前 言
5月14日,OpenAI 的发布会又深夜炸场了,每一次的发布,确实都能给我们带来很大的震撼。在模型每半年一次大升级的前提下,如何思考、设计未来的应用架构,尤其是 Agent 的架构至关重要。
从接触到 ChatGPT 到躬身入局开发 DB-GPT(开源的 AI 原生数据应用开发框架) 项目也已经一年有余,在最近我们的能力逐步开始规模化应用之际,正好也来谈谈我们在这一段时间的探索与思考。大模型带来的智能化革命,不仅打开了专业技术走向大众普惠的大门。同时 Transformer(变形金刚),将天门劈开了一条裂缝,让我们看到了曙光。开启了新一轮的技术竞赛与科技角逐。
如果说去年我们还在关注算力的比拼,那其实走到现在。已经逐渐演变成体力、心力、定力、毅力的竞争。我相信大家都已经看到了,最近国内的模型 Qwen2.5 与 DeepSeek V2 已经表现出了 GPT-4 同级别的表现力,并且在推理成本上 DeepSeek V2 只有 GPT-4 的百分之一。随着成本指数级别的骤降,以及更多人逐渐掌握这项革命性的技术,规模化的落地应用也逐渐出现在了我们的视野。
最近业务领域的应用,也是层出不穷,不仅各大模型厂商推出了自己的大模型应用 APP,之前的传统 APP 也都集成了 AI 的能力, 尤其支付宝智能助手的发布,预示着以大模型为核心技术的 AI 应用,开始逐步渗透到每个人的生活当中。
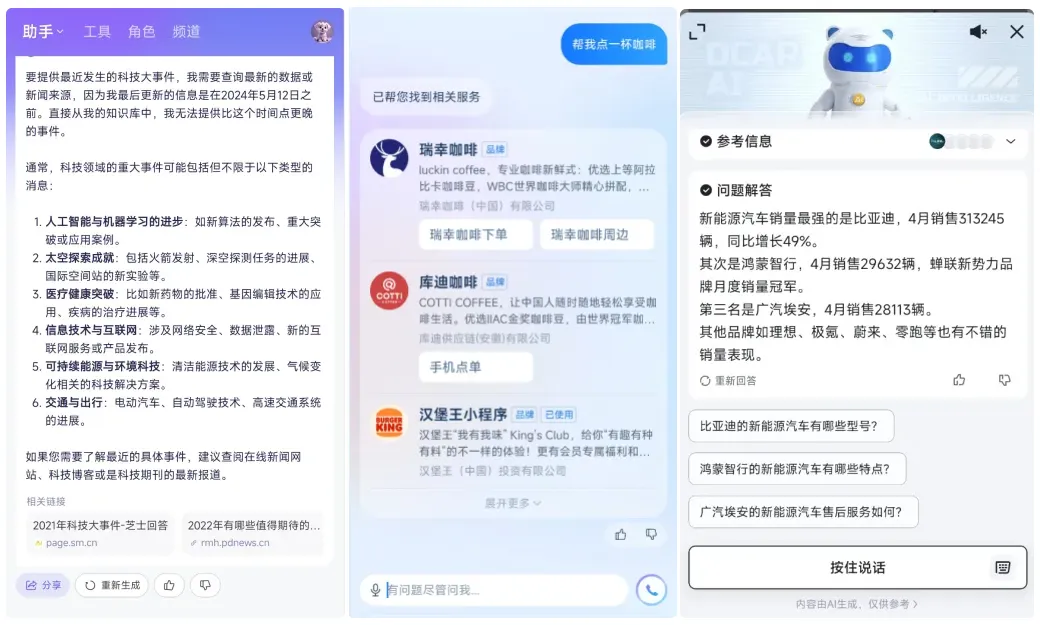
但饶是如此,截止目前应用层面尚未出现让人持续心动的现象级产品。可能一方面来讲,确实大模型技术从 ChatGPT 出现到今天也仅仅只有一年半时间,我们需要给新的产品一点耐心。但另一方面来讲,这个时代以 Copilot 为重心的业务场景落地,更适合锦上添花。毕竟就目前这一代人在经历过互联网产品的投喂之后,单单搞出点有用高效的东西,已经很难戳中他们的嗨点了。所以要出现现象级的产品,还一定得要有趣、好玩。
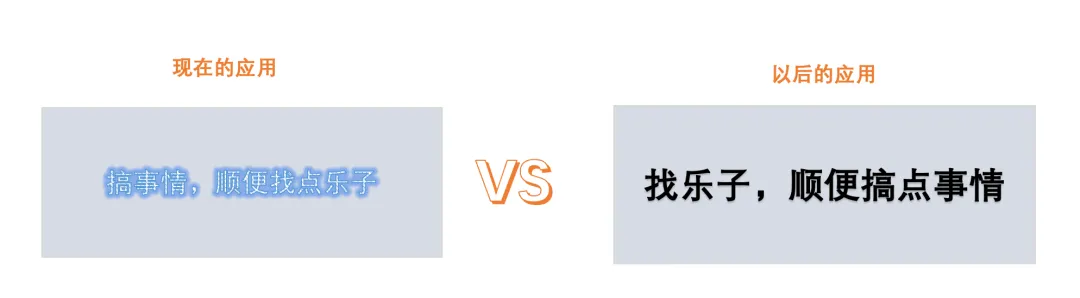
所以,以前的应用构建逻辑跟以后的会出现很大的不同。以前的应用是我办个事情,顺便玩个游戏。以后的应用大概率都会是找乐子的时候把事给办了。当前最典型的就是正刷着抖音,然后顺手下单购个物。
Agent 架构
特别说明: 本文中绝大多数对 Agent 的思想与构建都来自《A survey on large language model based autonomous agents》这篇综述文章,我们对里面的一些理念做了工程实现与落地应用。
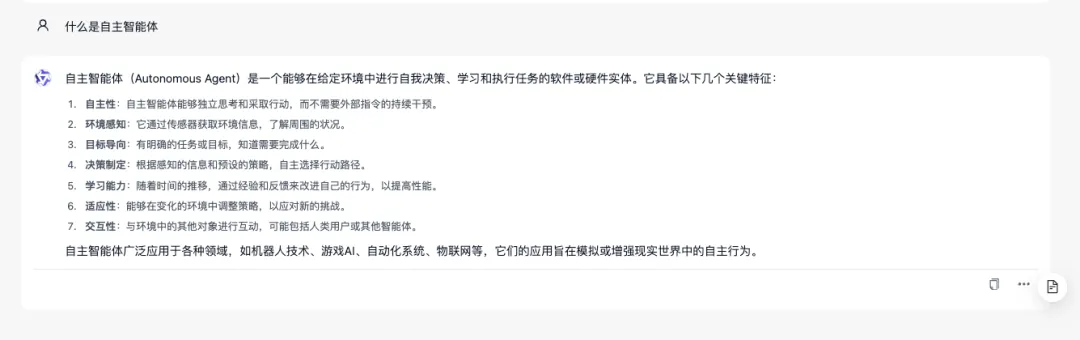
我们言归正传,今天我们要讲的是 Agent(智能体),更准确的说,是自主智能体。Agent 跟 Copilot 这两个词相信大家都不陌生了,这一年多的时间里面有非常多的相关产品与技术的演进与讲解,在这里我再从架构思考、源码实现、应用以及遇到的挑战出发,将我们对智能体思考与探索做一个分享。
其实早在我们的 DB-GPT 开源项目中,也在年初发布了相关的能力 (DB-GPT V0.5.0 发布—通过工作流与智能体开发原生数据应用)。但由于最近一直聚焦在业务落地探索,所以直到今天才抽出时间做一个系统的总结。
什么是自主智能体?
