演讲嘉宾 | 刘育良 AI 平台大模型训练负责人审核|傅宇琪 褚杏娟策划 | 蔡芳芳
快手总结了一套超大规模集群下大语言模型训练方案。该方案在超长文本场景下,在不改变模型表现的情况下,训练效率相较 SOTA 开源方案,有显著的吞吐提升。通过细致的建模,可保证 Performance Model 十分接近真实性能,基于此 Performance Model,解决了大模型训练调参困难的问题。
本文整理自快手 AI 平台大模型训练负责人刘育良在 QCon 2024 北京"的分享“ 超大规模集群下大语言模型训练的最佳实践”。演讲结合在快手超算集群上的大模型训练经验,阐述大模型训练在超大规模集群下遇到的挑战和热点问题的演变,以及对应的解决方案。同时,针对最具挑战的超长文本场景,进行案例分析。最后,根据未来大模型的发展趋势,对训练领域的技术探索方向进行探讨。
本文由 InfoQ 整理,经刘育良老师授权发布。以下为演讲实录。
简单介绍一下背景,下图清晰地描述从过去到现在,即 23 年之前所有主流大模型的发展历程。从技术架构的角度来看,Transformer 架构无疑是当前大模型领域最主流的算法架构。其中包括以 Bert DIT 为代表的 Encoder-Only 结构,以 T5 为代表的 Encoder-Decoder 结构,以及现在非常火热的 GPT 系列的 Decoder-Only 结构,这也正是我今天想要讨论的重点。
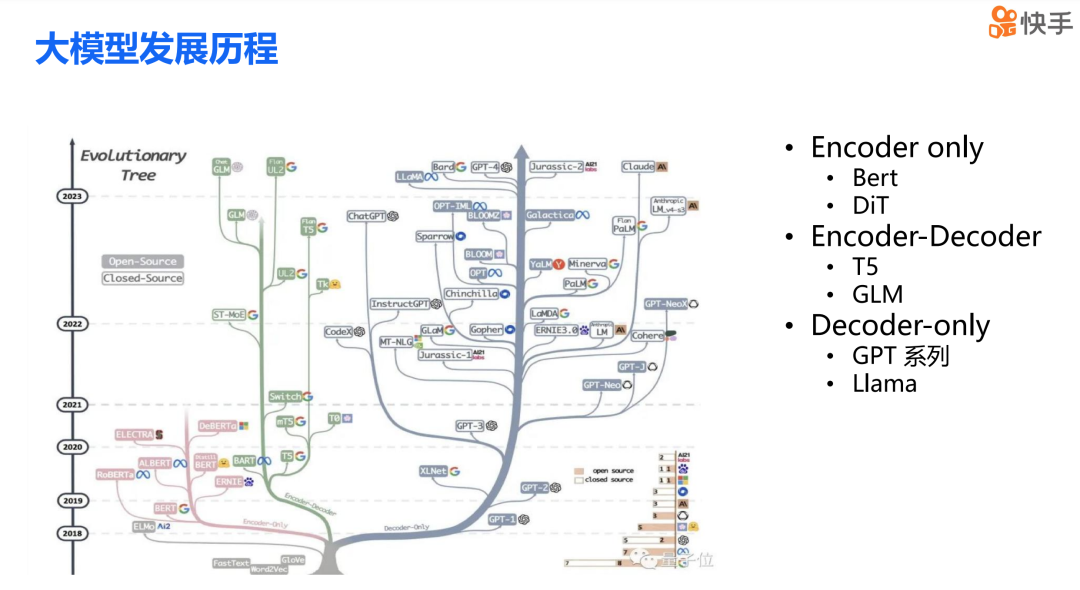
大模型这个名字非常直观地表达了其主要特点,那就是“大”。具体量化来说,参数数量大,比如从 LLAMA2 的 70B 到 GPT-3 的 175B,再到 GPT Moe 的 1.8T。其次,数据量大,我们训练一个大模型通常需要达到 T 级别 tokens 的数据量。再者,由于模型尺寸巨大和数据量庞大,随之带来的是巨大的计算量,基本上现在表现良好的大模型都需要 1e24 Flops 级别以上的计算量。
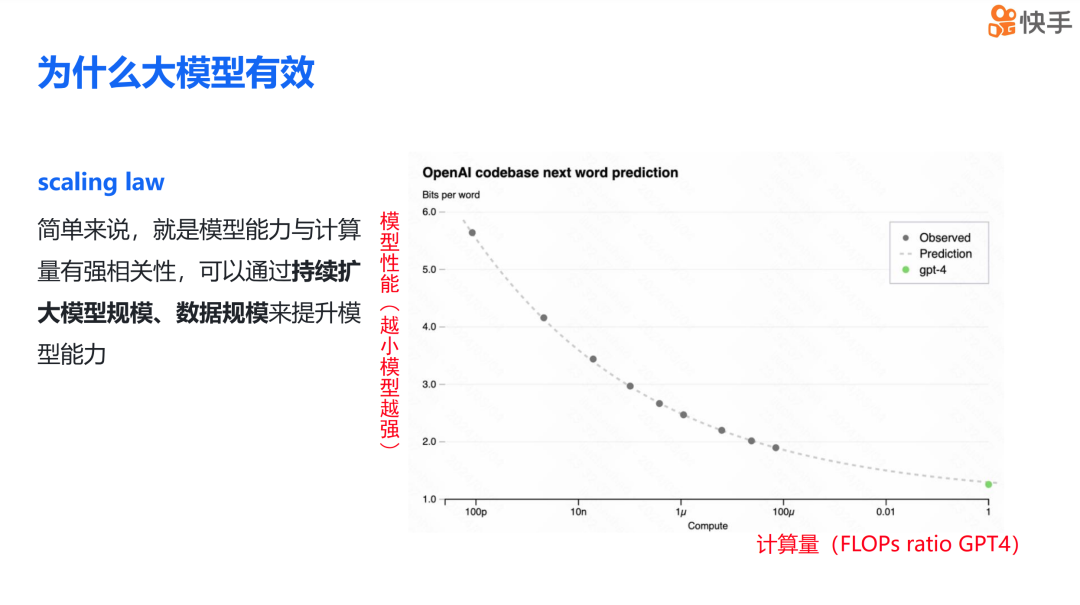
那我们为什么需要将模型扩展到如此规模?或者说,为什么模型越大效果越好呢?大模型持续扩大规模会变强的理论基础是 scaling law。接下来展示的这张图来自 OpenAI GPT-4 的技术报告,scaling law 简单来说就是模型的能力与计算量有强烈的正相关性。因此,我们可以通过不断增加模型规模和数据规模来提升模型的能力。
接下来,我想和大家探讨一下训练引擎的定位,用一句话来概括就是“工欲善其事,必先利其器”。
首先要做的是提供一套可持续扩展的工具箱,这样就可以不断扩展模型规模、数据规模和序列长度,从而提升模型的表现。其次,我们要提高扩展效率,即提高 scaling efficiency。如果将刚才提到的 scaling law 的横轴从计算量换成计算卡时,那么我们的目标就是通过提高训练效率来减少总体的训练时间,进而增加 scaling law 的斜率。
作为大模型算法解决方案的提供方,我们要与算法进行联合优化,从训练和推理效率出发,提出模型结构的建议。同时,作为超算集群的使用方,我们需要根据大模型的典型通信模式和计算模式,提供组网策略和服务器选型的建议。
接下来,我想介绍一个衡量训练方案好坏的指标,即 MFU。MFU 的计算公式是有效计算量除以训练时间再除以理论算力。这里提到的 MFU 计算公式与之前论文发表的有所不同,原因在于当前主流的大语言模型都采用了 causal mask。对于特定的模型和特定的集群,有效计算量和理论算力都是恒定的,因此我们的目标是通过减少训练时间来提升 MFU。
为了提升 MFU,我们能做的主要有三点:
减少无效的计算,这通常来自于重计算;提高集群稳定性,减少因稳定性问题导致的集群不可用时长;减少通信的影响,这将是接下来讨论的核心内容。

分布式训练的主要难点
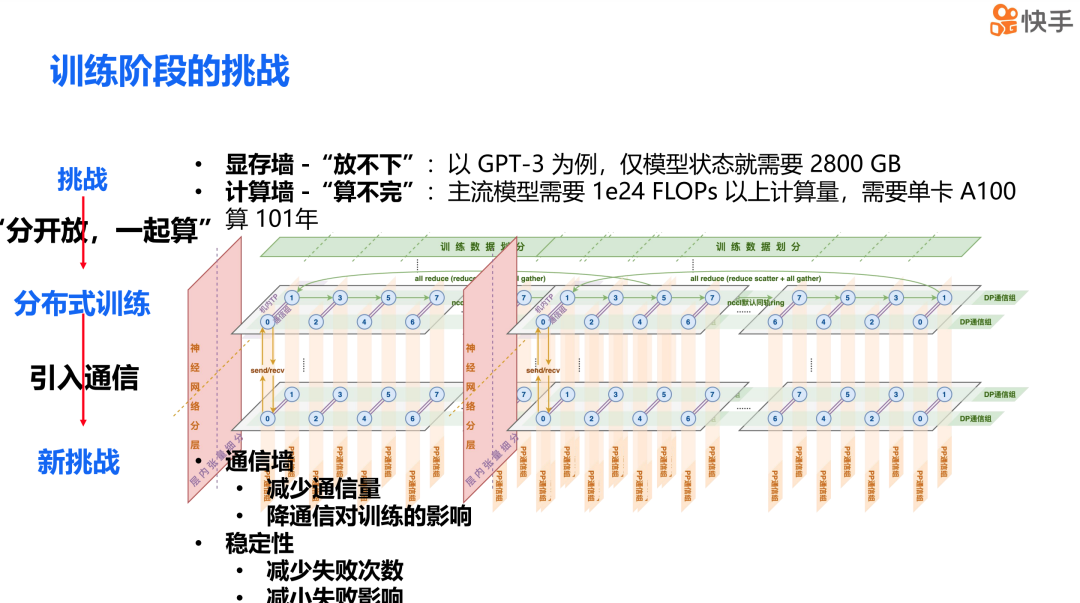
