
本文来自微信公众号:镜相工作室(ID:shangyejingxiang),作者:赵一帆,制图:阮怡玲,编辑:卢枕,题图来自:视觉中国
国产大模型公司展开降价潮,引发关注和讨论。• 💰 价格战由一家新公司掀起,各大厂商纷纷加入降价行列
• 🤖 大模型公司降价策略精心计算,涉及不同模型和服务级别
• 🚀 降价目的是吸引更多开发者,推动AI应用的爆发
国内大模型公司,也没有错过今年的618。
“降价97%!”“免费!”过去一个月,各大国产大模型厂商喊出了不要钱的架势,降价之狠,让外行惊叹。
谁也没想到,这场价格大战是由一家本不在牌桌上的公司掀起的。
5月6日,知名私募机构幻方量化创立的大模型公司“深度求索”(英文名:DeepSeek),发布了第二代MoE模型DeepSeek-V2。模型迭代的同时,其API调用价格直接降至每百万tokens输入1元、输出2元。
仅为GPT 4-Turbo百分之一的定价,让这家公司在AI界迅速崭露头角,也让一众互联网大厂和大模型独角兽坐不住了。
不出半个月,智谱AI、字节跳动、阿里云、百度、腾讯云、科大讯飞等头部玩家纷纷加入降价行列,你追我赶地大举下调了模型价格。
这番场景,让人不禁回忆起ofo和摩拜的“单车之争”、滴滴与快的的“合并之战”。短短两年间,大模型这场不见硝烟的战争,似乎也步入了最简单粗暴的阶段。
然而,这场声势浩大的降价潮,究竟是单纯的成本让利,还是一场精心策划的营销之战?为何一众大厂迅速响应,大部分初创公司却持观望态度?大模型客户们真的能从这波降价中获益吗?参与降价的企业,真正的目的是什么?
真降价还是假噱头?
截至发稿,公开宣布参与本次价格战的公司共有7家,其中包括字节、腾讯、阿里、百度四家互联网大厂,大模型创业公司“智谱AI”、老牌AI上市公司“科大讯飞”,以及这次价格战的发起者“DeepSeek”。
镜相工作室研究发现,这波来势汹汹的价格大战,不像宣传中那么简单直降,而是一场精心计算的策略游戏。
首先,降价最狠的基本都是入门级的基础模型,而那些最高配的模型其实并不打折。
每家大模型公司,都有一个“模型家族”,里面有性能不一的通用模型,也有擅长某些场景的专用模型。比如OpenAI旗下的GPT-3.5和GPT-4,以及文生视频模型Sora。
以百度为例,百度宣布降价的两款大模型,分别是适合在特定场景作为基座模型进行精调的轻量级模型ERNIE Speed,和参数更小、适合搭载在低算力卡上的ERNIE Lite。而最新发布的超大规模模型ERNIE 4.0系列并未降价。
最先坐不住的智谱AI,第一次宣布降价的也是其最基础的模型GLM-3 Turbo,最先进的GLM-4并未搬上价格战的牌桌。直到6月5日第二次降价,才将GLM-4系列中的图生文模型GLM-4V加入降价行列,但最常用的对话版模型依然没有降价。
