
本文来自微信公众号:新硅NewGeek(ID:XinguiNewgeek),作者:董道力,编辑:张泽一,视觉设计:疏睿,题图来自:视觉中国
文章介绍了大模型价格战的最新动态,包括各大AI公司的降价策略,以及对于降价不降价的看法。同时探讨了大模型的定价方式和可能的同质化竞争问题。• 💰 大模型价格战正式开打,各大AI公司相继降价,引发行业关注
• 🤖 大模型定价方式深度解析,讲述Tokens的计费单位和对应成本
• 🚀 技术角度分析大模型降价原因及同质化竞争可能影响,展望行业未来发展
作为一个普通消费者,硅基君最喜欢看价格战了。
谁不喜欢一块钱打车,九毛九的黄焖鸡外卖?哪像现在薅点平台羊毛,还得到各个微信群里拉下老脸跪求兄弟姐妹们点一下。
这会,虽然和咱们日常生活有点远,大模型的价格战这两天算正式开打了。
自从上星期字节在发布会上喊出“豆包主力模型的定价比行业便宜了99.3%”。这事就和莱克星顿的枪声一样一发不可收拾,有头有脸的AI公司全都跳出来高喊:俺也一样!
截至发稿,喊出降价的大模型包括智谱、腾讯、阿里、百度、科大讯飞。
唯独有位清流,零一万物的李开复博士说:“目前不打算降低YI系列模型的API价格。”并认为目前零一万物给的性能、性价比都很高了。
这话要咱说多少有点不厚道,总不能那么多降价的大模型都是性能不够价格来凑?
对于大模型价格战这事,李开复博士还说了:“就像特斯拉,不会因为别的牌子车比它卖得便宜,它也要来降价。”
且不提特斯拉这些年调了多少次价,维权的车主拉了多少群,就零一万物行业地位对标特斯拉这事,咱要不还是再想想?
咱们先简单说说大模型的价格到底是什么。
通常来说,AI公司训练出自己的闭源大模型(开源当然不用花钱买)后,会出售给其它想用的个人或者公司。
相较于过去的出售软件,比如WPS或者Office这种一次买断制付费,大模型则是在使用过程中,按使用量收费。
这种收费方式和电信运营商的“流量包”类似,计费单位则从流量的MB和GB,变成了Tokens。
流量分上传和下载两部分,大模型也有输入和输出两个环节,不过不同于流量上传下载是同一个价格,大模型由于输出的过程有一个“推理”的环节,所以通常价格会比输入更高。