An autonomous agent is a system situated within and a part of an environment that senses that environment and acts on it, over time, in pursuit of its own agenda and so as to effect what it senses in the future.
---- Franklin and Graesser (1997)
智能体发展现状
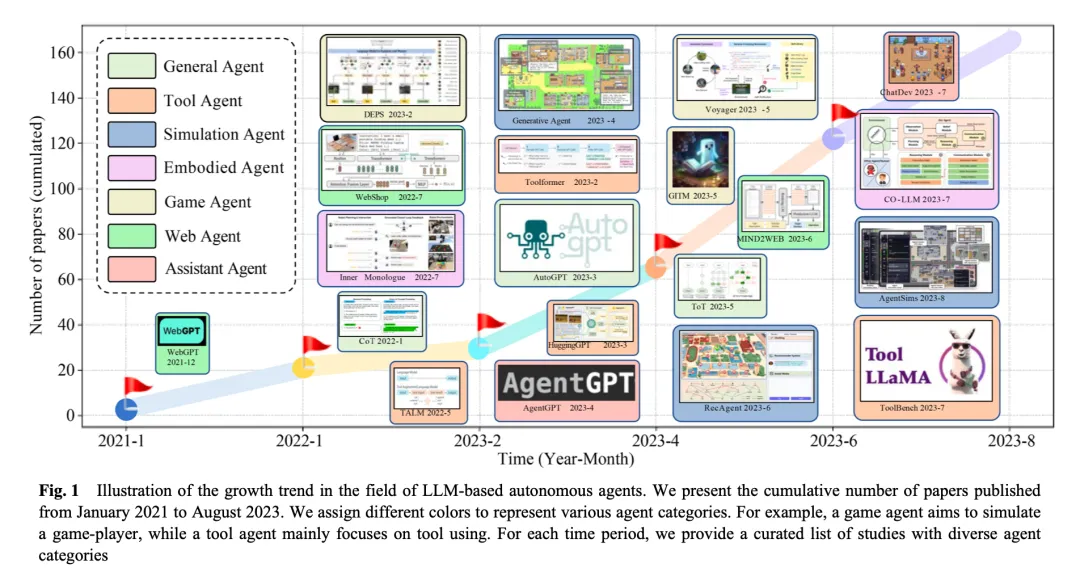
在大模型出现之前,智能体的研究主要用来扮演策略函数,解决一些具体场景中的问题,并且一般都是在隔离的环境中进行。直到大模型发布,智能体开始出现井喷式爆发发展。尤其在 2023 年随着 AutoGPT、BabyAGI、MetaGPT、ChatDev、AutoGen 等开发框架的出现,智能体的研究与应用浪潮被推到了一个崭新的高度。今天,智能体被认为是实现通用人工智能 (AGI) 的一种最具潜力的方案,已经在技术圈形成了一定的共识。但对于构建 Agent 与大规模应用来讲,还有很长的路要走,因为 Agent 的构建需要像人一样,需要具备持续自我进化的能力。为了弥补 LLM 和自主智能体之间的差距,一个关键的步骤是设计 Agent 的架构来缩小大语言模型与人类的差距。沿着这个思路,先前的开发者们已经开发了很多模块化的工具来弥补这些工作,典型的如 Langchain、Llama-index 等。但这些早期的框架主要是聚焦在工具链的使用,缺少从 Agent 架构层面系统的设计。
那么 Agent 的架构长什么样?需要具备哪些特性跟能力?
Agent 架构
经过对一系列的 Agent 框架与理论的研究,根据《A survey on large language model based autonomous agents》智能体综述文章我们总结出 Agent 核心具备的几个核心特性与模块。
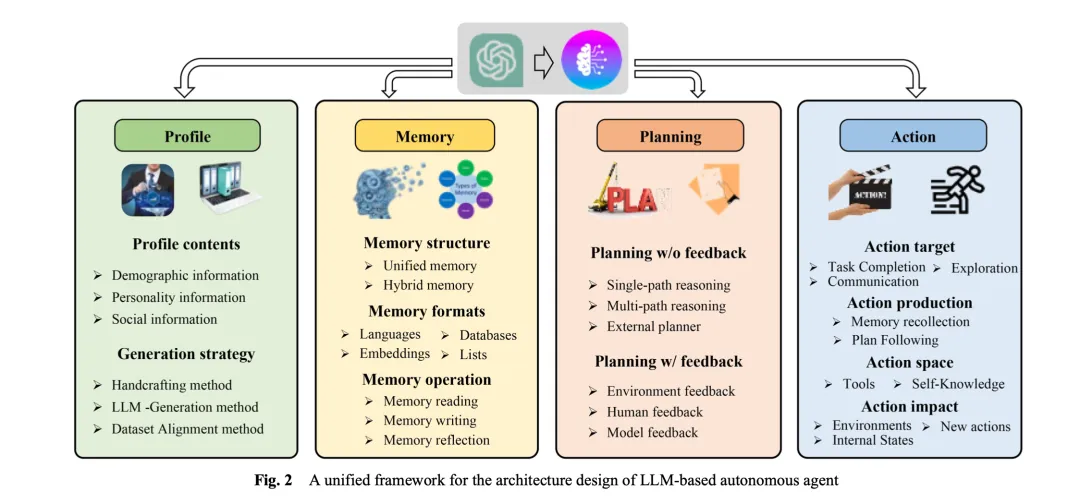
Profile 模块: Profile 模块,Profile 模块的目的主要是做 Agent 角色认定,回答的核心问题有: 我是谁?我在哪?我该干什么?无论是在当前的人与人之间的协同,还是人与智能体的协同,亦或是智能体与智能体间的协同。
Memory 模块: Memory 即记忆模块,主要用来存储、获取、检索信息。
Planning 模块: 制定计划,可以根据过去的行为与目标动态规划下一步的行动
Action 模块: 执行模块,执行智能体的具体决策。
Profile 模块
自主智能体通常是通过假定特殊的角色来进行解决问题。比如编程专家、老师、领域专家。Profile 模块目的就是设定智能体的角色,做角色认定。通常通过 Prompt 来进行指定,通过角色认定可以影响大模型的行为。智能体的 Profile 通常会说明其年龄、职业、心理、社会关系等信息。
角色认定是一种重要的社会和组织机制,通过明确个体在特定系统或环境中的地位和职责,有助于维护秩序、提升效率和促进合作。当然在实际应用中,描述代理信息取决于具体的业务场景。

下面是一个确认 Profile 的例子, 主要分为以下几个方面:
命名,即每个智能体都有一个名称作为代号,如 Visionary
角色, 设定智能体的角色定义,比如 Reporter
目标, 设定智能体的目标: Read the provided historical messages, collect various analysis SQLs, from them, and assemble them into professional reports.