与小模型相比,大模型的挑战可以概括为“放不下和算不完”。以 GPT-3 为例,单是模型就需要 2,800 GB 的存储空间。而且,主流模型的计算量之大,以至于如果使用单张 A100 显卡,需要计算 101 年才能完成,这显然是不切实际的。
我们的解决方案是直接的,即通过混合并行的方式来实现分开放和一起算。具体来说,我们把模型状态和中间激活值分散在整个集群上,然后通过必要的通信来完成联合训练。但混合并行也带来了问题,它引入了大量的通信,这导致训练效率急剧下降。因此,在大模型训练中,我们可能需要做的工作主要集中在两个方面:第一,减少通信量;第二,降低通信对计算和训练的影响。这两项工作对于提升大模型训练的效率至关重要。
简单介绍一下混合并行中经典的三种并行方案。首先是数据并行,简称 DP。正如其名,数据并行是将数据分割到不同的计算设备上,然后由这些设备完成各自的计算任务。第二种是张量并行,简称 TP。张量并行是将模型中某些层的参数分散到不同的设备上,每个设备负责完成部分的计算工作。第三种是流水并行,简称 PP。流水并行是将模型的不同层切分到不同的计算设备上,类似于流水线的工作方式,各个设备协同完成整个模型的计算过程。

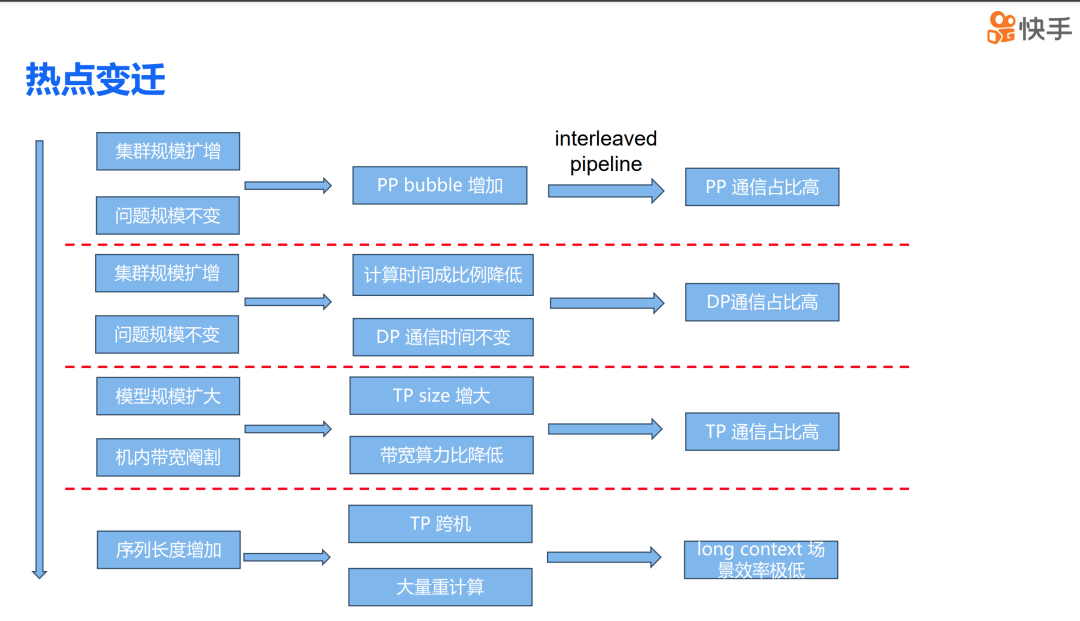
现在我来分享一下在实际操作中,训练大模型时遇到的一些热点问题的演变。
首先,随着集群规模的扩大,即 GPU 数量的增加,而问题规模,也就是模型的大小保持不变,这导致了 PP Bubble 急剧增加。为了解决这个问题,我们引入了 interleaved pipe。然而,这种方法也带来了另一个问题,即 PP 的通信量成倍增加。集群规模的扩大同时也导致单个 iteration 的计算量成比例下降,但 DP 的通信时间与参数量成正比,所以通信时间实际上并没有减少,这导致 DP 的通信开销持续扩大。
随着我们从 66b 模型扩展到 175b,再到更大的模型规模,我们需要将 TP 的尺寸从 2 增加到 8,这导致了 TP 的通信量大幅增加。同时,由于 A800 和 H800 集群内部的 Nvlink 被阉割,这在千亿参数模型训练时,TP 的通信开销实际上超过了 30%。最后,随着 context window size 的扩大变得越来越重要,序列长度的增加,原有的方案要么需要进行 TP 跨机操作,要么会引入大量的重计算。这导致在 long context 场景下,原有的训练方案的效率极低。
大模型训练在超大规模集群下的挑战与解决方案
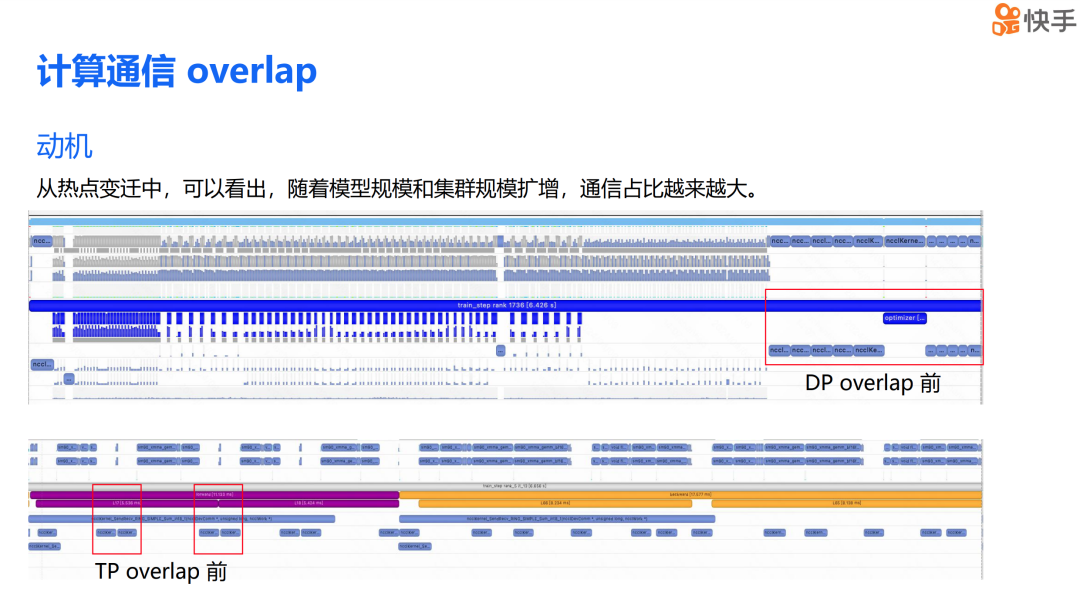
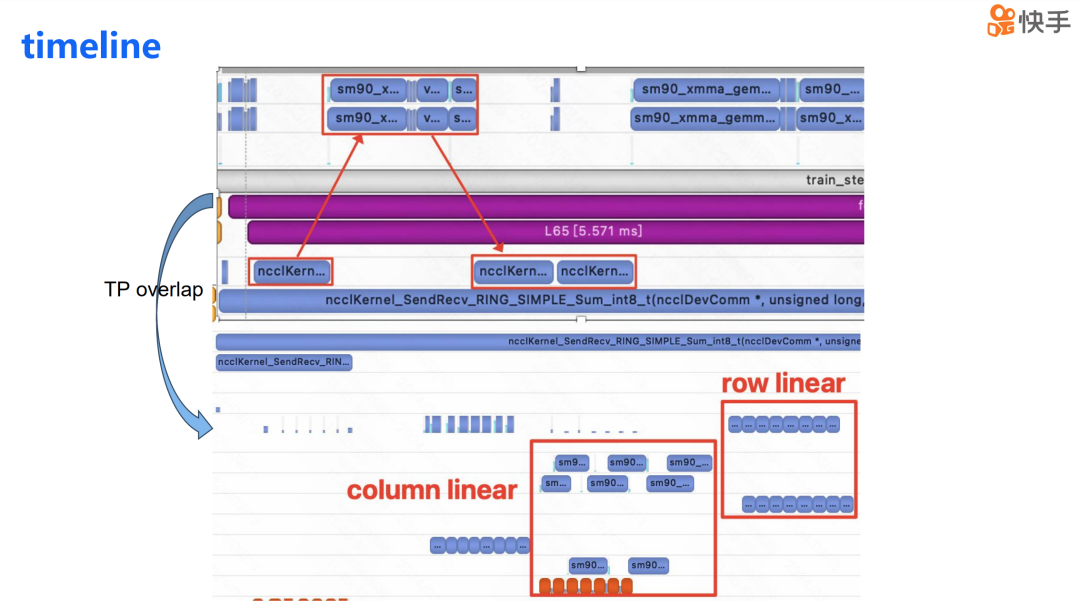
随着模型规模和集群规模的扩大,通信在训练过程中的占比越来越大。为了更直观地展示这一现象,我提供了两张时间线图,它们没有应用计算通信重叠技术。第一张图突出显示了在实现 DP 重叠前的数据并行通信状态,第二张图则突出显示了在实现 TP 重叠前的张量并行通信情况。
从图中我们可以看到,在端到端的训练过程中,DP 的通信占比实际上超过了 15%,而 TP 的通信时间占比也超过了 30%。因此,减少通信对训练的影响,对提升训练效率至关重要。
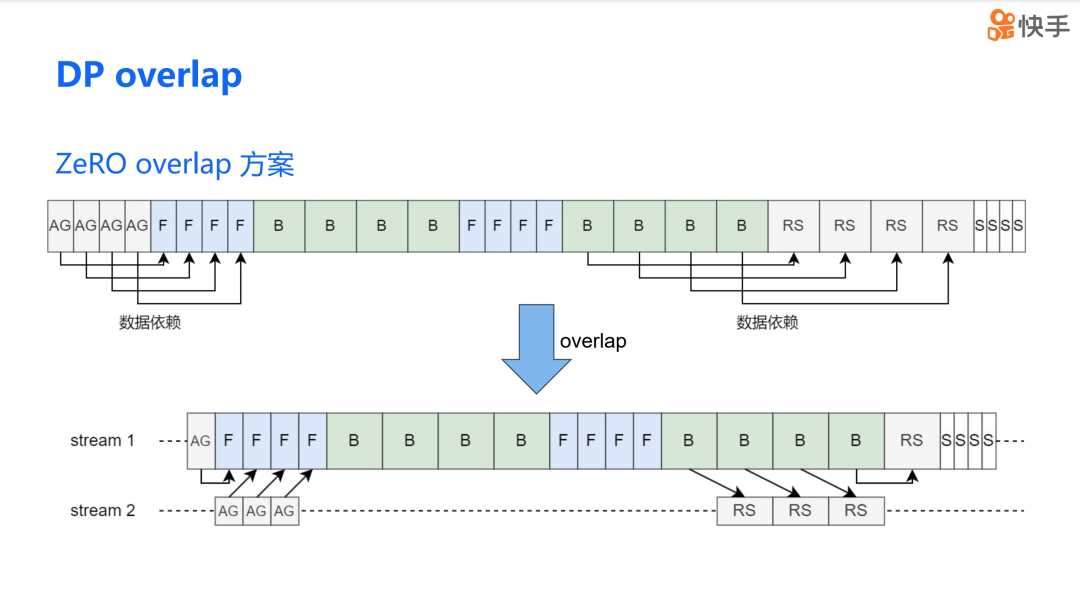
DP Overlap
我们实现 DP overlap 的方法,借鉴了 ZeRO 3 的设计理念。ZeRO 的实现方式是将优化器状态分散到不同的 DP rank 上。通过 all-gather 操作来获取完整的权重,然后使用 reduce-scatter 操作将梯度累加到不同的 rank 上。由于数据依赖于第一个模型块,前向传播(forward)只依赖于第一次 all-gather。因此,在这次计算过程中,我们可以利用这段时间来完成其他 all-gather 的通信。除了第一块模型之外,其余的 all-gather 操作都可以与前向传播重叠。对于反向传播(backward),除了最后一次的 reduce 操作外,所有的 all-gather 操作都可以与反向传播重叠。
