如果你愿意花时间,还真能从零开始构建一个LLM,得感谢互联网的开源精神,前OpenAI的大神Andrej Karpathy无私的开源了从零开始构建GPT2的代码以及教学视频。
必要的学习材料
第一就是这个Github库,叫build-naogpt。
再加上这个配套的教学视频,基本上就能把GPT2重新构建出来。
后来的GPT3,3.5,4其实都是在GPT2的原型下做出来的,只不过后来采用了更多的参数以及更多优质的数据。
上面的Github库+教学视频是最基础的材料,其次你还得学习理论知识。
基本的数学知识(加*是必学的)
- *线性代数:理解向量和矩阵运算,这是神经网络的基础。包括矩阵乘法、点积和矩阵变换等。
- *概率与统计:用于理解模型的概率输出(如softmax函数)和损失函数(如交叉熵)。
- *微积分:理解梯度下降优化算法,包括梯度的计算和反向传播(backpropagation)。
- 基础代数:基本的算术运算和代数变换,用于公式推导和代码实现。
- 数值分析:理解数值稳定性和误差分析,特别是在混合精度训练(float16)中。
线性代数和概率统计会被大量的用到,因为说白了大模型也就是一个巨大的概率模型,这两个有时间的话最好是系统性的学习一下,否则矩阵操作你根本想象不出来,会极大的增加你的理解成本。
知识点作用高等数学机器学习公式推导必备线性代数算法求解必备概率论机器学习必备对于前三个,高数、线代和概率论,我推荐两个课,一个是deeplearningai,也就是吴恩达创建的网站推出的课程。
推荐的理由它就是针对于AI初学者开的课,一下子把这三门全都覆盖了。

当然了,每一个方向都有非常精品的课程。
线代:MIT的18.06 Linear Algebra 【https://web.mit.edu/18.06/www/】,这个无数人强推了。
github也开源了。
高数:国内国外的精品课程都很多,自己可以去B站或者油管找,我这里推荐一个「Essence of calculus」,是由国外大神「3Blue1Brown」制作的视频教程。
推荐的理由是做机器学习的高数就不需要做题了,反而是掌握它的基本原理和实际应用更为重要。
概率论:基本上理科生和工科生都上过,但是对于它的理解和掌握程度我自己觉得永远都不够,而它又是如此重要,机器学习中的很多算法都直接跟它相关。我建议英文不错的同学看一下MIT的这个课「Probabilistic Systems Analysis And Applied Probability」,完全开源免费的,教材、课件、视频等等一应俱全。