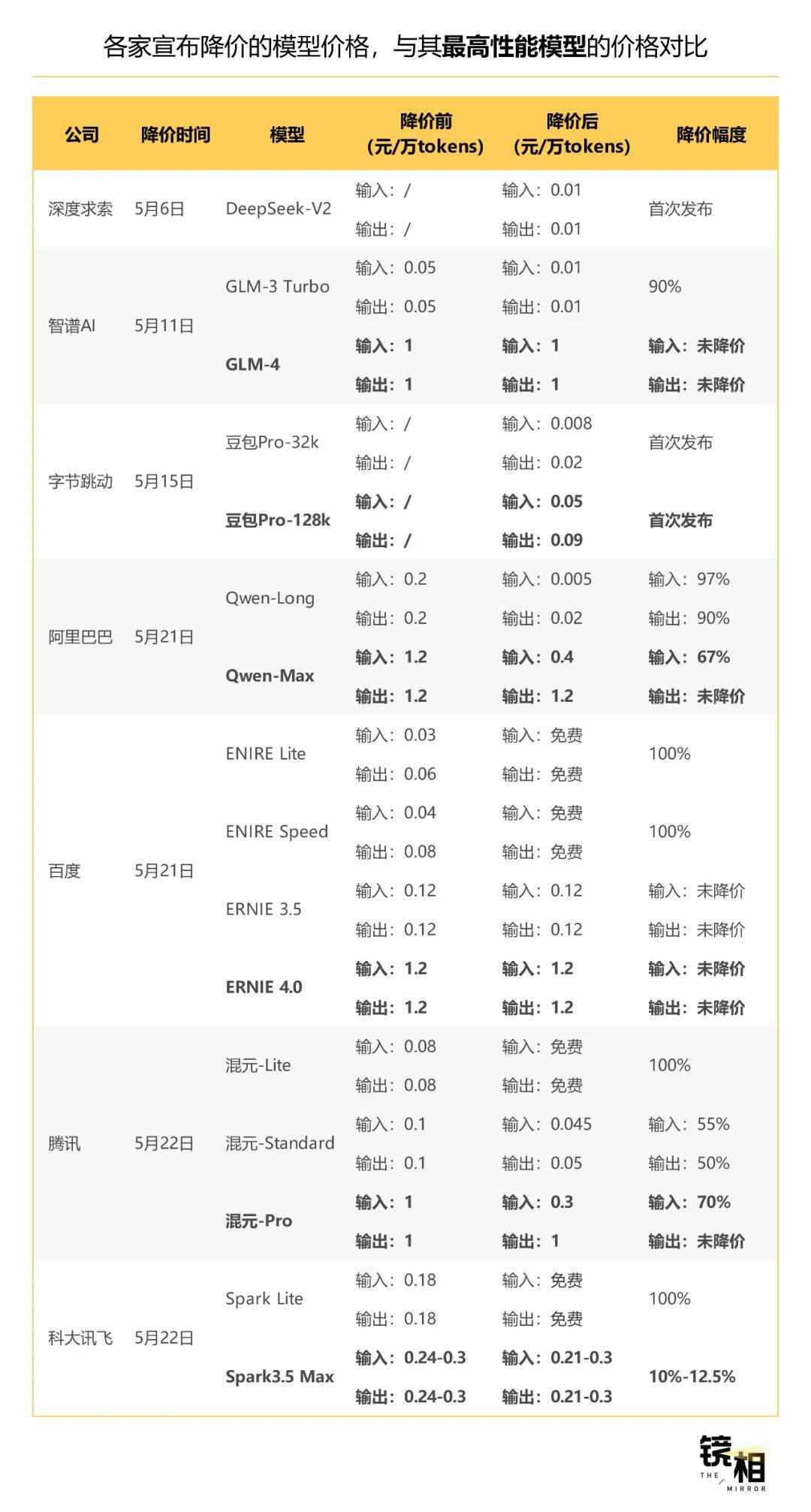
巧的是,部分公司降价的,也只是输入部分的tokens使用量,输出部分的价格不仅没降价,还在各家打出的降价广告语中被悄悄隐藏了。
在API调用中,推理费用的具体定价,分成“输入”和“输出”两部分。输入指的是,用户向大模型提出的问题,输出则是大模型给出的答案。
例如腾讯的混元-Pro大模型,虽然输入价格大幅下降了70%,但输出价格并未优惠,依旧保持原价。同样,阿里云的Qwen-Max模型输入价格下调了67%,输出费用也维持不变,没有折扣。
在各家的宣传里,有不少是拿自己降价的模型与别家最贵的模型作对比,才有了动辄“比行业水平便宜90%”的降价幅度,让外界以为下了血本让利客户。实际上,模型之间性能不同、使用场景不同,有的降价是真有用,有的更多只是一个营销噱头。
其次,同一个模型不同的交付模式,也对应着不同的价格。根据使用场景、部署方式和用户需求,大模型的交付模式通常会分为基础服务、进阶服务和高阶服务。
基础服务指的是,用户直接调用平台已经预设好的API,来使用模型的功能。而进阶服务意味着,用户可以把模型部署到自己的服务器或云平台上,然后根据使用场景对模型进行微调,可以理解为定制产品,在特定任务上的性能和准确性会更高。
当用户觉得,大模型的响应速度不够快时,可以选择高阶服务,不再需要和其他人抢计算资源,用户可以独占所有计算资源,来确保调用频率和响应时长满足业务诉求。
目前各家企业大幅降价的焦点,更多集中在基础服务,即直接调用预置模型进行推理。如果初级服务无法满足需求,就需要更高级的模型微调和部署服务,这部分其实并未降价。
以阿里云参与降价的通义千问主力大模型Qwen-Long为例,降价只针对基础服务。对于寻求更高级服务的用户来说,需要转向其他模型产品,因为Qwen-Long模型本身不支持微调和自定义部署。
而百度宣布的两款免费模型,仅限于初级的平台预置服务阶段。一旦用户需要模型部署或进一步的精调服务,免费优惠便不再适用。
以百度的ERNIE Speed模型为例,虽然基础服务免费,但一旦用户升级至进阶服务,费用即提高到0.005元/千tokens。若用户选择更高级的服务,价格则进一步增至0.008元/千tokens。随着服务级别的提升,费用也会相应增加。
一分钱一分货,想要得到更高级的服务,用户就需要花费更多的钱。进阶服务和高阶服务,一般依照消耗的计算资源来计费,即实际训练过程中使用的计算资源和训练时长。
以智谱AI的ChatGLM-130B模型的私有化部署为例,企业用户一年需要支付高达3960万元的费用。这一价格显然只有具备一定规模和财力的大型企业客户才能承担。
因此,这一波降价,只能说降低了企业用户使用大模型的门槛,利好一些个人开发者和小创业公司,真要大规模使用大模型,依旧省不下太多钱。
为什么创业公司不参与价格战?