我们将这种思路应用到了混合并行中。通过分析数据依赖,我们发现情况几乎是一致的。例如,前两次的前向传播都只依赖于第一个 all-gather。在这段时间内,我们同样可以用来掩盖第二次的 all-gather 操作。类似地,reduce-scatter 操作也可以被反向传播掩盖。由于只有第一个 pipeline stage 的通信无法被重叠,所以重叠的比例是 1 减去 v 分之一,其中 v 代表虚拟 pipeline stage 的数量。当然,我们也可以通过进一步划分来完成第一个 pipeline stage 通信内容的重叠,但为了简化我们后续的讨论,我们暂时不考虑这种情况。
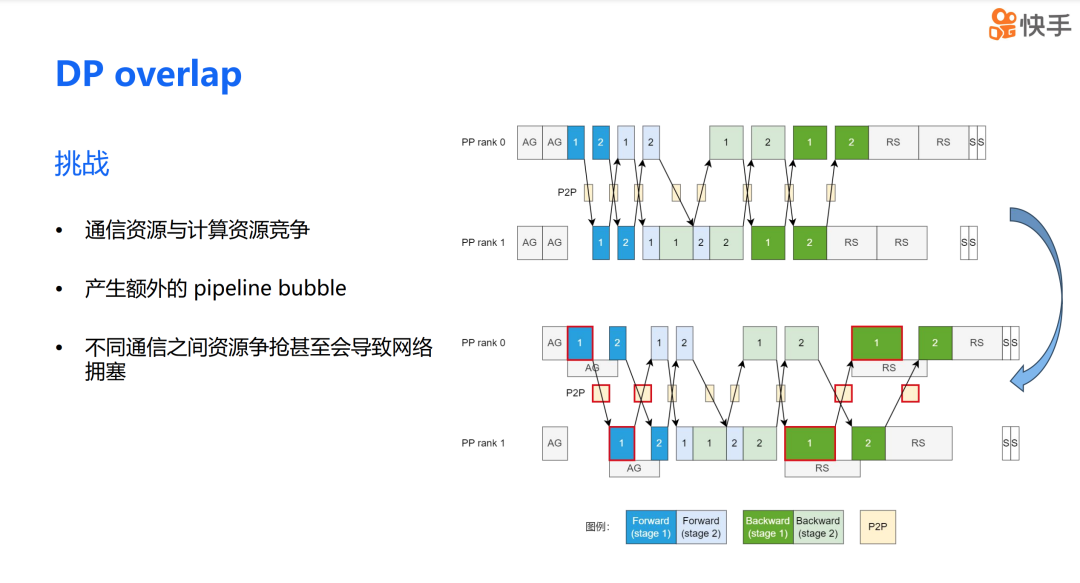
DP overlap 的方案在理论上看起来非常吸引人,但实际应用中,我们真的能显著提升训练效率吗?在进行 DP overlap 优化时,我们遇到了三个主要问题。首先,是通信和计算资源之间的竞争问题。当通信和计算操作同时进行时,它们会争夺有限的硬件资源,这可能会影响整体的系统性能。其次,在混合并行场景下,DP overlap 还可能带来 PP bubble 的问题。第三,不同通信资源的争抢还可能导致网络拥塞。
我们来谈谈通信与计算之间的资源竞争问题。最突出的问题是 SM 资源的竞争。简单来说,通信会占用一部分 SM 资源,这进而会影响计算的性能。然而,我们在进行性能分析后发现,用于计算的 SM 数量与通信占用的 SM 数量并不匹配。
经过更深入的分析,我们发现在 Volta 架构之后,TPC 上的 SM 会共享其配置的共享内存。以 A800 为例,当一个 TPC 为通信内核分配了共享内存后,该 TPC 内的另一个 SM 也会共享这个共享内存配置,导致计算 kernel 无法复用这部分被分配出去的 SM。此外,在 Hooper 架构上,或者更准确地说,是 SM90 以后,我们发现系统会将一个 SM 内的一些 thread block 组织在一起形成一个 virtual cluster,然后以 cluster 为单位进行调度。这可能导致 sm 碎片问题。
我们发现通信与计算之间的相互影响主要与通信的 CHANNELS 有关。CHANNELS 越多,通信占用的 SM 数量也就越多,这导致计算速度变慢。我们的测试是使用 A800 显卡进行的,配备了四张网卡的 A800 来进行测试。从表格中可以看到,当通信的 NCHANNELS 数量小于网卡数量时,通信速度会显著下降。而当 CHANNELS 数量大于网卡数量时,通信速度几乎不再提升。如果继续增加 NCHANNELS 的数量,只会进一步导致计算速度变慢。因此,在综合考虑通信速度和计算时间的增量之后,我们选择了整体最优的通信 CHANNELS 数量。通过前面的分析,我们可以发现,通过牺牲一定的通信带宽,可以达到通信与计算的全局最优状态。
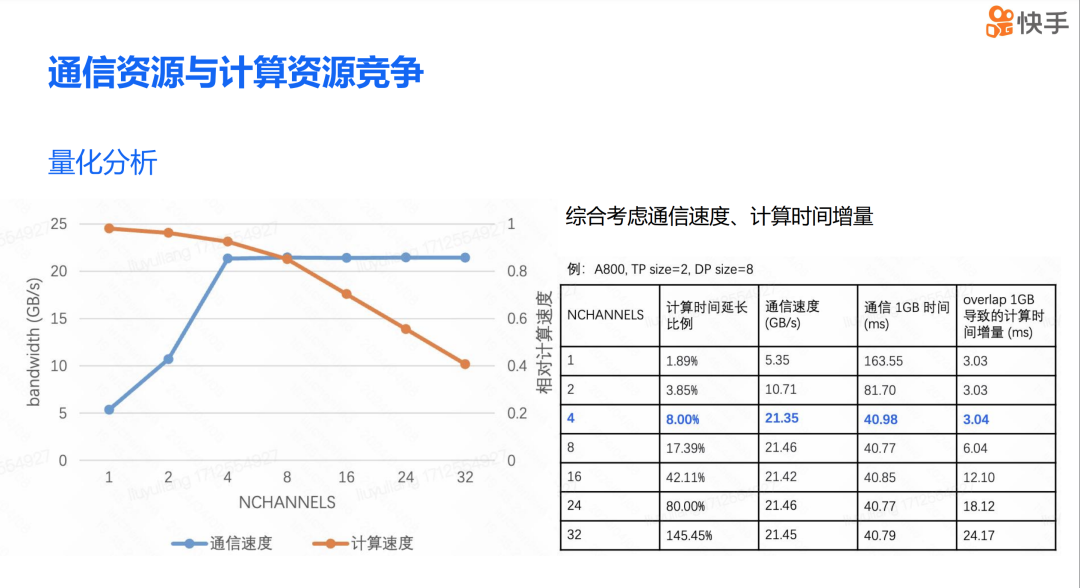
然而我们会发现一个问题,即并非所有通信都能够与计算进行 overlap。如果我们降低全局的通信 CHANNELS 数量,那么我们的策略可能在一定程度上损害到为 overlap 计算的通信效率。为了解决这个问题,我们区分对待了 overlap 计算的通信和非 overlap 计算的通信。对于 overlap 计算的通信,我们会综合考虑通信速度和计算时间增量,然后调整出一个最优的 CTA(Compute Thread Array)。而对于非 overlap 计算的通信,我们会设置带宽最优的 CTA。