另一个就是我经常看到有人推荐的「陈希孺」版本的概率论与数理统计,B站有依据这本书作为教材的讲解视频。
【完结】中国科学技术大学精品课程:概率论与数理统计_哔哩哔哩_bilibili必要的编程知识 - Python
现在最主流的用于机器学习和人工智能的编程语言是Python,所以我非常建议非计算机专业的同学先学Python。
主要原因有两点,其一是Python语言实现起来比较容易,Python语言当中有大量的库可以直接使用,这会在很大程度上方便人工智能的开发,比如Torch、Scipy、Numpy等库;其二是Python语言本身能够完成落地应用,生态环境比较健全。
虽然ChatGPT可以帮你写代码,但是基本的python编程还是得学的,毕竟ChatGPT写的代码也有不少的bug,你起码得知道bug该怎么改。
而这部分你要学的内容没有很多,随便一个python在线课程都可以,我推荐一个免费的网站https://www.w3schools.com/python/default.asp
你学到对象/类这里就可以了,记住如果碰到理解不了的,直接把问题抛给ChatGPT帮你解答。
在学习过程中你会学习数据结构、逻辑判断以及面向对象编程等等,不然的话你理解不能这些代码。

必须掌握的理论知识- Attention机制
说白了就是这篇论文《Attention Is All You Need》,它是大模型实现的最重要的理论部分。

特别是GPT的全称就叫Generative Pre-trained Transformer,而attention就是Transformer结构中的非常重要的一个组成部分。
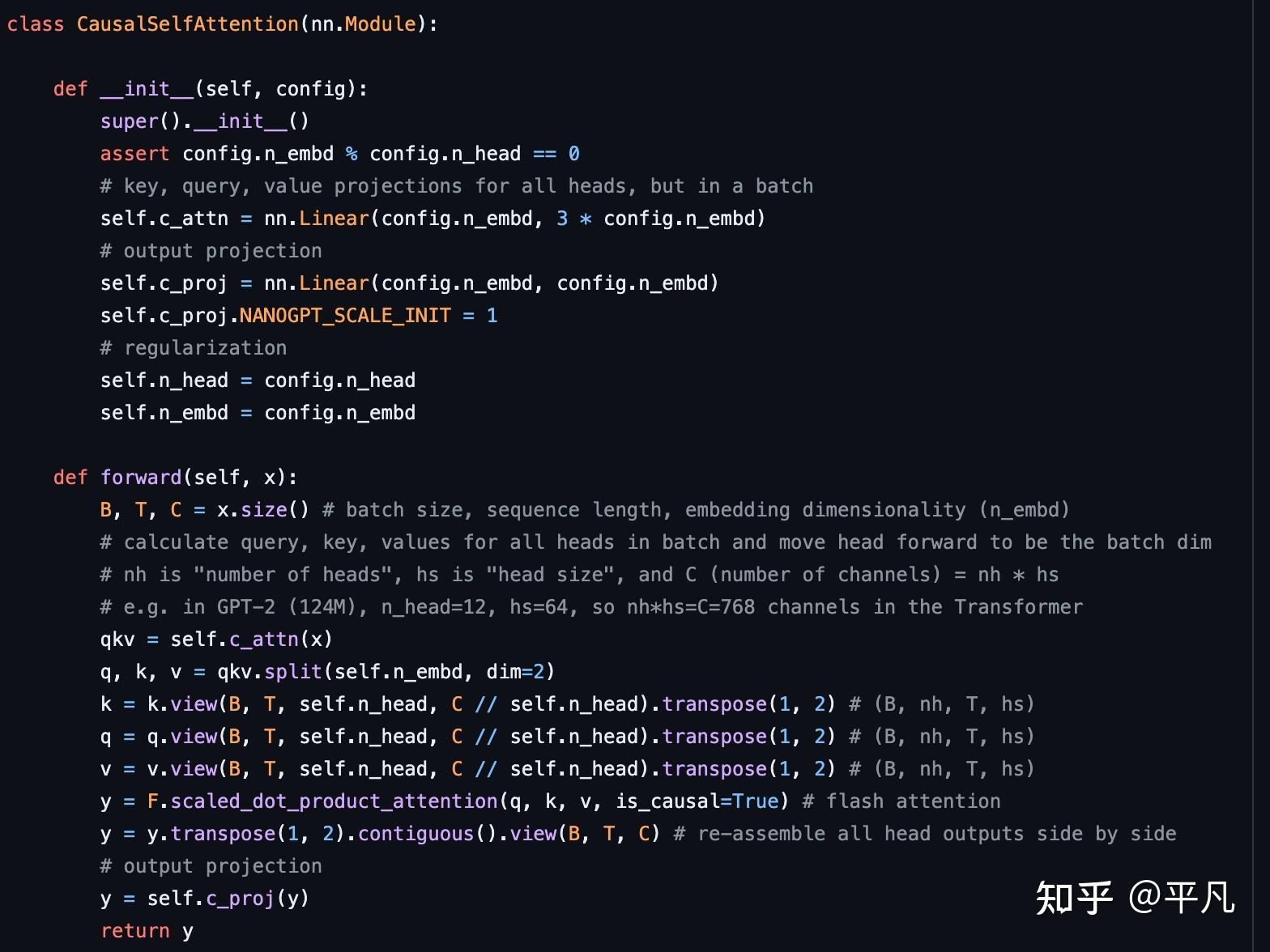
它对应了build-nanogpt库的第一部分,就是构建一个CausalSelfAttention的类,这里面就是上面那篇论文的一个现实的例子,你要是不懂就看不懂这个代码。
代码部分-粗看
你掌握了上述这些东西的话,然后就可以跟着视频一行行的看代码了。
简单来看一下这个库的代码,第一部分就是这几个类,
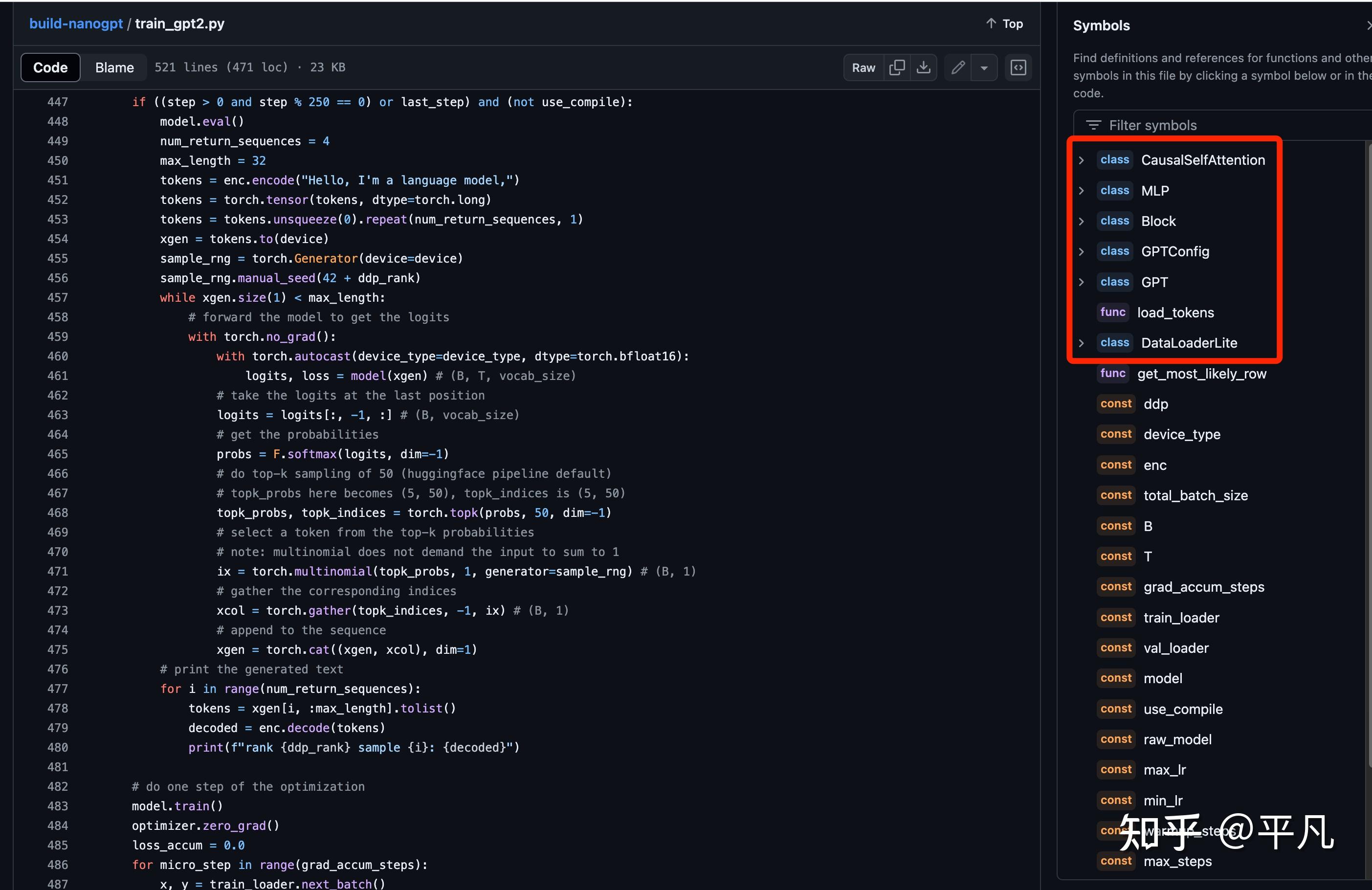 类名/Class作用学习资料CausalSelfAttention这是一个自注意力机制的实现,用于计算输入序列中每个位置的注意力权重,确保当前位置只关注之前的位置(因果自注意力)。