性格、社会关系等约束条件设定。You are only responsible for collecting and sorting out the analysis SQL that already exists in historical messages, and do not generate any analysis sql yourself. etc
profile: ProfileConfig = ProfileConfig( name=DynConfig( "Visionary", category="agent", key="dbgpt_agent_expand_dashboard_assistant_agent_profile_name", ), role=DynConfig( "Reporter", category="agent", key="dbgpt_agent_expand_dashboard_assistant_agent_profile_role", ), goal=DynConfig( "Read the provided historical messages, collect various analysis SQLs " "from them, and assemble them into professional reports.", category="agent", key="dbgpt_agent_expand_dashboard_assistant_agent_profile_goal", ), constraints=DynConfig( [ "You are only responsible for collecting and sorting out the analysis " "SQL that already exists in historical messages, and do not generate " "any analysis sql yourself.", "In order to build a report with rich display types, you can " "appropriately adjust the display type of the charts you collect so " "that you can build a better report. Of course, you can choose from " "the following available display types: {{ display_type }}", "Please read and completely collect all analysis sql in the " "historical conversation, and do not omit or modify the content of " "the analysis sql.", ], category="agent", key="dbgpt_agent_expand_dashboard_assistant_agent_profile_constraints", ), desc=DynConfig( "Observe and organize various analysis results and construct " "professional reports", category="agent", key="dbgpt_agent_expand_dashboard_assistant_agent_profile_desc", ),)
当然完成上述工作才是自主 Agent 构建的开始,后续我们需要持续给 Agent 构建档案,让其具备完整的"人格"与角色认定。为什么一定要构建档案与角色认定,大家不妨回顾一下。我们人类的培养与成长,伴随一生的一个核心命题就是做角色认定,而档案是角色认定非常重要的一环。档案的构建是一个持续的过程,一般会用到如下一些方法:
手工制作法: eg: "你是一个外向的人","你是一个数据库专家"。
大模型生成法: 给定一些关键词,让大模型辅助生成。
数据集对齐法: 在这种方法下,智能体的 Profile 通过真实世界的数据集来持续构建。
Memory 模块图片

Memory 模块在 Agent 架构中,扮演非常重要的角色。它存储环境以及先前对话记忆,并指导下一步的行动。记忆模块可以帮助智能体积累经验,自进化,变成一个更一致、更具逻辑、更高效的"人"。
下面我们从记忆模块结构、格式以及操作几个层面介绍。
记忆结构: 基于大模型的自主代理通常结合源自人类记忆过程,基于人类对认知科学研究的原理和机制。
人类记忆遵循从纪录知觉输出的感觉——短期记忆,在到长期信息巩固的长期记忆。
短期记忆: 受限于大语言模型上下文窗口的制约。
长期记忆:类似于外部向量存储,智能体可以根据需要快速查询和检索。
Unified Memory: 类似人类的短期记忆,,通常通过上下文来学习,一般直接写在 Prompt 里面。
Hybrid Memory: 混合记忆基于人类的短期记忆和长期记忆进行建模。短期记忆纪录最近的信息,长期记忆纪录整个生命周期里面最重要的信息。比如短期记忆包括 Agent 当前情况下上下文的信息,长期记忆存储过去的行为和思考,长期记忆可以通过当前的事件进行检索。
记忆格式: 自然语言记忆与 Embedding 记忆
自然语言:在这种格式下,记忆直接通过自然语言描述。
Embedding: 在这种格式下,记忆直接通过 Embedding 向量来存储。
数据库:记忆信息被存储在数据库中,允许智能体更高效、全面操纵记忆。
链式结构:链表、树
记忆操作: 记忆模块通过与环境的交互来获取、积累、利用重要知识。
记忆读: 从记忆中抽取有用的信息。抽取维度有 Recent、Relevance、Importance
记忆写: 将感知环境的信息写入到记忆存储中。
记忆反思:记忆反思模仿人类见证评估自己认知、情感和行为过程的能力。
Planning 模块
当面临复杂任务时,人类倾向于将其构造为简单的子任务并且独立进行解决。计划模块的目的是通过类人的能力,让 Agent 的行为更具逻辑性、更强大、更可信。我们可以根据是否需要人类反馈对计划过程进行分析。
没有反馈的计划制定
在此方法中,agent 不会接收反馈对未来的行动做出调整。
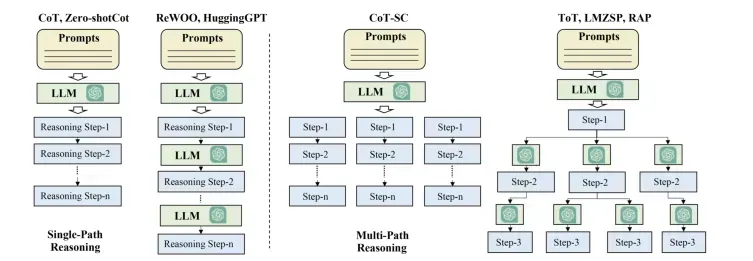
单路径推理: 此策略中,最终的任务被分解为几个步骤,这些步骤被级链方式进行连接。每一步只有一个子步骤,LLM 遵循这些步骤完成最终的目标。

多路径推理:此方法中,推理步骤生成的最终计划是一棵数结构,其中每一步可能会有多个子步骤,这个方法类似于人类的思考,在每一步上会有多个选择。CoT(Chain Of Thoughts 认为每个复杂问题都有多种思维方式来推导出最终答案。因此通过 CoT 的方式生成一系列的推理步骤。多路径推理中常用的方法有 CoT(Chain Of Thoughts)、ToT(Tree Of Thoughts)、GoT(Graph Of Thoughts)、AoT(Algorithm of thoughts) 等。在每个步骤中,他们首先生成多个可能的后续步骤,然后根据可接收的行动的距离来确定最终步骤。
有反馈的计划制定
在许多真实场景中,Agent 需要制定长远的计划解决复杂问题。面对这些任务时,没有反馈的计划模块由于下面的原因很难制定正确的计划。
首先从一开始制定一个完美的计划非常困难,因为它需要各种复杂的前提条件,所以仅仅简单遵循初始计划大概率会导致失败。
计划的执行也会遇到非预期的行为与输出。
外部真实环境与人类的反馈能够及时纠正 Agent 可能的犯错。
Action 模块
Action 模块负责将智能体的决策转化为具体的结果。该模块一般直接与环境交互。会受到 profile、memory 和计划模块的影响。
Action 的目标:动作的意图?
完成任务
交流
环境探测
Action 的生成:Action 是如何生成的?
通过记忆,该 Action 是通过从 Memory 中抽取信息来生成的。
通过计划遵循
Action 的行动空间:哪些 action 可用?