与火药味十足的大厂相比,资金有限的初创公司显得更为冷静。
除了智谱AI之外,包括百川智能、月之暗面、零一万物在内的几家头部大模型初创公司并未加入降价行列。MiniMax虽然宣布了价格调整,但仅针对其语音模型进行了调整,文本大模型的价格则保持不变。
创业公司是否跟风降价,主要得看几个条件:一要看商业模式,有没有必要跟;二要看技术能力,能不能跟得动;三要看生态,能不能跟下去。
商业模式决定收入来源,大模型企业主要有两种盈利途径:一是面向企业客户(B端),销售API服务或定制化大模型;二是直接面向消费者(C端),提供终端产品。
出售API,是大模型公司常见的赚钱方式。企业训练出自己的模型后,通过API将其功能提供给开发者或企业。这样,开发者无需从头开始训练模型,只需输入自己的数据进行微调,便能迅速开发出定制化的应用程序。因此,降价主要受益的是开发者和企业客户,对普通消费者没有直接影响。
以C端市场为主战场的创业公司,就没有必要卷入这场价格竞争。
一位头部VC机构的投资人也认为,智谱AI面向的主要是企业客户,因此它调整价格以适应市场是符合逻辑的。相较而言,其他几家AI创业公司专注于C端市场,它们的盈利并不完全依赖API销售,自然没必要趟这个浑水。
但对于那些靠卖API活着的创业公司,就难以保持从前的从容了。面对大厂的搅局和收入的减少,这些公司的市场空间逐渐缩小,必须开始寻找新的商业模式。
百川智能在发布新模型Baichuan 4时,也同步推出了AI助手。这也意味着,百川正在寻求销售API之外新的盈利模式,以应对大模型低价战。
猎豹移动董事长兼CEO傅盛也表示,这次大降价基本宣告了大模型创业公司必须寻找新的商业模式。降得最凶的都是有云服务的大公司,通过大模型来获取云客户,“羊毛出在猪身上,降得起”,而大模型创业公司没有这样的生态,必须另寻商业模式。

2024北京智源大会上,几位头部大模型初创公司创始人同台论道。摄影:赵一帆
技术的差距,也是一些创业公司打不出低价牌的重要原因。算法的不断优化,使得大模型的训练和推理效率得到提升,这直接导致了成本的大幅下降。
从算法逻辑来看,传统Transformer架构的大模型运作起来,就像一个不论任务大小,总是启动所有机器的工厂,这种无差别的运作方式容易导致资源的浪费。
而打响价格战的深度求索,采用了更聪明MoE算法架构。在这种模式下,工厂可以实现资源的精准分配,只需特定的机器,其他机器保持待命状态就好。更加智能的分工,优化了成本和效率,这也是它能够提供更低价格产品的关键。
零一万物的CEO李开复对大模型成本下降持肯定态度。他在接受采访时表示:“未来整个行业的推理成本每年降低10倍是可以期待的,而且也应该是必然发生的。”
头部云厂商的中层管理者田梦怡更谨慎看待这个问题。她告诉我们,“在过去两年,大厂在模型训练和推理的提效上,每年降低到之前的1/10是正常的,但未来空间可能也没多大了。”
此外,大厂凭借长期积累所构建的生态,也是创业公司难以快速复制的竞争优势。参战的云厂商,客户众多,商业模式多元,有能力同时响应不同的需求,通过提高资源利用率,进一步压缩了成本。
田梦怡解释道:“大厂可以超卖,可以自用和售卖结合,这是庞大业务规模带来的腾挪空间,也是其挣钱的重要来源,小厂没有这种条件和人才。”
以阿里云为例,为了提高资源利用率,其研发出了“动态资源超卖”的技术。简单来说,就像一个智能监控系统,可以实时查看服务器资源的使用情况,在不影响服务质量的情况下,将同一资源分配给更多用户。不仅极大降低了单位成本,也为其提供了更大的降价空间。
大厂完备的供应链体系和配套服务,也成为创业公司难以跟随的障碍。
大模型从接入到部署,具有一定技术门槛,不是每个企业客户都具有这些能力。大厂通过提供模型服务和开发工具,助力企业更快地部署和开发。同时,企业还能利用大厂平台发布新应用,借助其用户基础来增加曝光和流量。
综合看,大模型降价,大厂更有实力,也更有动力。对创业公司来说,性价比却不高。
大模型降价,到底图什么?