除了计算与通信资源的竞争问题,我们还会遇到不同通信之间的竞争问题。我们的解决方案是采用分桶通信。分桶之后,一个 all-gather 会被拆分成多个 all-gather 操作,这样单次的 DP 通信就可以被单次的计算所掩盖,从而尽量避免与 PP 产生资源竞争。但这并没有解决所有问题。即便我们实施了分桶策略,我们发现由于网络抖动等原因,DP 的通信和 PP 的通信仍有小概率发生 overlap,导致多流打入单网卡的现象,进而引起网络拥塞。为了缓解由不同通信之间的冲突所造成的网络拥塞问题,我们从 DCQCN 拥塞控制算法和不同的流优先级上进行了优化。通过这些优化措施,我们能够减轻网络拥塞,提高整体的训练效率。
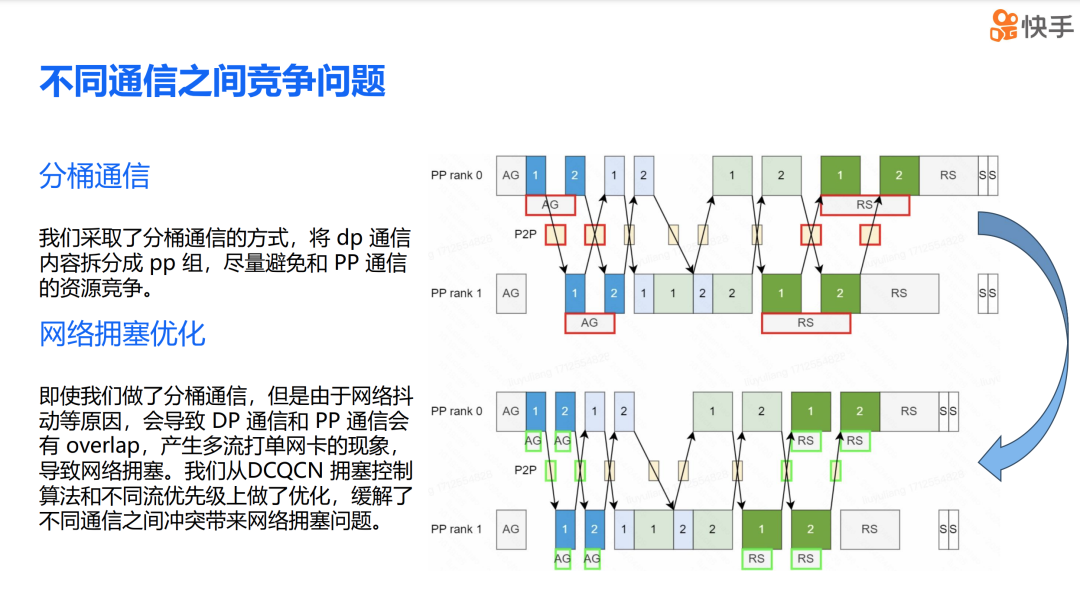
DP overlap 引入的 PP bubble 问题。在前面,我们讨论了通信对计算效率的影响。如果我们模仿 ZeRO 的调度策略,由于 overlap 计算的时间会长于 none overlap 计算的时间,这种负载不均衡会导致 PP bubble 的产生。即图中的 Micro batch 2 的前向传播和 Micro batch 1 的反向传播较长的现象,这展示了负载不均的情况。我们提出的解决方案是通信时机的纵向对齐,这样可以极大地缓解 PP bubble 的问题。同时需要强调的是,从计算 overlap 部分移出来的通信都被放在了 PP bubble 上,因此它不会产生任何额外的影响。这种策略有助于平衡负载,减少因通信和计算不匹配而产生的效率损失。
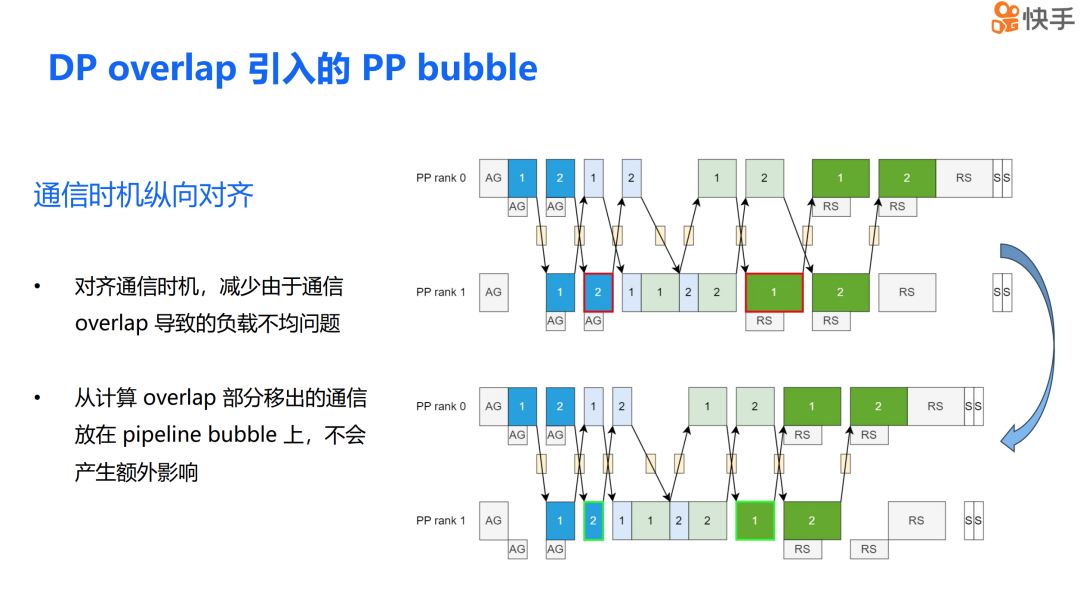
下图展示了我们最终优化后的 timeline。在这个优化版本中,我们实现了 reduce-scatter 与反向传播的 overlap,同时 all-gather 操作与前向传播也实现了 overlap。此外,我们通过分桶通信、网络预测控制、通信 CHANNEL 调优以及通信时机的纵向对齐等方法,大幅优化了 DP 的通信开销。这些优化措施共同作用,提高了整体的训练效率,减少了因通信而产生的延迟和资源浪费。

TP Overlap
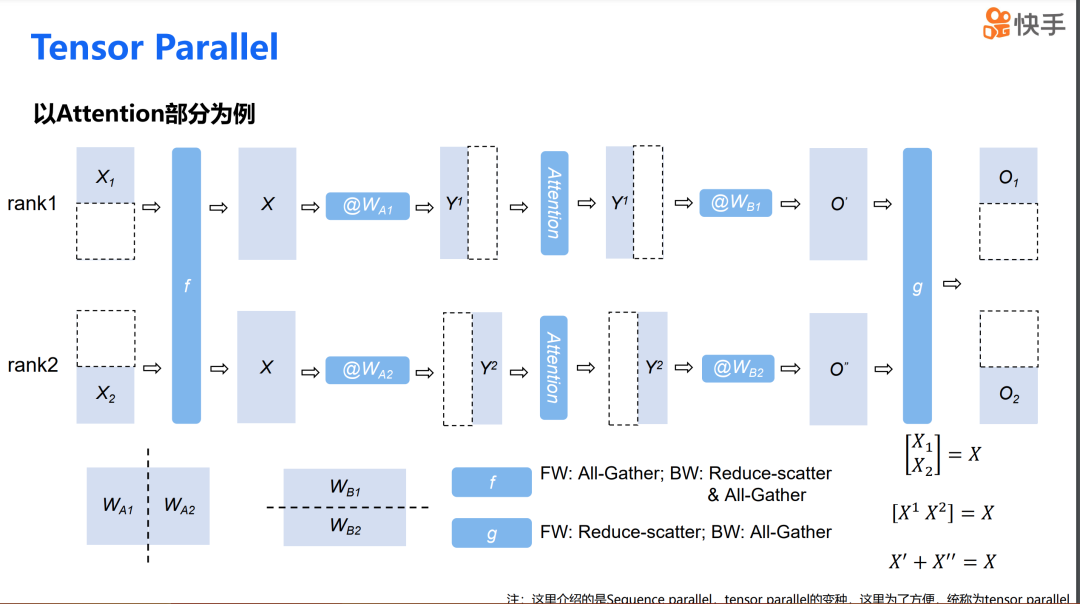
在介绍 TP overlap 之前,我想先向大家介绍一下 Tensor Parallel 的流程。这里实际上采用的是 Megatron-LM 中提出的序列并行,但为了简便,后面我们都简称为 TP。我们以 attention 为例来介绍 TP 的流程。
在 TP 中,一个 attention 层包含两个 GEMM 操作。第一个 GEMM 是将权重沿纵轴切分,第二个 GEMM 是将权重沿横轴切分。首先,我们将输入数据沿横轴切分,然后在第一个 GEMM 计算前,使用 all-gather 操作将两个输入合并。完成第一个 GEMM 计算后,我们会得到一个沿纵轴切分的输出。接着,通过第二个 GEMM,我们可以得到一个部分求和。最后,通过 reduce-scatter 操作,我们可以得到沿横轴切分的数据结果。可以看到,这两个模块的输入和输出都是沿横轴进行切分的,因此这个过程可以持续不断地进行。
在计算过程中,实际上穿插了两个通信操作,一个是 f,一个是 g。其中,f 在前向传播时对应 all-gather 操作,在反向传播时是 all-gather 加 reduce-scatter。而 g 在前向传播时是 reduce-scatter,在反向传播时是 all-gather。我们后续的 TP overlap 策略就是围绕这些通信操作来进行的。
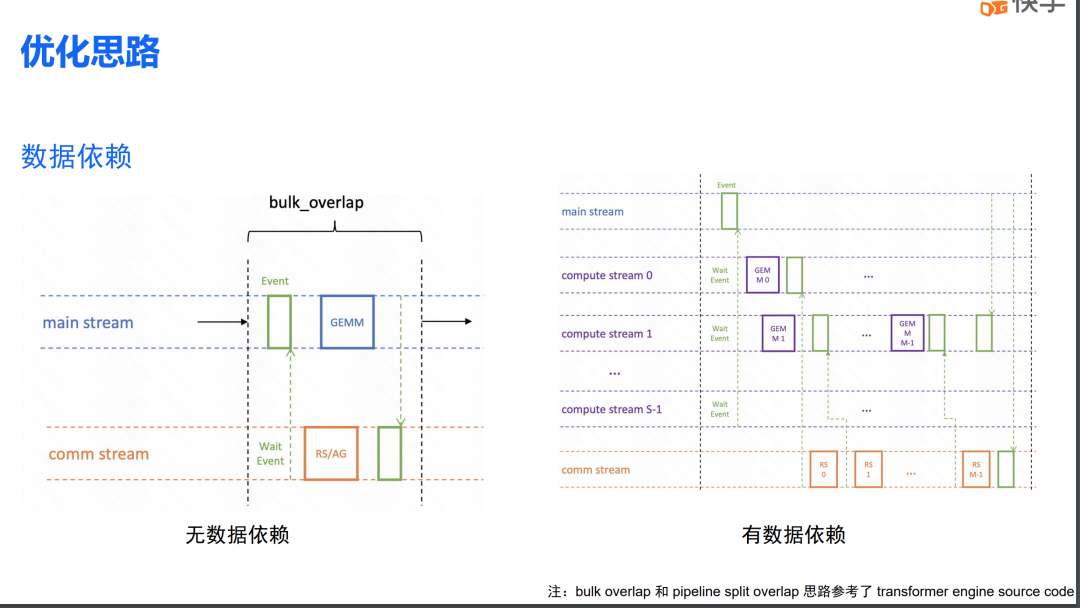
在针对 TP 进行计算通信重叠设计时,我们将其分为两个部分:一部分是有数据依赖的通信重叠,另一部分是无数据依赖部分的重叠。下图左侧展示了无数据依赖计算重叠的方案,这是一种比较经典的计算通信重叠方案。如前所述 DP overlap 就是其中的一种情况。此外,稍后我们会讨论到的 TP 中的列线性反向传播也会采用这种方案。
