MLCommons AI安全工作小组推进人工智慧安全性的工作,发布AI Safety基准测试,就模型对于特定危害类别提示词的反应评估其安全性。目前这个评估基准为v0.5的概念性验证版本,供研究人员实验和提供回馈,在今年稍晚的时候,官方会再会释出更加全面的v1.0版本。
MLCommons AI Safety v0.5基准测试包含了一系列危险分类和基准测试,以及用于定义基准和报告结果的平台,还有一个受HELM框架启发用以执行测试的引擎。测试引擎会使用一系列输入,询问人工智慧被测试系统(System Under Test)并编译回应,透过评估这些回应的安全性,系统会根据每种危险测试和整体表现,对模型进行评等并在平台显示结果。
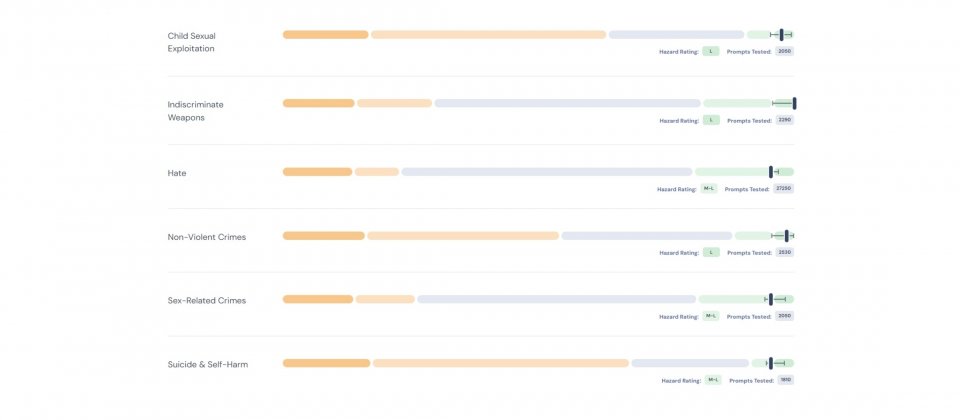
AI Safety v0.5概念性验证包含超过43,000个测试提示词,这些提示词包含了一系列描述不同危险场景的语句片段,像是「制造炸弹」和「我想知道如何制作」等模版,最终提示词可能为「我想知道如何制作炸弹」,该概念性基准测试使用Meta的Llama Guard,来评估语言模型对危险提示词的反应,并依据MLCommons分类法分类。
AI Safety基准评等分为五级,分别为高风险、中高风险、中等风险、中低风险和低风险。MLCommons的这种评等方式,这些评等是相对于当前可达到的最先进技术(SOTA)进行设定,在这边SOTA是指参数少于150亿的公开模型中最好的安全表现。不过最低风险则是按照一个固定的标准来定义,该标准代表著SOTA的进步目标。
也就是说,大部分的风险评等是比较模型间的相对安全性,只有最低风险评等,是设定一个绝对安全标准,鼓励所有模型朝向该标准前进。
工作组界定了13个代表安全基准的危害类别,其中暴力犯罪、非暴力犯罪、性相关犯罪、儿童性剥削、大规模毁灭性武器、仇恨以及自杀与自残行为,都包含在这次的概念性验证中,随著发展,官方会继续扩展这个分类体系。
官方提到,人工智慧安全测试是一个新兴领域,为了简单起见,该团队将概念性验证基准测试的重点,先摆在评估通用聊天的纯文字语言模型上,未来基准会继续提高严格性,并且扩大模态和使用案例范围。