拓展工具: APIs、Database & KBQA、拓展模型
LLMs 内在知识
基于预训练的知识,LLMs 本身具备规划能力
Action 的影响: -> before action, in-action, after-action
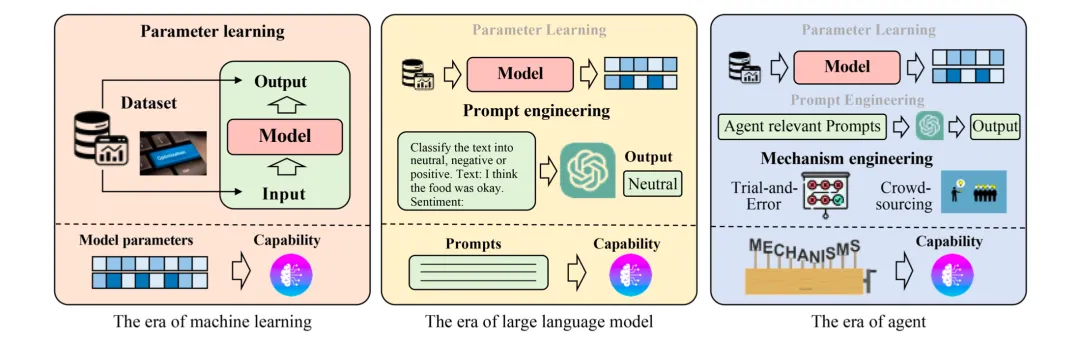
Agent 能力的获取
通过微调 (Capability acquisition with fine-tuning)
Prompt 工程
设计适当的 agent 进化机制. (机制工程)
反复试验
群众智慧
经验积累
自我驱动进化
编排与 AWEL(Agentic Workflow Expression Language)
为什么需要编排?

大语言模型已经在特定领域具备了生成有效计划的能力,为什么还需要编排?在技术理念上,我们认为智能体的应用主要有两种场景。1. 比较开放性的问题,比如制定一个旅行计划,这类问题的编排可以用智能体 AutoPlan 2. 但绝大多数场景是有固定流水线的,尤其在工业尤为明显。这类确定性的领域,需要有智能体的确定性编排。
此外计划与编排是人类协作与管理的基础。智能体要参与到人类生产、生活当中,必然需要遵循人类社会的规则, 需要有一套统一的架构管理编排。

什么是 AWEL(智能体编排语言)?
AWEL(Agentic Workflow Expression Language)是一套专为大模型应用开发设计的智能体工作流表达语言,它提供了强大的功能和灵活性。AWEL 通过设计标准输入、输出来定义 Agent 之间的交互协议,通过编排让 Agent 之间的协作更加高效。
通过 AWEL API 您可以专注于大模型应用业务逻辑的开发,而不需要关注繁琐的模型和环境细节,AWEL 采用分层 API 的设计, AWEL 的分层 API 设计架构如下图所示:
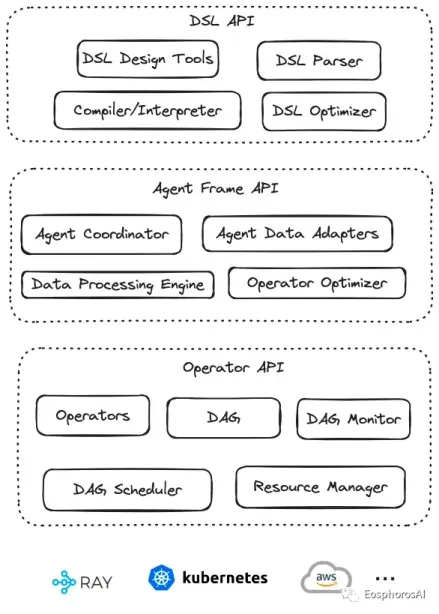
AWEL 分层设计
AWEL 在设计上分为三个层次,依次为算子层、AgentFrame 层以及 DSL 层,以下对三个层次做简要介绍。
算子层
算子层是指 LLM 应用开发过程中一个个最基本的操作原子,比如在一个 RAG 应用开发时。检索、向量化、模型交互、Prompt 处理等都是一个个基础算子。在后续的发展中,框架会进一步对算子进行抽象与标准化设计。可以根据标准 API 快速实现一组算子。
AgentFrame 层
AgentFrame 层将算子做进一步封装,可以基于算子做链式计算。这一层链式计算也支持分布式,支持如 filter、join、map、reduce 等一套链式计算操作。后续也将支持更多的计算逻辑。
DSL 层
DSL 层提供一套标准的结构化表示语言,可以通过写 DSL 语句完成 AgentFrame 与算子的操作,让围绕数据编写大模型应用更具确定性,避免通过自然语言编写的不确定性,使得围绕数据与大模型的应用编程变为确定性应用编程。
Agent 在 DB-GPT 项目中的定位
如下图所示, 在 DB-GPT 项目中,Agent 是一等公民。其他如 SMMF(多模型管理)、RAGs、数据源、插件、工具、可视化组件等都是 Agent 所依赖的资源。
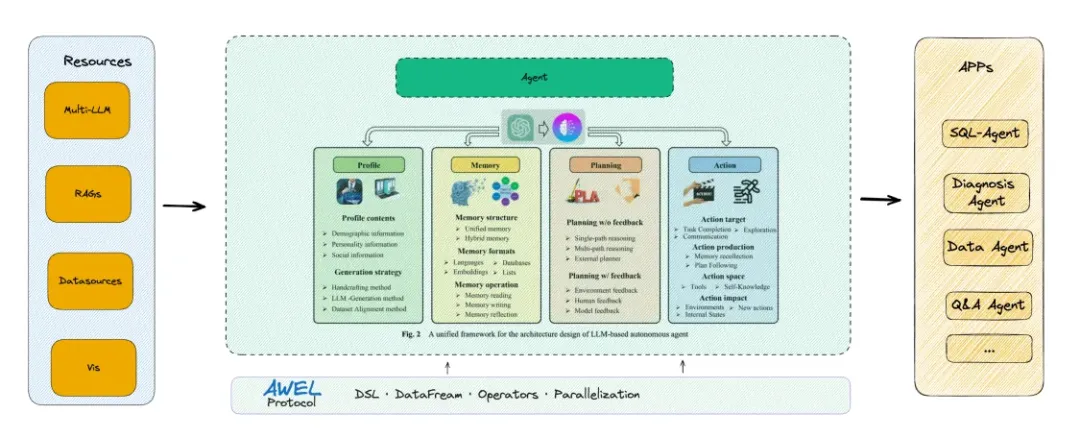
Agent 代码实现
针对上述描述的 Agent 架构,我们在 DB-GPT 开源项目中,做了完整的实现。具体的代码实现路径在 dbgpt/agent 包里面。接下来我们对源码做个简要的介绍。
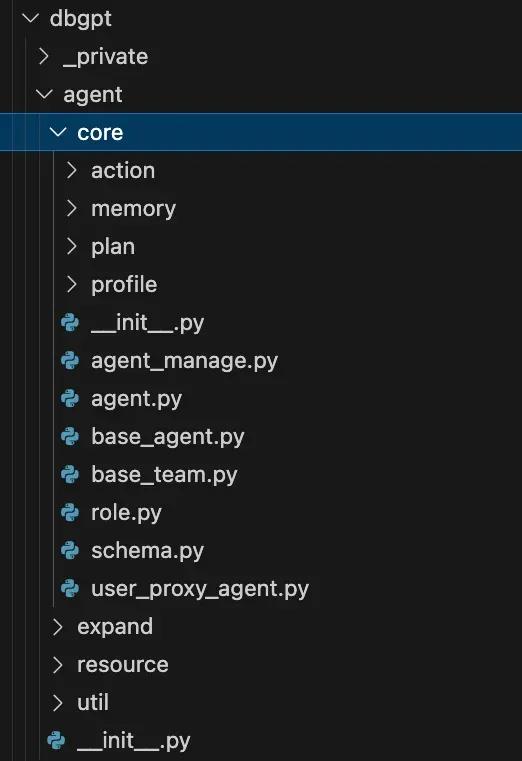