同样也是由于推理这一过程,性能更强的模型处理每Token的成本也就越高,因此模型越大,通常定价越贵。
1Token到底等于多少个汉字,会根据模型处理文字方式不同有所改变,有兴趣测试一下的可以到OpenAI这个页面试试:
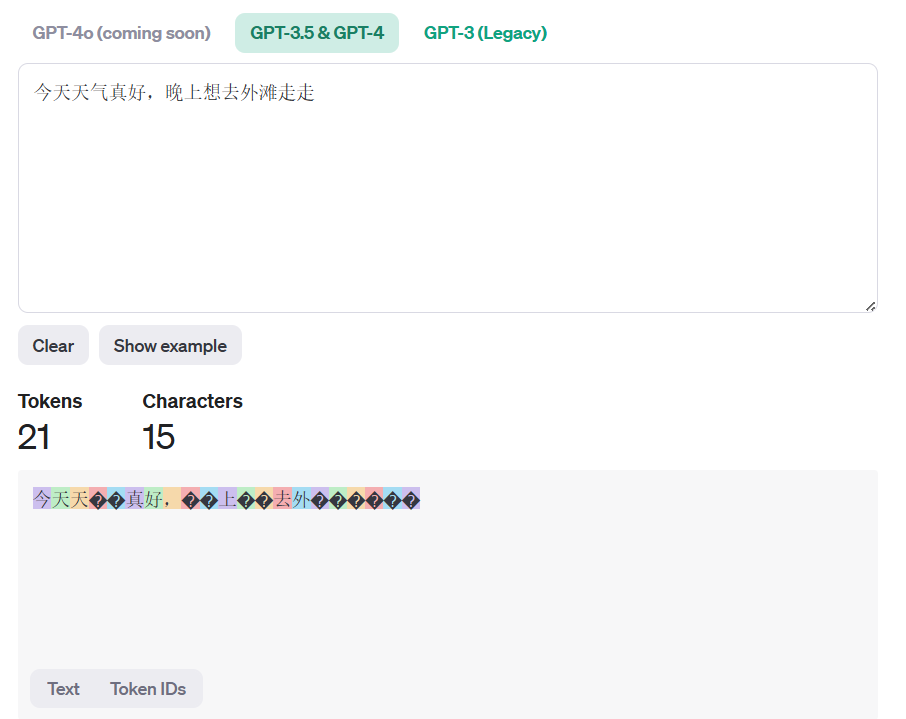
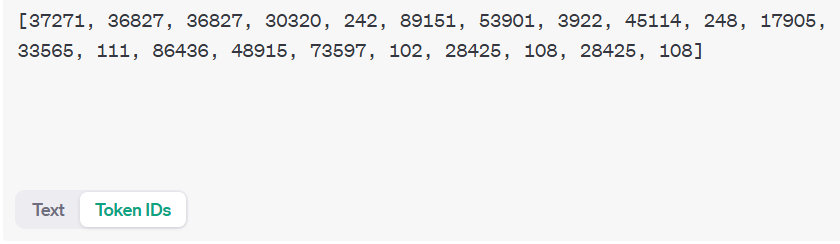
了解这些基本信息后,我们再来看看大家是怎么打价格战的。
智谱AI最早加入战局,早在5月11日宣布大幅降价,新注册用户获得的额度从500万tokens提升至2500万tokens,GLM-3 Turbo模型中,用户1元可以买100万tokens。
字节跳动在15号发布会上,宣布降价,相当于1元可以买125万的豆包pro32k模型tokens。
5月21日,阿里也降低了大模型价格,通义千问GPT-4级主力模型Qwen-Long,API输入价1元可以买200万tokens。
而百度随后出招,直接宣布文心大模型两大主力模型全面免费,立即生效。
看看这几家的操作,火药味非常浓了。
而且,百度怕不是忘了自己说过的话了:5月15日,百度曾发布公告称“使用大模型不应该只看价格,更要看综合效果”,还强调“闭源大模型+公有云”比“开源大模型”性能更好、成本更低。
然后,今天下午,讯飞宣布星火Lite API永久免费开放,星火Pro/Max API低至0.21元/万tokens。
今天傍晚,腾讯混元大模型也宣布全面降价,lite版免费。
这些降价公告小数点实在太多,咱们统一换算一下,看看各家一元能买多少万tokens。
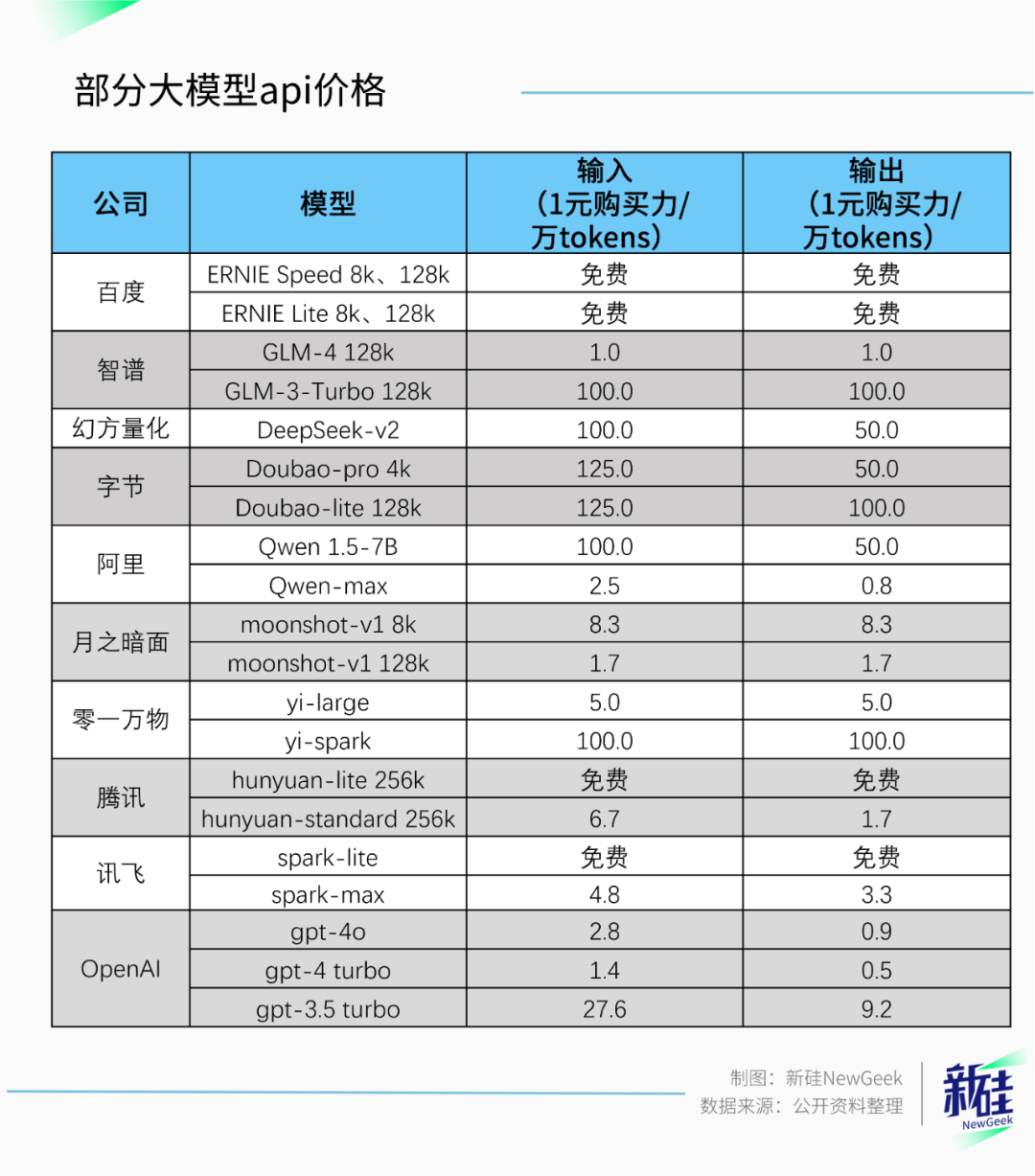
不管怎么说,便宜的大模型对于用户和开发者而言肯定是个好事,对于平常就正常用用大模型的普通人来说,这价格到底多少可能没什么意义。
对于AI应用开发者来说,Tokens的价格就是压在他们身上最沉重的成本大山。
几个月前有个叫哄哄模拟器的应用一夜爆火,用户在开发者意料之外疯狂涌入,据网传截图称“一早上就两千美金了。”
自掏腰包哪里扛得住这样烧钱?