右侧的图展示了有数据依赖的计算通信重叠。在这种情况下,我们会将 GEMM 操作拆分成若干份(s 份),每一份的计算可以与下一次的计算重叠。需要注意的是,我们将计算也分散到了多个 stream 中。这样做的原因是,不同 stream 之间的计算是没有依赖关系的。因此,计算在不同 stream 之间也可以实现一定的重叠。这部分重叠来自于 kernel 即将结束时,SM 资源的占用会有一定程度的下降。借助 CUDA 运行时调度,可以把另一个 stream 中的 kernel 提前调度上来,从而实现计算的重叠。
下面我会介绍一些 TP overlap 的细节,关键在于合理利用分块矩阵乘法来进行矩阵乘法运算。首先,对于一个矩阵乘法操作,我们可以沿着纵轴将其切分成两部分,并将这两部分分别放到不同的 rank 上。在计算之前,需要进行 all-gather 操作,这实际上是之前介绍的 all-gather+GEMM 的方案。我们可以将这一步的计算进一步分块,在 rank 1 和 rank 2 上分别进行一部分计算,这一步可以称为 step 1。
在执行 step 1 计算的同时,我们可以进行 send 和 receive 操作,将自己持有的那一部分输入数据发送给另一个 rank。接下来执行 step 2,这样通信就与 step 1 的计算重叠起来了。同时,我们还可以通过分块的方式拆分矩阵,也就是将矩阵分为左块和右块。分块的结果可以先计算出部分结果,然后再进行 reduce-scatter 操作,这也是之前介绍的 reduce-scatter+GEMM 的计算流程。
实际上,右侧与左侧的方案类似。我们同样可以将计算分块,先执行 step 1 作为一部分计算,然后将 step 1 的计算结果发送给另一个 rank。在发送的同时,可以开始执行 step 2 的计算,这样就可以实现计算和通信的重叠。
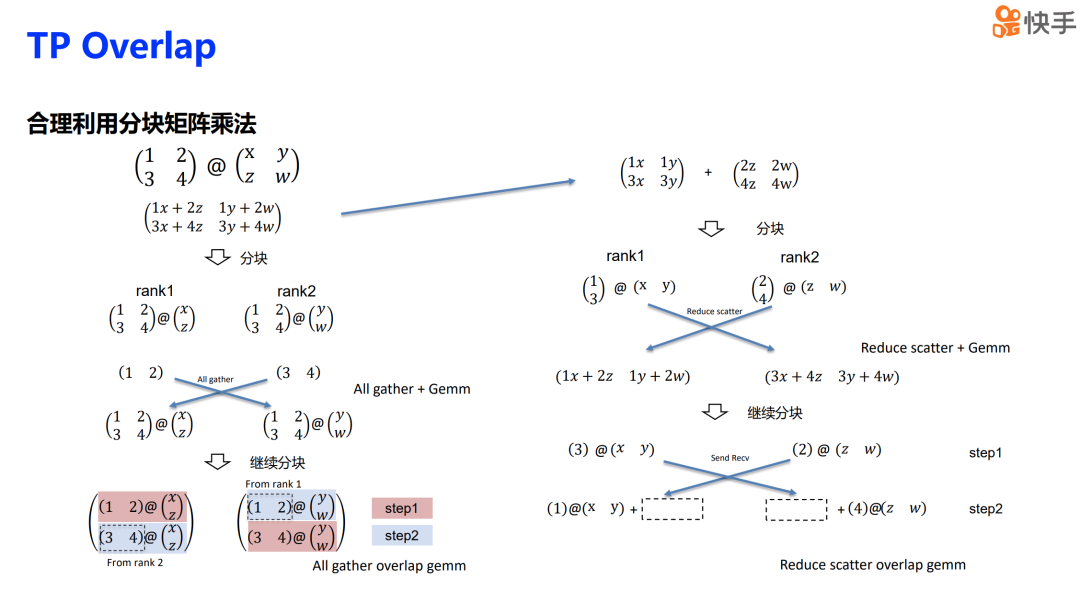
然后我们可以将这种策略推广到四个 rank 的场景中。为了简化表述,我们将计算的 stream 都合并到了一起。对于 all-gather overlap GEMM,我们会特别关注第一个 rank。第一步,我们使用自己持有的那部分输入来进行计算,同时将自己持有的内容也发送给其他 rank,并接收其他 rank 中持有的那部分输入。接下来的第二步、第三步、第四步都是按照相同的原理进行。通过这种方式,我们就可以得到一个 all-gather 的 overlap 流程。这样,每个 rank 都在进行本地计算的同时,与其他 rank 进行数据交换,实现了计算与通信的重叠。这种策略可以有效地减少等待时间,提高资源利用率,从而提升整体的并行计算效率。
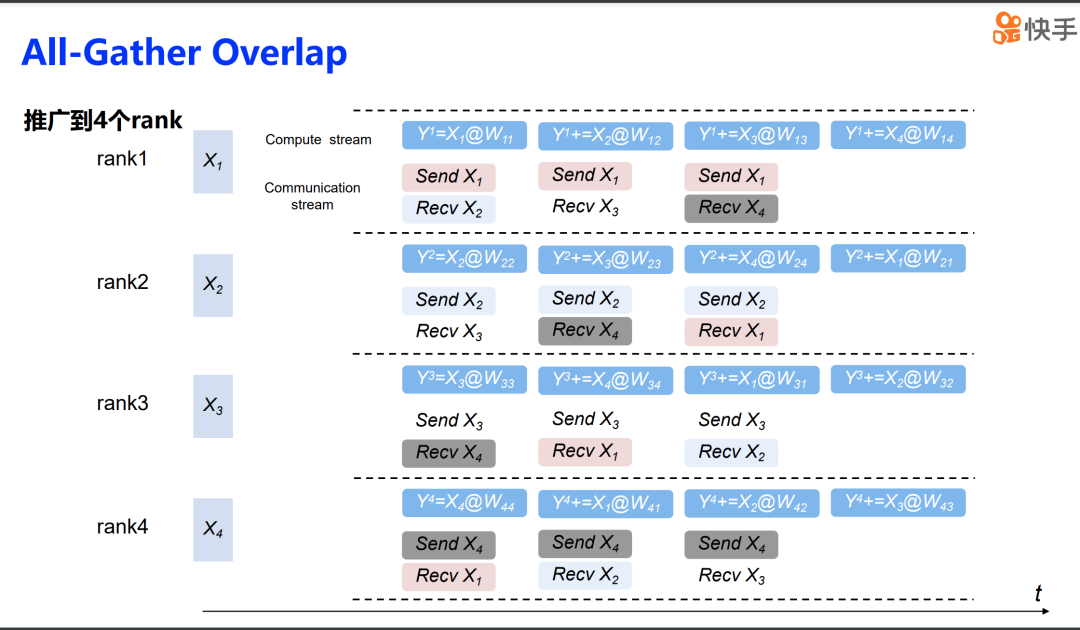
Reduce scatter 的操作也是类似的。我们可以首先关注 rank 4 在整个计算结果流程中的作用。在第一步中,rank 4 的计算结果被放置在 rank 1 上。rank 1 完成自己的计算后,在第二步中,它会将这个结果发送给 rank 2。rank 2 在接收到来自 rank 1 的结果后,会将其与自己的计算结果进行累加,然后继续进行下一步的计算。接着,在第三步和第四步中,流程与前两步相同。rank 3 和 rank 4 也会按照这个顺序接收之前 rank 传递的结果,并与自己的计算结果进行累加。最终,在流程的最后, rank 4 将拿到汇总后的最终结果。
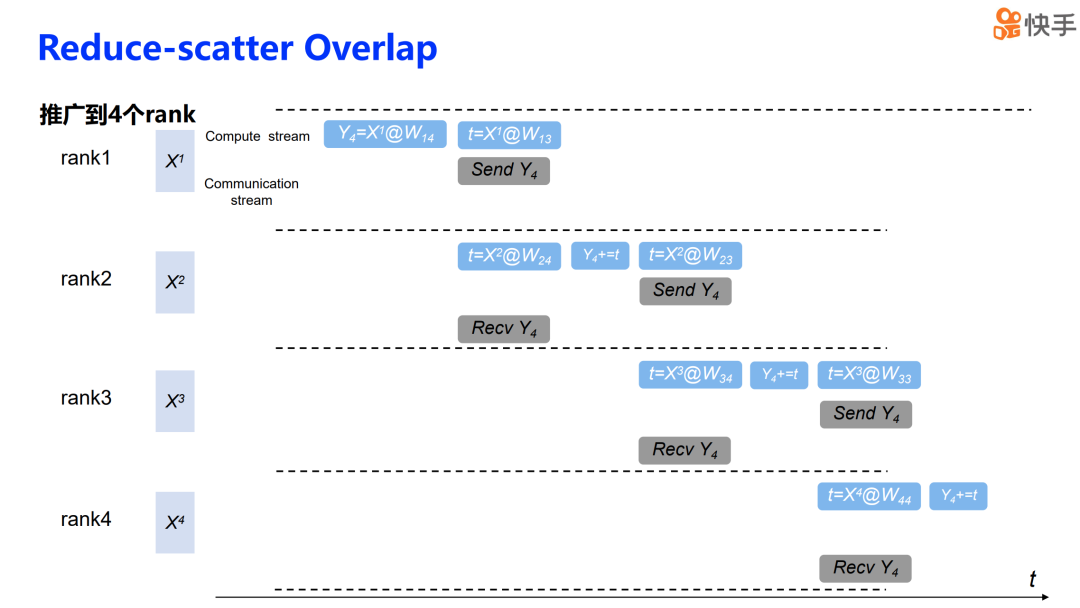
通过上述步骤,我们得到了一个完整的解决方案,适用于处理通信和计算存在依赖关系时的通信计算重叠问题。
这是 TP overlap 的整体解决方案,对于计算通信没有依赖的情况,这里是指 column-wise linear 的反向传播。由于这部分操作没有数据依赖关系,我们采用了 bulk overlap 技术。对于其余的通信和计算,因为它们之间存在依赖关系,我们采用了 split pipeline overlap 的方法。