如图所示,为整个 Agent 的代码目录组织, 其中 core 包里面包含了我们前面提到的 Agent 的所有核心模块,包括 profile、memory、plan、action 等模块。
resource 目录下主要实现了一组资源加载逻辑,可以将 DB-GPT 中提供的模型、RAGs、数据源和工具等资源无缝加载到 Agent 中提供使用。
expand 包下面主要是具体的 Agent 的实现,DB-GPT 默认内置了代码助手、数据分析助手、SQL 助手、插件助手、图表助手、知识库助手等智能体。
Agent 定义
在 Core 包下 agent.py 文件中,对 Agent 做的接口做了定义与抽象。一个 Agent 主要包含以下核心方法:
Agent: 基类,用来表征 Agent
send: 发送消息
receive: 接收消息
generate_reply: 生成响应
thinking: 思考 & 反思
review: 结果审查
act: 执行
verify: 校验
name: 名称
role: 角色认定
desc: 描述
AgentContext:Agent 依赖的上下文
AgentGenerateContext: Agent 依赖的上下文
AgentReviewInfo: Agent 审查信息
AgentMessage: Agent 消息处理
AgentManage: 对 Agent 进行管理,主要是 Agent 的注册与发现。
base_agent.py 文件中实现了 ConversableAgent,ConversableAgent 继承了 Agent、Role 两个父类,并对通用方法做了实现。后续在具体 Agent 实现上,可以直接继承 ConversableAgent
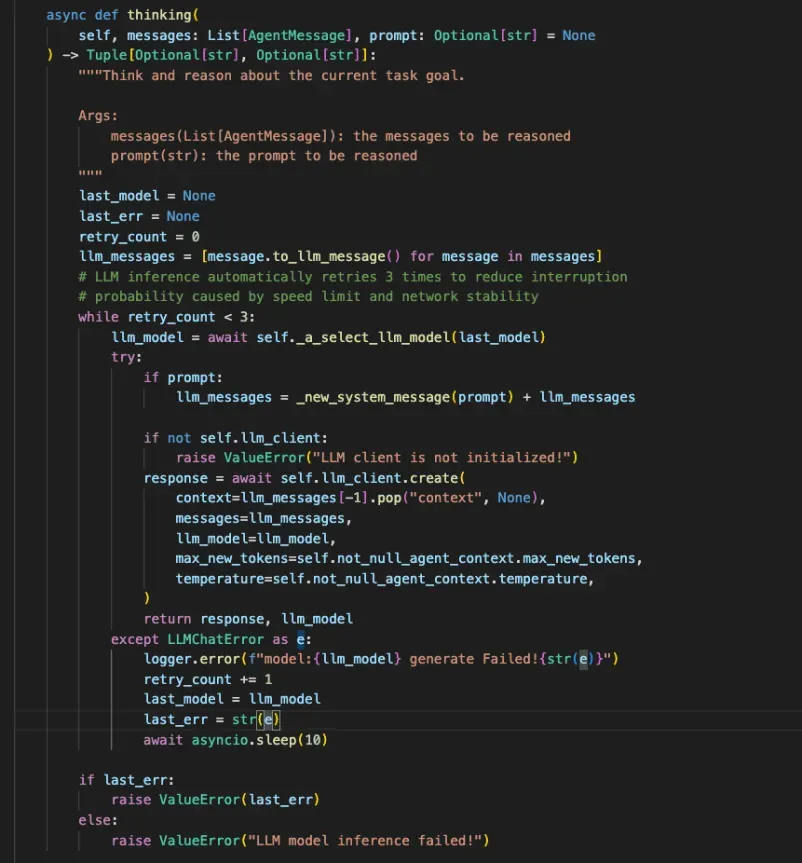
Thinking 方法
Thinking 方法基于历史的消息与记忆来推理完成当前目标需要做的具体行动,会根据上一次执行的错误信息进行反思重试,一般会重试 3 次。
资源 bind
bind 方法会绑定 Agent 所依赖的资源,包括模型、记忆、知识库、插件、数据源和工具等。

Agent 构建
build 方法会完成一个 Agent 的构建工作,会前置检查 Agent 的可用性,并做资源的预加载与初始化。
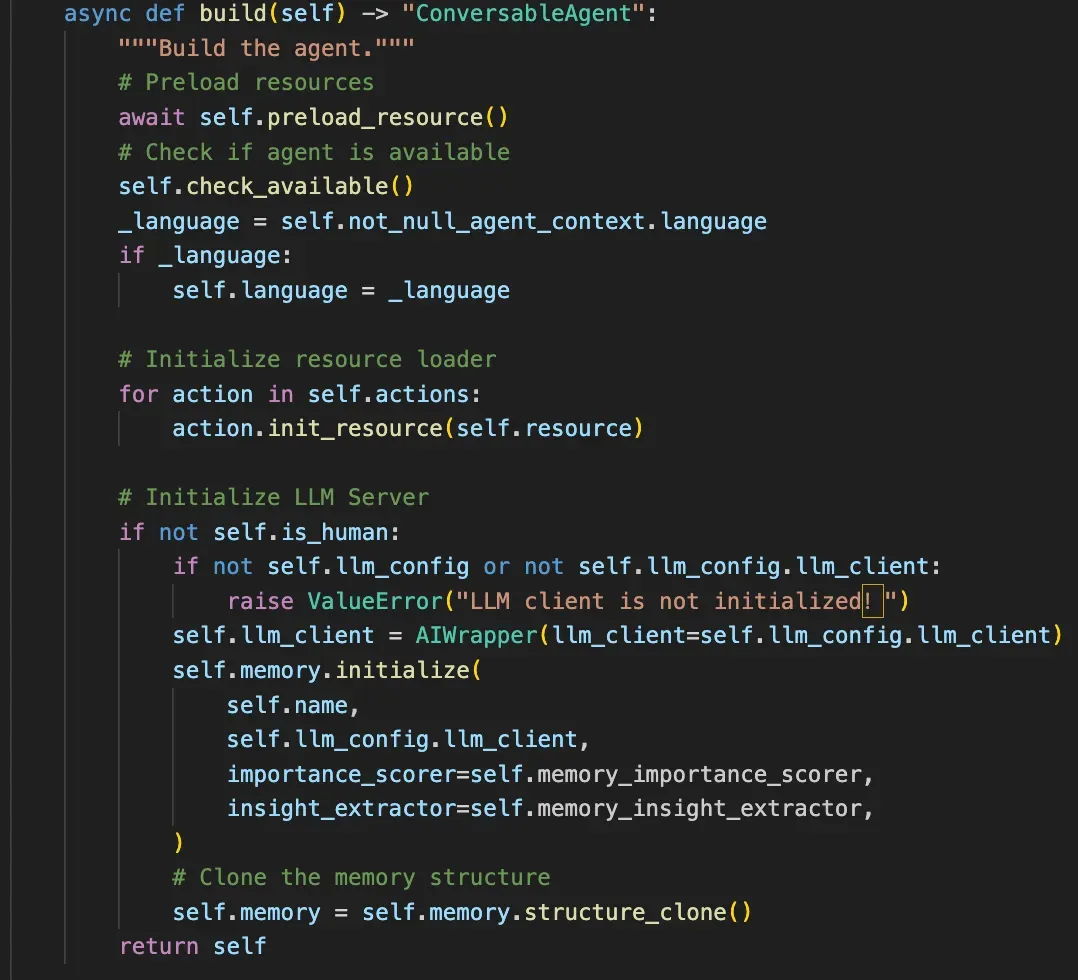
Profile
Profile 核心是做 Agent 的角色认定,所以在实现上比较简洁。重心是如何持续围绕大模型构建好 Prompt 以及 Agent 档案。
VALID_TEMPLATE_KEYS = { "role", "name", "goal", "resource_prompt", "expand_prompt", "language", "constraints", "examples", "out_schema", "most_recent_memories", "question",}
_DEFAULT_SYSTEM_TEMPLATE = """You are a {{ role }}, {% if name %}named {{ name }}, {% endif %}your goal is {{ goal }}.Please think step by step to achieve the goal. You can use the resources given below. At the same time, please strictly abide by the constraints and specifications in IMPORTANT REMINDER.{% if resource_prompt %} {{ resource_prompt }} {% endif %}{% if expand_prompt %} {{ expand_prompt }} {% endif %}