至于各家公司会因此烧掉多少钱,想来抢市场阶段大家也不在意。
不过咱们可以看看从技术角度是如何实现降低模型调用价格的。
其实最早大幅度降价的,是著名量化私募,幻方旗下的AI公司Deepseek,他们在5月初就宣布降价,1元能买1百万输入Tokens。并且在一篇论文中详述了自己是如何降低大模型训练成本的,感兴趣的读者可以自行去品一下。
还有一种观点,就是大模型之所以会打价格战,是因为陷入了同质化竞争。
诚然,外卖、快递、网约车、社区团购甚至如今的新能源车等价格战火热的行业,或多或少都是同质化竞争导致的,大模型也可能是当前卷性能带来的收益越来越低。
在《LLMs正达到收益递减的证据——及其可能意味着什么》一文中,作者提到“大模型在性能提升方面可能已达到收益递减的临界点”。
作者以OpenAI为例,认为:“从GPT-2到GPT-3的巨大飞跃。从GPT-3到GPT-4的巨大飞跃......GPT-4到GPT-4 Turbo就没有那么多了。”
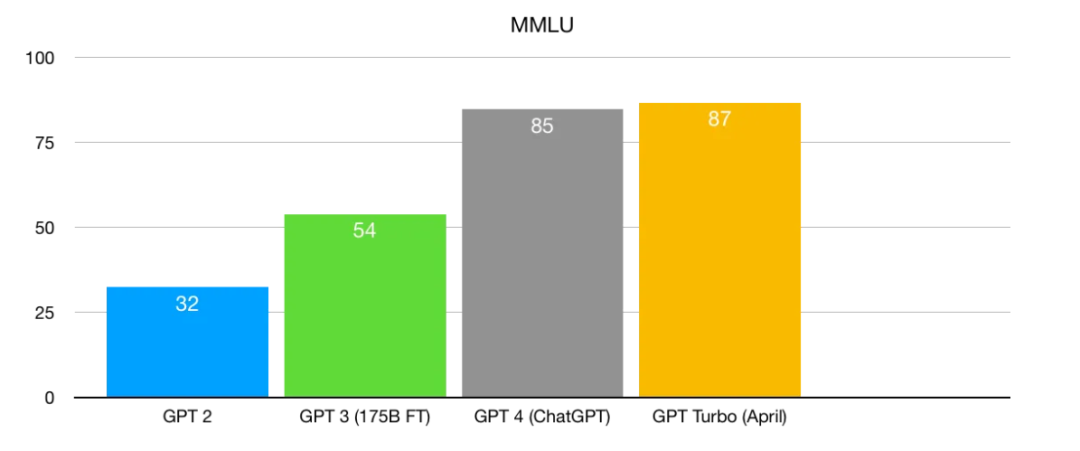
假设大模型的性能发展真的要迎来一面墙,对于大模型公司来说,如何抢下用户是现阶段最重要的一步。
这活大家熟得很,阿里百度字节腾讯,哪个不是从抢用户的血水里走出来的。
正如彭博分析师指出的那样:“中国在AI盈利方面将面临着漫长的道路,行业洗牌可能会推动该行业盈利。”
表面上是在说中国的大模型价格战会推动行业洗牌,是个好事,但他后面还补了一句:“尽管在一个资本过剩的行业中,这种情况似乎不太可能很快发生。”
本文来自微信公众号:新硅NewGeek(ID:XinguiNewgeek),作者:董道力,编辑:张泽一,视觉设计:疏睿