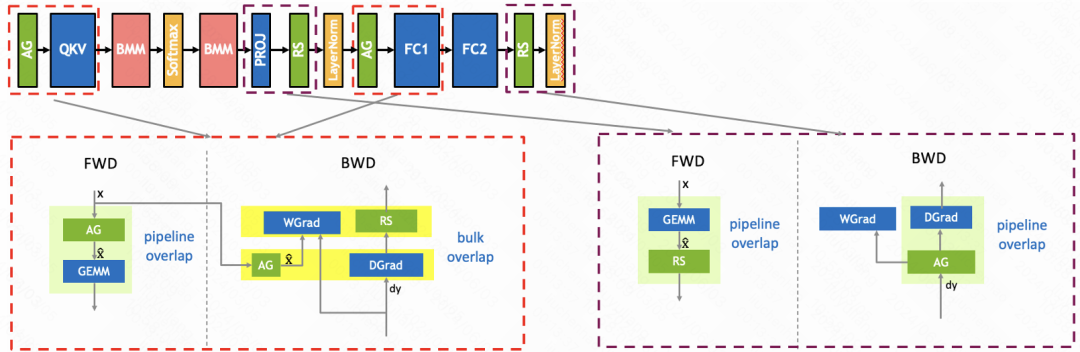
下图展示了实现 TP overlap 后的 timeline,我们可以看到 TP 的通信和计算重叠在了一起。同时,我们进行了两项优化措施:第一项是使用了 peer-to-peer memory copy,以此来减轻通信对 SM 的消耗。第二项优化是将计算分散到不同的 stream 上,这样计算也可以实现部分的重叠。
超长文本场景解决方案
在大语言模型项目中,长上下文问题是最具挑战性同时也非常有趣的问题之一。到目前为止,主流的大模型都已经将上下文窗口(context window)扩大到了 100K 以上,Claude 3 和 Gemini 1.5 Pro 也都支持了超过 1 兆的上下文窗口大小。最近备受关注的 Sora 也对上下文窗口大小提出了巨大的需求,Sora 单个视频输入的长度就超过了 1 兆的 token,因此,长上下文的重要性不言而喻。
在处理长上下文时,我们遇到的最大挑战来自于显存。以 175b、32K 上下文窗口、TP=8 为例进行试算,我们发现仅仅是 activation 本身就给每个设备带来了超过 180GB 的开销,这远远超过了单个设备 80GB 的显存限制。为了缓解显存压力,我们采取了以下措施。
通信换显存:通过这种方式减少显存的使用,但如果我们继续扩大 TP,会导致 TP 超出 NVlink domain,进而导致通信开销大幅增加。计算换显存:通过 recomputing 的方式减少显存需求,但朴素的 recomputing 会带来大量的无效计算。内存换显存:例如使用 ZeRO-offload 或 Torch activation offload 技术。但存在两个问题:ZeRO-offload 无法解决 activation 问题,它只能解决模型状态问题;Torch activation offload 由于调度问题会有严重的性能问题。
现有的方案都是低效且扩展性差的。
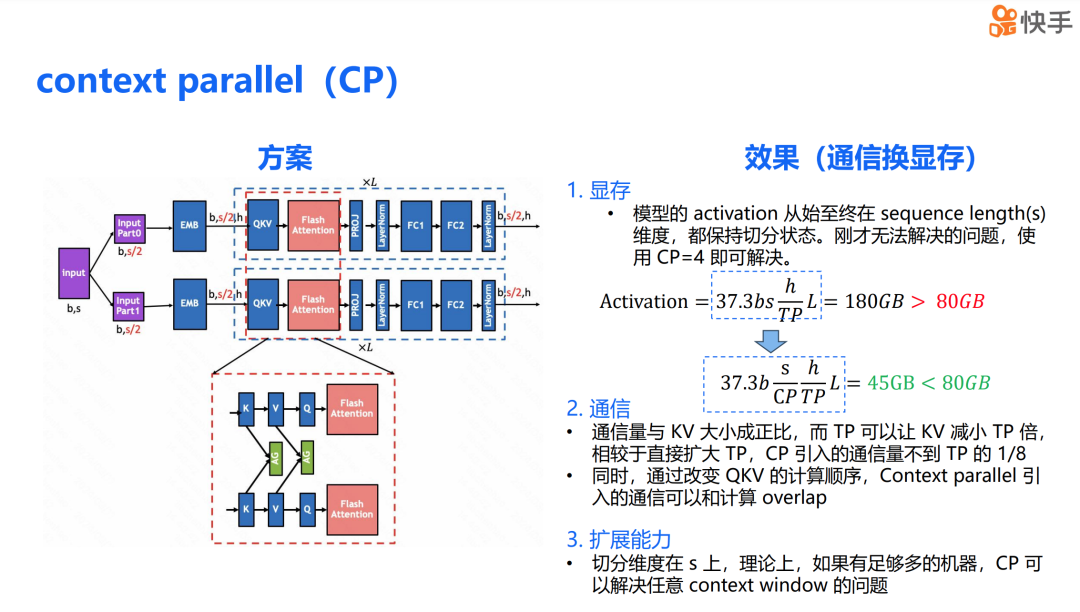
针对 TP 作为通信换显存的两大弊端——在 h 维度上切分导致的不可扩展性以及方案本身的通信量大,我们希望找到一种在 s 维度上可以切分并且通信量相比 TP 小一些的方案。为此,我们实现了上下文并行(context parallel,简称 CP)。
在 CP 场景下,整个模型的 activation 从始至终都在 s 维度上保持着切分状态。之前无法解决的问题,通过 CP=4 就可以解决。我们可以计算这个方案的通信开销,CP 引入的通信开销仅有 KV 前向时的 all-gather 和反向时的 all-gather 以及 reduce-scatter。同时,我们改变了 QKV 的计算顺序,使得 K 的通信可以与 V 的计算重叠,V 的计算可以与 Q 的计算重叠。因此,我们可以得出下述两个结论。
CP 的通信量与 KV 的 activation 大小成正比。在混合并行场景下,利用了 TP 可以减少 activation 大小的特点,使得 CP 的通信量相比于直接扩大 TP 可以减少 TP 倍。由于 CP 的通信可以与计算进行重叠,因此进一步减少了对训练的影响。同时,由于 CP 的切分维度在 s 上,理论上如果有足够的机器,CP 可以解决任意大小的上下文窗口问题。
CP 与其他技术结合时,会带来一些额外的好处和挑战。首先是计算负载均衡问题,这个问题的背景是大语言模型采用了 Decoder Only 架构,并且在 attention 中使用了 causal mask,这导致 CP 会引入计算负载不均的问题。从下面的左图中可以看到,rank 0 的计算负载明显低于 rank 1。
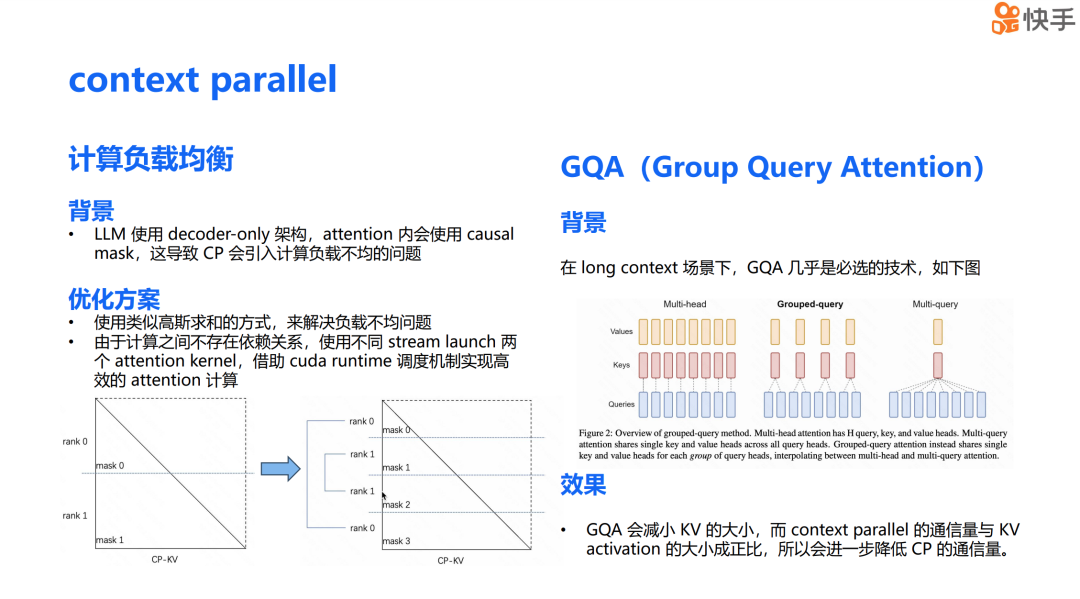