*** IMPORTANT REMINDER ***{% if language == 'zh' %}Please answer in simplified Chinese.{% else %}Please answer in English.{% endif %}
{% if constraints %}{% for constraint in constraints %}{{ loop.index }}. {{ constraint }}{% endfor %}{% endif %}
{% if examples %}You can refer to the following examples:{{ examples }}{% endif %}
{% if out_schema %} {{ out_schema }} {% endif %}""" # noqa
_DEFAULT_USER_TEMPLATE = """{% if most_recent_memories %}Most recent observations:{{ most_recent_memories }}{% endif %}
{% if question %}Question: {{ question }}{% endif %}"""
_DEFAULT_SAVE_MEMORY_TEMPLATE = """{% if question %}Question: {{ question }} {% endif %}{% if thought %}Thought: {{ thought }} {% endif %}{% if action %}Action: {{ action }} {% endif %}{% if observation %}Observation: {{ observation }} {% endif %}"""
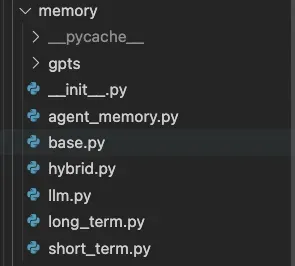
Memory
如下图目录结构所示,Memory 模块里面,我们实现了前面提到的短记忆、长记忆、混合记忆等多种方式。同时也实现了 Memory 的核心操作接口,比如存储、读、写、裁剪、清理、重要性计算等。
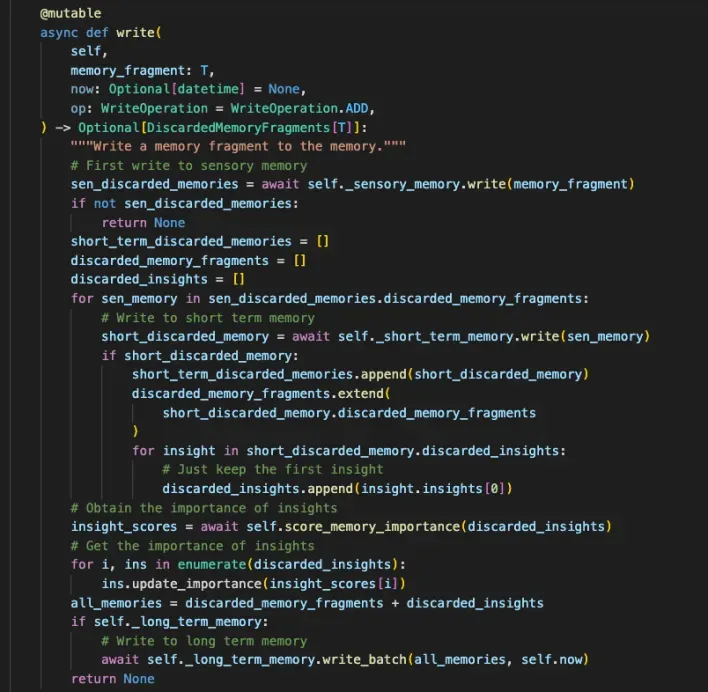
写混合 Memory
这里我们以混合记忆为例,介绍一下记忆的读写操作,如下图所示是写的过程。
首先会将感知记忆写入到存储当中,然后获取并写短期记忆,最后写长期记忆。在这个过程中,会同时更新记忆的重要性指标。
读混合记忆
读的过程也类似,首先读长期记忆,然后读短期记忆。
Planning
计划与编排,主要实现了三种方式的编排。
single_agent,即完成单一的目标。
auto-plan: 根据一个目标进行拆分,然后分发给多 Agent 协作完成。
AWEL: 基于工作流的人为编排。
Action
Action 是一个智能体决策的具体执行,一般需要根据具体的场景来进行具体实现。代码中我们定义了通用的接口与方法,结合场景的实现需要根据实际情况进行编写。
实现案例
这里我们来介绍一个简单的 SQL-Agent 的实现,主要具备根据 RAG + 数据源 + Text2SQL 能力实现 SQL 生成、翻译、优化等工作。
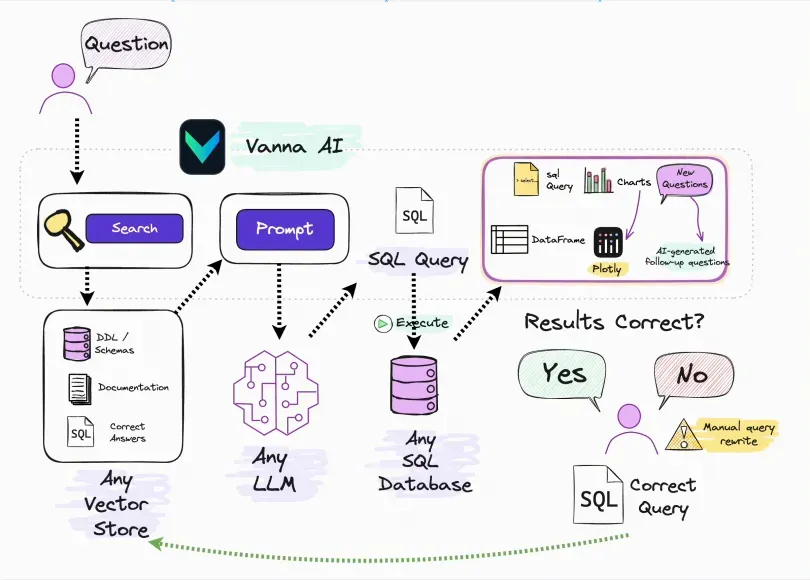
实现数据 SQL-Agent
这里我们实现了一个简单的 SQL 助手,由于我们的目的主要是 SQL 生成、翻译、优化,所以我们制定的 Action 是一个空 Action.