https://github.com/EvilPsyCHo/Attention-PyTorch?tab=readme-ov-fileMLP-多层感知机神经网络结构,用于处理从注意力机制输出的数据https://github.com/Syndrome777/DeepLearningTutorial/blob/master/3_Multilayer_Perceptron_%E5%A4%9A%E5%B1%82%E6%84%9F%E7%9F%A5%E6%9C%BA.mdBlock一个Transformer模块,包括一个自注意力层和一个MLP层,并且使用层归一化。这个其实就是普通的pytorch构建模块,学一下pytorch就行了,其实就是堆积木,一层层的堆起来,保证当前蹭输出的维度=下一层输入的维度GPTConfig这个类定义了GPT模型的配置参数,如最大序列长度、词汇表大小、层数、头数和嵌入维度这个看大神的视频讲解就行GPT这个是构建GPT的主要模块依旧看大神视频DataLoaderLite输入加载模块,用于加载和预处理训练和验证数据这一块其实没有什么特别需要注意的,学习一下提供的代码就行
类名/Class作用学习资料CausalSelfAttention这是一个自注意力机制的实现,用于计算输入序列中每个位置的注意力权重,确保当前位置只关注之前的位置(因果自注意力)。https://github.com/EvilPsyCHo/Attention-PyTorch?tab=readme-ov-fileMLP-多层感知机神经网络结构,用于处理从注意力机制输出的数据https://github.com/Syndrome777/DeepLearningTutorial/blob/master/3_Multilayer_Perceptron_%E5%A4%9A%E5%B1%82%E6%84%9F%E7%9F%A5%E6%9C%BA.mdBlock一个Transformer模块,包括一个自注意力层和一个MLP层,并且使用层归一化。这个其实就是普通的pytorch构建模块,学一下pytorch就行了,其实就是堆积木,一层层的堆起来,保证当前蹭输出的维度=下一层输入的维度GPTConfig这个类定义了GPT模型的配置参数,如最大序列长度、词汇表大小、层数、头数和嵌入维度这个看大神的视频讲解就行GPT这个是构建GPT的主要模块依旧看大神视频DataLoaderLite输入加载模块,用于加载和预处理训练和验证数据这一块其实没有什么特别需要注意的,学习一下提供的代码就行剩下的部分就是分布式训练,因为及时是GPT2模型,训练起来依旧需要不短的时间,这个大神用的是云计算资源来训练,这一块最好是跟着视频一步步的学。
视频中4个小时就构建完了,但实际上需要几十倍的时间,不过好在有代码有视频,所以还是能够学会的。