为了解决这个问题,我们采用了类似高斯求和的方法,让每个设备负责一大一小两个 attention 的计算,以此来缓解负载不均的问题。由于同一个设备上的这两个 attention 计算之间不存在依赖关系,为了进一步提升硬件利用率,我们仿照 TP overlap,使用了不同的 CUDA stream 来 launch 两个 kernel。借助 CUDA 的 runtime 调度,我们实现了更高效的并行计算。
结合 CP 还有一些额外的好处。GQA(Grouped Query Attention)是在长上下文场景下几乎必选的技术。与原来的 Multihead attention 相比,GQA 将多个 query 作为一个 group,每个 group 对应一个 K 和 V。可以发现,GQA 可以极大地减少 KV activation 的大小。正如之前提到的,CP 的通信量与 KV 的 activation 大小成正比。因此在 GQA 的场景下,我们可以进一步减少 CP 的通信量,这是结合使用 CP 和 GQA 技术的一个显著优势。
下面是关于计算换显存的方案,其中 recomputing 是一个非常经典的技术。首先,让我们对 recomputing 做一个介绍。下图展示了一个正常的模型训练过程中的数据流。由于反向传播计算对前向传播计算结果存在数据依赖,因此在前向计算完成后,计算结果并不会立即释放,而是要等到反向计算完成后才释放。
右侧的图展示了使用 recomputing 方案的情况。可以看到,在 0 到 3 层的中间结果被释放了,只有 recomputing block 的输入,也就是 layer 0 的 input 被保存了下来。在反向传播过程中,我们会使用保存下来的 input 重新计算 0 到 3 层的前向传播结果,然后再进行反向计算,从而达到节省显存的目的。这个方案从理论上看起来非常理想,但在实际应用中也会遇到一些问题。
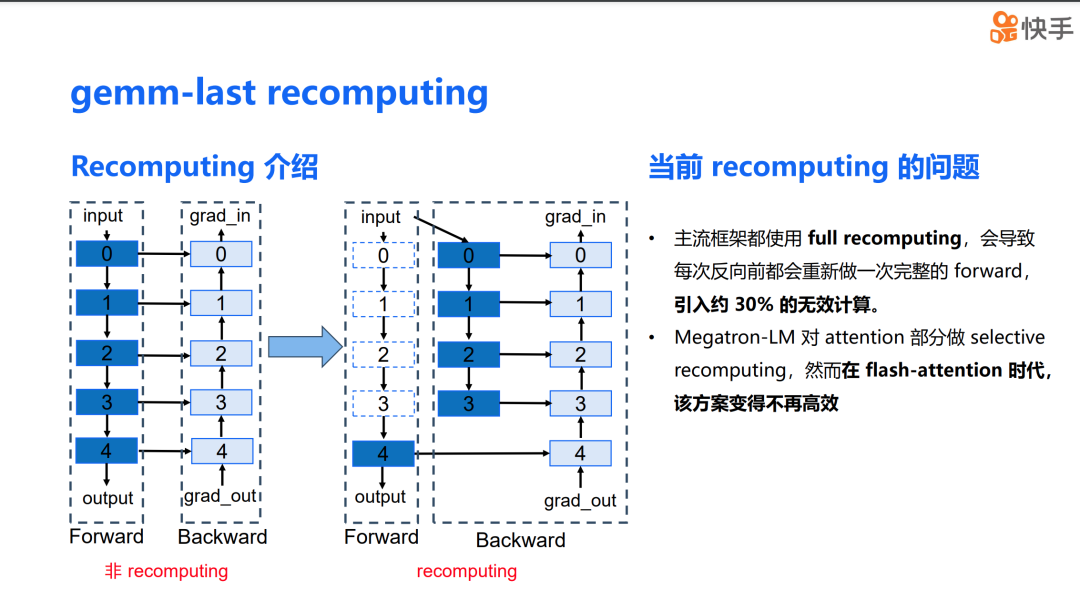
首先,主流的框架都采用了 full computing,这导致每次反向计算都会执行一次完整的 forward pass,引入了大量的无效计算。在大模型时代,这种情况是不可接受的。其次,目前的开源框架 Megatron-LM 对 attention 部分实现了 selective recomputing。然而,在 flash attention 时代,这个方案的效率已经不如以前了。
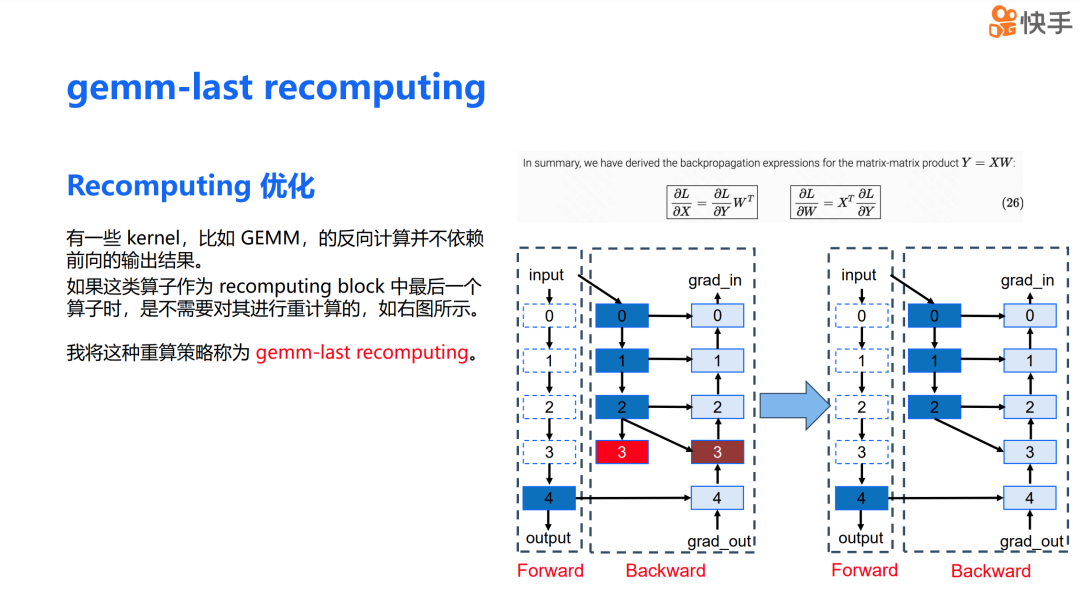
经过观察,我发现某些 kernel,例如 GEMM,其反向计算实际上并不依赖于前向传播的输出结果。例如,对于公式 𝑌=𝑋𝑊,𝑑𝑋 和 𝑑𝑊 的计算并不依赖于前向传播的结果 𝑌。如果我们将这类算子作为 recomputing block 中的最后一个算子,就无需对它们进行重计算。
大家可以看下图右侧。假设层 3 是一个 GEMM 操作,那么 layer 3 的反向计算只依赖于层 3 的输入,而不是层 3 的输出。这样,在重计算时,我们可以省去 layer 3 的前向计算。我将这种重算策略称为 GEMM last recomputing。
我们将 GEMM last recomputing 策略实施到大语言模型的训练中,发现只需要对计算量较小的算子进行重算。相比于没有采用 recomputing 的方案,我们的策略在增加了不到 1.5% 的计算量的情况下,减少了 40% 的显存开销。这是一个在保持计算效率的同时显著减少显存需求的有效方法。
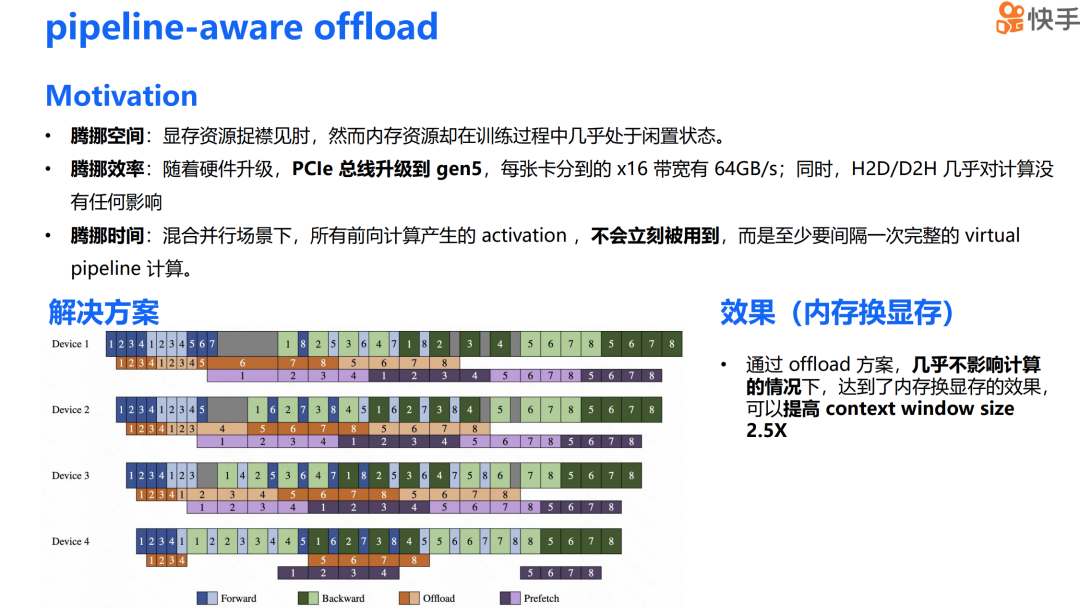