"""SQL Assistant Agent.
Use RAG and Schema-Linking, which can generate,translate,
and correct SQL based on user questions.
"""
import asyncio
from dbgpt.agent import BlankAction, ConversableAgent, DynConfig, ProfileConfig
class SQLAssistantAgent(ConversableAgent):
"""SQL Agent Use RAG and Schema-Linking."""
profile: ProfileConfig = ProfileConfig(
name=DynConfig(
"kevin",
category="agent",
key="dbgpt_agent_expand_sql_expert_name",
),
role=DynConfig(
"SQLExpert", category="agent", key="dbgpt_agent_expand_sql_expert_name_role"
),
goal=DynConfig(
"SQL generation, SQL translate, SQL diagnostics",
category="agent",
key="dbgpt_agent_expand_sql_expert_name_goal",
),
constraints=DynConfig(
[
"""You are a SQL expert who can generate, translate,
and correct SQL based on user questions.
If the user's input is not related to SQL,
you need to prompt the user to output SQL-related content."""
],
category="agent",
key="dbgpt_agent_expand_sql_expert_profile_constraints",
),
desc=DynConfig(
"""You are a SQL expert who can generate, translate,
and correct SQL based on user questions.""",
category="agent",
key="dbgpt_agent_expand_sql_expert_profile_desc",
),
)
def __init__(self, **kwargs):
"""Create a new SQLAssistantAgent."""
super().__init__(**kwargs)
self._init_actions([BlankAction])
SQL Agent 还需要一个数据库连接作为依赖的资源,这里我们创建一个 SQLite 表:
def _create_temporary_connector():"""Create a temporary database connector for testing."""from dbgpt.datasource.rdbms.conn_sqlite import SQLiteTempConnector
connector = SQLiteTempConnector.create_temporary_db()
connector.create_temp_tables(
{
"user": {
"columns": {
"id": "INTEGER PRIMARY KEY",
"name": "TEXT",
"age": "INTEGER",
},
"data": [
(1, "Tom", 10),
(2, "Jerry", 16),
(3, "Jack", 18),
(4, "Alice", 20),
(5, "Bob", 22),
],
}
}
)
return connector
构建 Agent,绑定资源并做初始化。
async def main():
from dbgpt.agent import AgentContext, AgentMemory, UserProxyAgent, LLMConfig
from dbgpt.agent.resource import RDBMSConnectorResource
from dbgpt.model.proxy import OpenAILLMClient
agent_memory = AgentMemory()
llm_client = OpenAILLMClient(model_alias="gpt-3.5-turbo")
context: AgentContext = AgentContext(conv_id="sql_agent")
connector = _create_temporary_connector()
sqlite_resource = RDBMSConnectorResource("SQLite Database", connector=connector)