在大模型的世界里,时间仿佛被压缩。仅仅花了一年时间,大模型厂商们就从技术竞争迅速过渡到了比价大战。
多家云厂商负责人公开表示,降价是希望吸引更多开发者,加速AI应用的爆发。但事实果真如此么?他们又为何选择这一时间点降价?降价究竟有没有用,又能持续多久?
To C流量难增长、To B业务难挣钱,成为点燃价格战的导火索。
随着时间推移,业界开始意识到,仅靠一个交互式聊天窗口是无法持续吸引用户的。傅盛的说法,也印证了这一事实。他表示:“现在各个大模型App基本都是免费的,本质上应该是各个大模型App用户量涨不动了,包括OpenAl。”
而大模型在B端的应用场景又太少,在日常工作生活里,其实很少能感受到大模型能力的落地。
一位火山引擎内部人士向我们透露,国内大模型卖API的To B收入,现在非常少,相比训练侧的投入可以说是杯水车薪。
因此,降低定价其实是一种营销策略,目的是让更多开发者先把大模型用起来。比如,要用100亿tokens打磨一个业务场景,以前要花100多万,起码得立项审批到副总,还有很大概率会失败。现在8000块钱就能做,小组长就能批。
这样做的好处是,可以快速地吸引到开发者,应用多了,需求也就多了,他们才愿意为后续的服务付费。
从短期角度来看,降价策略可能会导致赔本。然而,官方口径的背后,打包出售整套云服务、提振公有云业务才是降价背后的长期目标。
上述投资人和田梦怡都认为,价格战的玩家都是在用降价来换市场空间。用大模型客户撬动公有云业务虽然是未来,但是要先保证自己在餐桌旁,否则就在餐桌上了。
对于客户来讲,打折的大模型固然诱人,但模型性能仍是决定购买的关键。
Max是一家AI教育创业团队的联合创始人,该团队致力于构建学习能力分析模型,从而提供更加个性化、数据驱动的教育服务。在谈及团队的选购标准时,他表示,会先看模型能不能完成场景任务,然后才会横向对比价格、稳定性,最终选出一个性价比最高的产品。
但API作为开发过程中的一项大额开支,降价确实能帮助开发者以更低成本构建应用。“降价的吸引力确实很大,它给很多过去难以达成盈利的项目带来了机会。”Max坦言。
Max的团队在API价格调整后,也享受到了实实在在的好处。在价格调整之前,他们每月调用GPT的成本在一万元左右。但随着价格的降低,他们转而使用了智谱的GLM和DeepSeek的服务。即便他们的调用量有所增加,整体成本却下降了30%。
目前来看,价格的下降暂时还没有刹车的迹象。上述投资人判断,不管是从技术还是从市场看,降价都是可持续的,并且不好说“底”在哪里。
正如滴滴和快的通过合并结束了烧钱的补贴战,美团也以其创新和激进的市场策略在团购大战中崭露头角。大模型行业的价格战可能会一直持续下去,直到某个突破性的杀手级应用或场景出现,才能宣告结束。
在这一决定性的时刻到来之前,不断转动的车轮下,将有无数企业被市场淘汰。
(文中受访者均为化名)
本文来自微信公众号:镜相工作室(ID:shangyejingxiang),作者:赵一帆,制图:阮怡玲,编辑:卢枕