在GSM8K数学测试中的得分为76.5,明显不及GPT-4、Claude 3和Gemini的各种模型。不过,使用者可下载微调模型,打造为适合自己任务需求的模型。(详全文)
GPT-4 Turbo with Vision 视觉 OpenAI
OpenAI GPT-4 Turbo with Vision上线
OpenAI最近加入视觉能力的基础模型GPT-4 Turbo with Vision已正式上线,供付费用户存取。现在,付费客户可透过API存取,也能用JSON模式或函式呼叫方式发出请求。
GPT-4 Turbo with Vision是OpenAI的大型多模态模型,整合自然语言处理和视觉理解能力,可分析用户上传的图片并以文字回应。最新模型和GPT-4 Turbo同样具有128K个Token脉络,且训练资料已更新到2023年12月。GPT-4 Turbo with Vision去年12月已先行整合到微软Azure AI服务。(详全文)
OpenAI 模型微调 延迟
OpenAI扩大AI模型微调功能
日前,OpenAI公布AI模型微调功能,让企业或开发者自行微调AI模型,同时也提供企业辅助微调或从头打造AI模型的服务。进一步来说,OpenAI在去年8月就推出GPT-3.5模型的微调API,已有数千家企业和开发商用来训练上万个模型。这个微调API不只能让模型更理解训练内容,还比普通ChatGPT单一提示支援更多范例,可提高回应结果品质,同时降低成本与延迟性。
在这个基础上,OpenAI再增加微调功能,包括周期(epoch-based)为基础检查点,减少过度拟合必须再训练的困扰;比较性Playground UI,可同时比较多个模型输出结果,或检视在单一提示下的微调效果;整合第三方平台,第一批包括Weights和Bias,方便开发者将微调的资料分享到其他软体;大量参数配置,允许从Dashboard设定,以及微调能力的改善,支援输入超大量参数、检视详细训练量测值等。若企业需要帮忙微调,OpenAI也推出自订模型方案,由一组OpenAI技术人员协助企业训练与优化特定领域的模型。(详全文)

图片来源/Google、苹果、OpenAI
摄影/王若朴
AI近期新闻
1. Meta揭露最新一代AI晶片MTIA
2. 吴恩达开设LLM非结构化资料处理课程
3. Google新推2款Gemma系列模型,分别用于程式开发和研究
资料来源:iThome整理,2024年4月