user_proxy = await UserProxyAgent().bind(agent_memory).bind(context).build()
sql_agent = (
await SQLAssistantAgent()
.bind(context)
.bind(LLMConfig(llm_client=llm_client))
.bind(sqlite_resource)
.bind(agent_memory)
.build()
)
await user_proxy.initiate_chat(
recipient=sql_agent,
reviewer=user_proxy,
message="What is the name and age of the user with age less than 18",
)
print(await agent_memory.gpts_memory.one_chat_completions("sql_agent"))
if __name__ == "__main__":
asyncio.run(main())
本 Agent 中,我们准备了两类资源。1. 知识库 2. 数据库。知识库里面主要对一些字段与上下文进行描述。

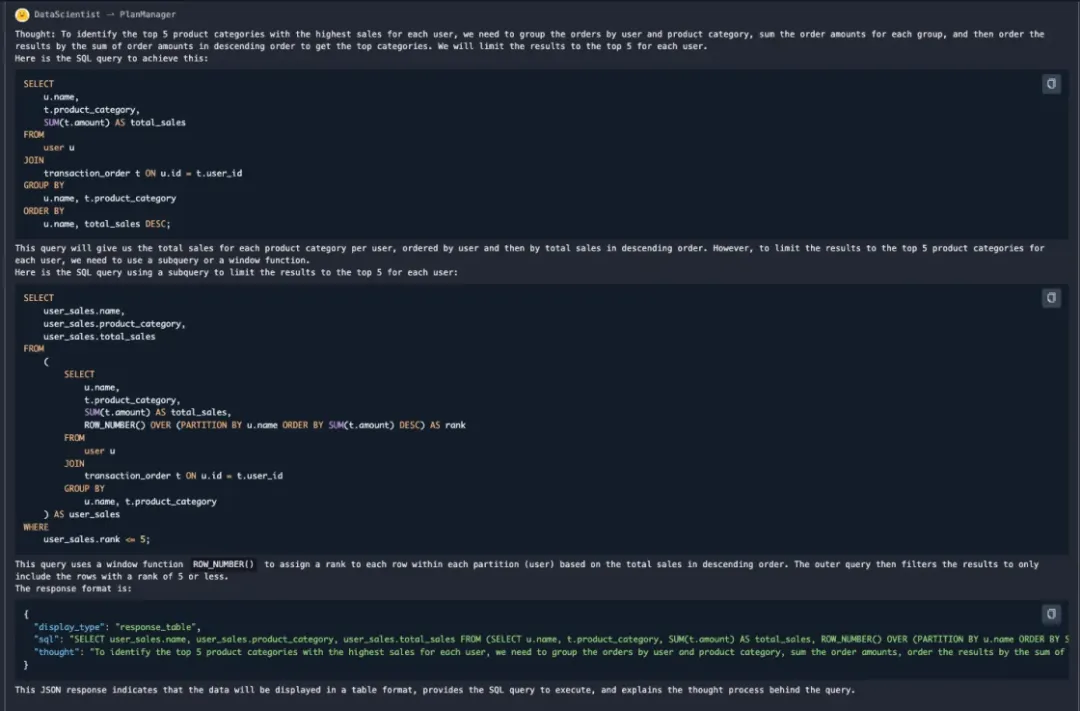
更多关于 Agent 的教程,正在更新中,敬请期待。
Agent 应用与挑战
在 Agent 的应用方面,我们主要聚焦在数据基础设施、数据分析与基础设施运维等领域。涉及的 Agent 主要有智能问答 Agent、SQL-Agent、数据分析 Agent、诊断 Agent、风险分析 Agent、运维 Agent 等场景。当然也包括一些完全基于 Multi-Agent Auto-plan 的智能体实现。
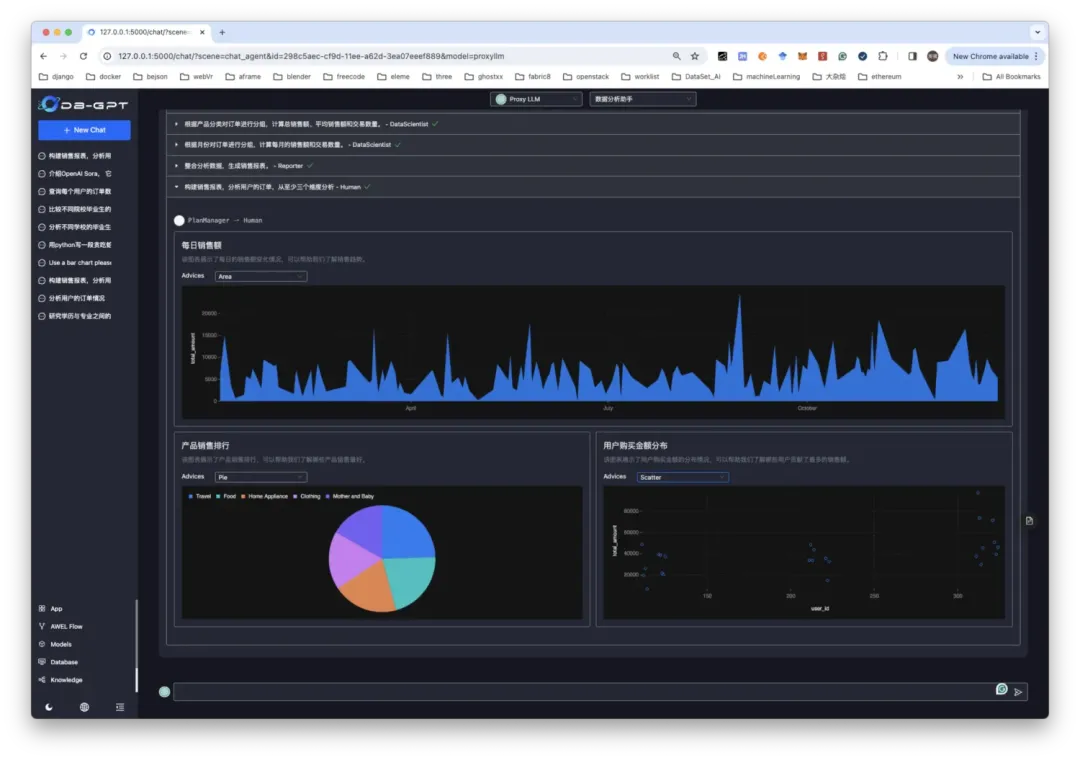
有很多有趣的尝试,但也遇到非常多的挑战。包括但不限于
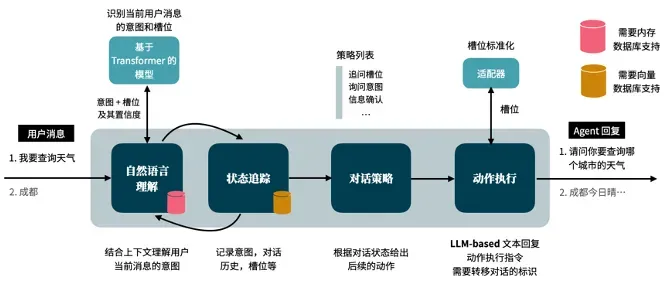
意图识别: 如何准确理解用户的意图,并匹配到对应的 Agent
Agent-Linking: 多 Agent 如何提供一个统一的入口,回答多个领域专业问题的同时,还可以自由对话。如一个对话智能体 Kevin 后面,可以进行多种任务对话,比如智能问答,SQL- 生成、诊断、运维 &API 调用、自由对话等。
召回准确率:如何准备高质量的问答与知识库,结合多种 RAG 检索技术,准确召回相关内容。
多轮对话进行参数补充: 比如在意图识别中,用户单次的对话无法满足场景的参数需求,需要智能体反问用户达到槽位填充的目的。

Agent 评测
Agent 的评估分为两种方式。1. 主观评估 2. 客观评估
主观评估
主观评估 Agent 能力主要是基于人类的判断。一般适用于没有评测数据集或者很难设计高质量的指标的场景。比如说评估 Agent 的智力与用户友好性。下面我们介绍两种普通的主观评估策略
人工标注: 与人类的直接评分和排序相关。
图灵测试
因为自主 Agent 是被人类设计满足人类需求的,因此人类的主观测试非常重要。同时也会面临非常多的问题,比如高成本、低效、偏见。为了解决这些问题,越来越多的研究人员正在研究试用 LLM 本身进行主观评价。
客观评估
评估指标
协议
benchmarks
指标
任务成功率指标
人类相似度指标
效率指标
协议 &Benchmarks
真实世界的评估
社会评估
多任务评估:人类使用一组来自不同领域的任务来进行评估。
软件测试
小 结
随着模型效果越来越强,自主智能体的实现越来越成为可能。但是面向未来,随着模型效果每半年一次的大迭代,设计 Agent 架构以及构建 Agent 应用时,需要充分考虑 Agent 进化与迭代的机制。同时,虽然当下在 Agent 的构建中,大家更多关注的是 Plan,但角色认定、长期记忆等在人类交互中最基本的要求,或许应该花更多的精力。另外,当下关于 Agent 开发的框架跟平台很多,但观察整个演变的趋势,很难由一套架构或者平台统一所有的应用。因此统一架构理念,设计合理的注册与交互协议,也是框架跟平台需要重点考虑的。
总之自主智能体这场冒险刚刚开始,对未来必然会面对的新物种,特别期望大家能够躬身入局,一起探索,一起尝试。
附录
https://link.springer.com/article/10.1007/s11704-024-40231-1
https://github.com/eosphoros-ai/DB-GPT
https://github.com/vanna-ai/vanna/blob/main/papers/ai-sql-accuracy-2023-08-17.md
https://openai.com/index/gpt-4o-and-more-tools-to-chatgpt-free/
意图识别 & 槽位填充(https://www.thoughtworks.com/zh-cn/insights/blog/machine-learning-and-ai/how-to-design-task-based-dialogue-Agent-with-LLM)
作者简介
陈发强(蚂蚁集团国际数据库负责人,LLM+DB Infra 负责人, DB-GPT 项目作者)