接下来是内存换显存的方案。我最初产生这个想法的原因是,在训练过程中,显存资源已经非常紧张,然而内存资源在训练状态下却几乎处于闲置状态,这为我们提供了一定的操作空间。其次,随着硬件的升级,PCIe 已经升级到第五代,每张卡分配到的 x16 带宽达到了 64GB/s。同时,由于 H2D(Host to Device)和 D2H(Device to Host)是 memory copy 操作,它们对计算的影响几乎可以忽略不计。在混合并行场景下,每次前向计算产生的 activation 并不会立即被使用,而是至少要间隔一个完整的虚拟 pipeline stage 计算,因此混合并行架构也为我们提供了足够的时间窗口。
我们的解决方案是,将每个虚拟 pipeline stage 前一个 micro batch 的 activation H2D 和 D2H 的通信操作与下一个 micro batch 的计算进行 overlap,这样可以极大减少 offload 对关键路径上计算的影响。通过这个 offload 方案,我们能够在几乎不影响计算性能的情况下实现内存换显存的效果,上下文窗口大小提升了 2.5 倍。
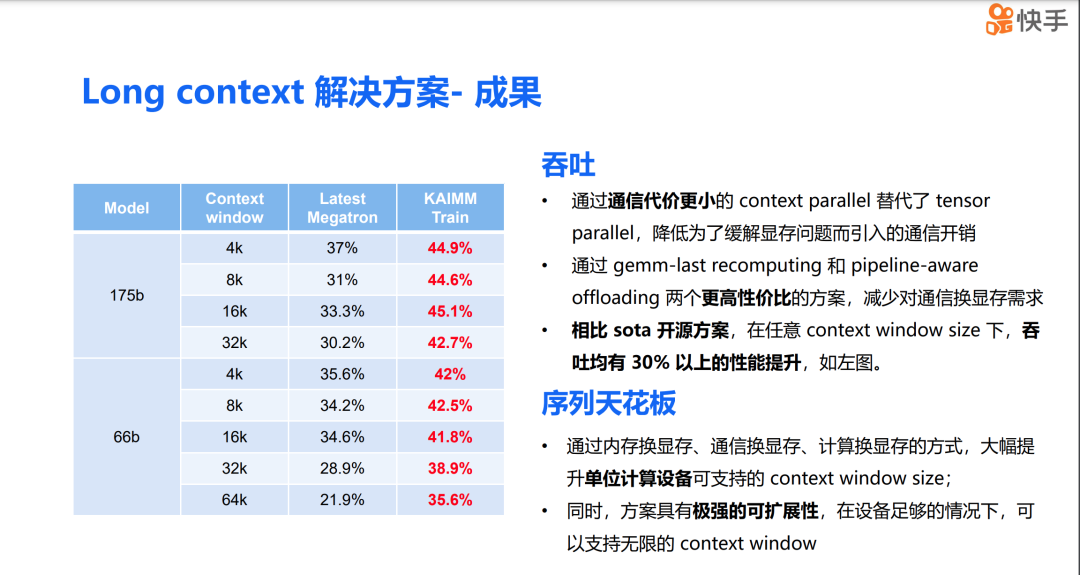
接下来展示的是这个解决方案的整体成果。我们在 H800 集群上进行的测试显示,在吞吐量上,与现有的最先进开源方案相比,我们在 任意上下文窗口下都能实现超过 30% 的性能提升。 能达到这样的性能提升主要归功于两点原因:
第一,我们采用了通信代价更小的 CP 来替代 TP,从而降低了为解决显存问题而引入的通信开销;第二,我们采用了 GEMM last recomputing 和 pipeline aware offloading 这两种更具成本效益的显存问题解决方案,减少了以通信换取显存的需求,进一步实现了训练吞吐量的提高。
在支持的序列长度上限方面,首先,我们通过内存换显存、通信换显存、计算换显存的方法,大幅提升了单个设备支持的上下文窗口。同时,由于该方案还具有极强的可扩展性,因此在设备资源充足的情况下,我们可以支持无限大的上下文窗口。
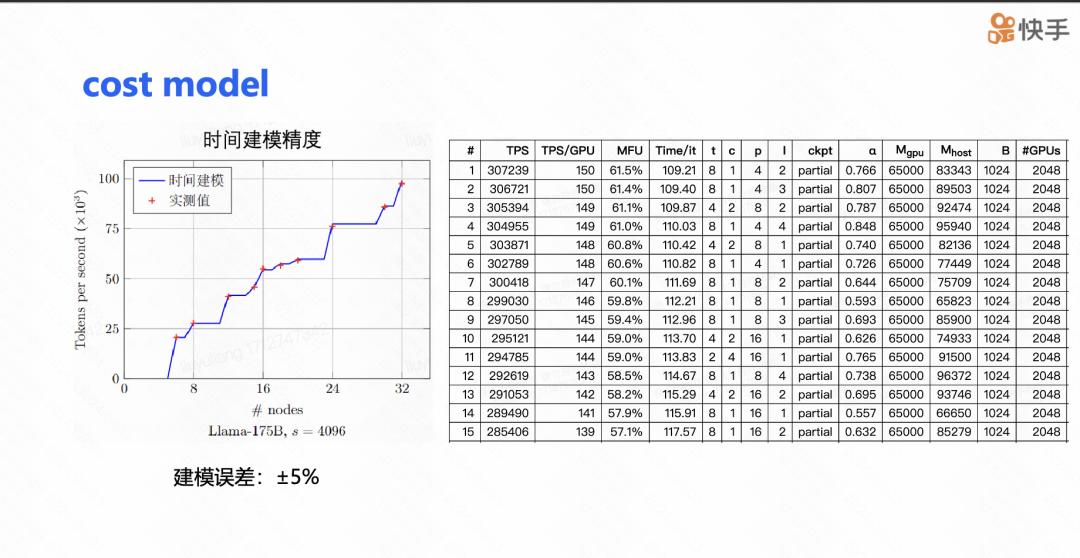
接下来是 cost model(成本模型)的介绍。在进行大模型训练时,参数调整是一个非常痛苦的过程,因为模型有大量的参数,并且这些参数之间相互影响,比如 TP、CP、DP 的大小,以及 offload 的比例,还有网络设置中的 CTS。如果对所有参数都进行实际运行测试,将会消耗大量的计算资源。然而,如果不进行实际运行,仅仅通过比例和一些基于 FLOPs 理论算力的简单折算来预测,会导致预测极其不准确。因此,这样的成本模型是不可行的。
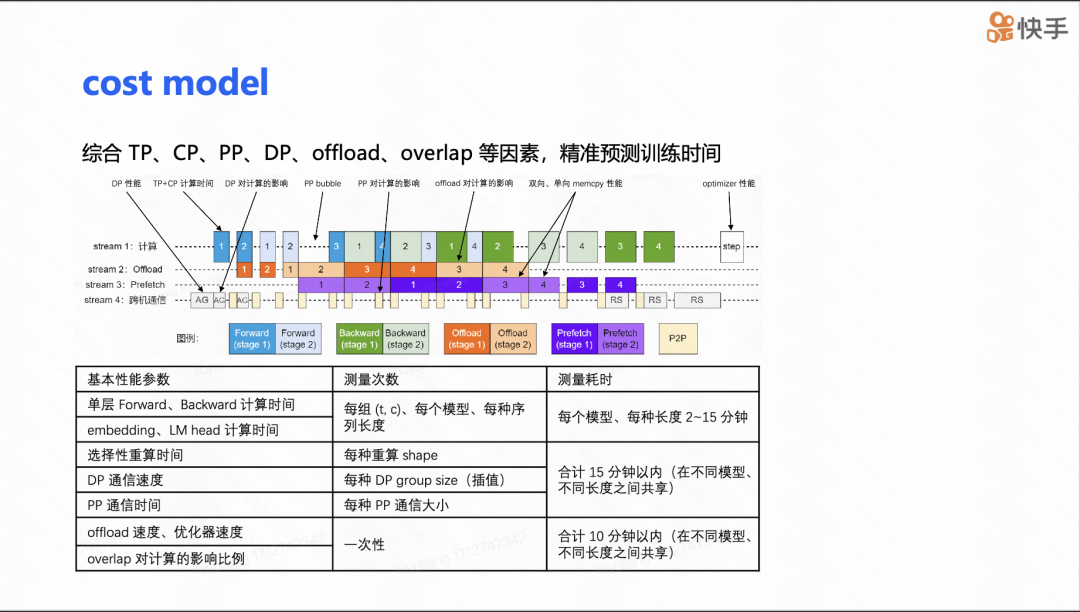
为了解决这个问题,我们对 TP、CP、PP 等一系列可能影响性能的因素进行了细致的建模。我们将所需信息分为与模型相关的信息,比如不同组合下单层前向和反向传播的时间;以及与集群相关的信息,比如跨机器的集群通信带宽或者 H2D 的带宽等。整体的测量耗时可以在一个小时内完成,并且这些信息可以多次复用。
在 175b 的案例中,我们建模的预测值和实测值之间的误差控制在 2% 以内。在实际使用过程中,我们的成本模型的误差与实测值的对比也不超过 5%,其中大部分误差来源于网络的不稳定性。下图右边展示了我们的成本模型给出的参数配置表。通常情况下,搜索完成后,我们可以根据 MFU 的前 5 名进行实际测试,最终得到我们的训练配置。这种方法大大提高了参数调整的效率和准确性。
未来展望
未来在训练引擎方面我们会专注于五个主要方向。
万亿参数规模的 MoE 模型:我们期望能够训练具有万亿参数的 MoE 模型,这将推动模型容量和性能的显著提升。继续扩大序列长度:我们希望能够支持达到百万级别的序列长度,这将极大地扩展模型处理长文本数据的能力。RLHF 框架:目前还没有看到非常高效的 RLHF 框架实现,这将是未来研究的一个重要领域。低精度训练:随着 Hopper 系列架构的推广以及 FP8、FP6 等多精度配置训练,我们将需要关注低精度训练技术的发展。异构算力的引入:我们需要考虑引入异构算力来增强训练引擎的灵活性和健壮性。